Grokking the Machine Learning Interview - Recommendation System (2) Metrics
Recommendation System
Grokking the Machine Learning Interview
Recommendation System (2) Metrics
추천 시스템의 성능을 판단하는 데 사용되는 온라인 및 오프라인 지표를 살펴본다.
- 측정항목(메트릭)유형
- 온라인 지표
참여율
시청한 동영상
세션 시청 시간 - 오프라인 측정항목
mAP @ N
mAR @ N
f1 score
평가 최적화를 위한 오프라인 지표
해당 포스팅에서는 영화/쇼 추천 시스템의 성능을 측정하는 데 사용할 수 있는 다양한 측정항목을 살펴본다.
Types of metrics (측정 항목 유형)
- 다른 최적화 문제와 마찬가지로 영화/프로그램 추천 시스템의 성공을 측정하는 두 가지 유형의 측정항목이 있다.
Online metrics(온라인 지표)
- 온라인 지표는 A/B 테스트 중 실시간 데이터에 대한 온라인 평가를 통해 시스템 성능을 확인하는 데 사용된다.
Offline metrics(오프라인 측정항목)
- 오프라인 측정항목은 프로덕션 환경에서 모델 성능을 시뮬레이션하는 오프라인 평가에 사용된다.
여러 모델을 훈련시키고 테스트할 수 있으며, 보유된 테스트 데이터(사용자가 추천된 미디어와 상호 작용한 기록)를 사용하여 오프라인으로 튜닝하고 테스트할 수 있다.
그 모델의 성능 향상이 프로덕션 환경으로 가져오기 위한 기술적 노력에 충분한 가치가 있다면, 가장 성능이 우수한 모델이 실시간 데이터에 대한 온라인 A/B 테스트를 위해 선택될 것이다.
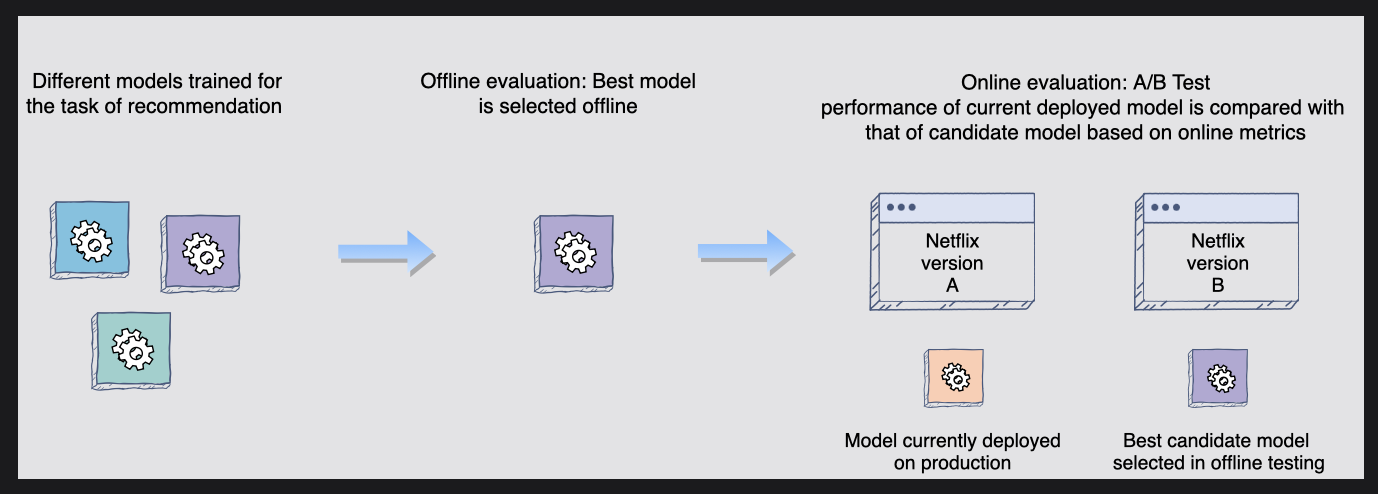
📝 모델이 오프라인 테스트에서는 좋은 성적을 거두었지만 온라인 테스트에서는 그렇지 못한 경우, 어디에서 문제가 발생했는지 생각해 볼 필요가 있다. 예를 들어, 데이터가 편향되었는지 또는 훈련과 테스트를 위해 데이터를 적절하게 분할했는지 고려해야 한다.
온라인 지표를 올바른 방향으로 유도하는 것이 추천 시스템의 궁극적인 목표이다.
Online metrics
시스템에 대해 제공되는 온라인 측정항목에 대한 몇 가지 옵션이다.
각각을 살펴보고 핵심 온라인 성공 지표로 사용하는 것이 가장 적합한지 논의해보자.
Engagement rate(참여율/반응율)
- 추천 시스템의 성공은 사용자가 참여하는 추천 수에 정비례한다.
따라서 참여율(클릭수가 발생한 세션 수/총 세션 수)을 측정하는 데 도움이 될 수 있다.
그러나 사용자는 추천 영화를 클릭했지만 시청을 완료할 만큼 흥미롭지 않을 수 있다.
따라서 추천을 통해 참여율을 측정하는 것만으로는 불완전하다.
Videos watched (시청한 영상)
- 영화/프로그램 추천에 대한 실패한 클릭을 고려하기 위해 사용자가 시청한 평균 비디오 수도 고려해야 한다. 사용자가 최소한 상당한 시간(예: 2분 이상)을 시청한 동영상만 계산해야 한다.
- 그러나 이 측정항목은 사용자가 추천 영화/시리즈를 보기 시작했지만 끝까지 볼 만큼 흥미롭지 않은 경우 문제가 될 수 있다.
- 시리즈에는 일반적으로 여러 시즌과 에피소드가 있으므로 한 에피소드를 시청한 다음 계속하지 않는 것도 사용자가 콘텐츠에 흥미를 느끼지 않는다는 의미이다.
따라서 시청한 평균 동영상 수를 측정하는 것만으로는 추천 콘텐츠에 대한 전반적인 사용자 만족도를 놓칠 수 있다.
세션 시청 시간(Session watch time)
- 세션 시청 시간은 세션의 추천을 기반으로 사용자가 콘텐츠를 시청하는 데 소비한 전체 시간을 측정한다. 여기서 중요한 측정 측면은 사용자가 세션을 시청하는 데 상당한 시간을 할애할 정도로 의미 있는 추천을 세션에서 찾을 수 있다는 것이다.
-ㅍ세션 시청 시간이 참여율 및 시청한 동영상보다 더 나은 지표인 이유를 직관적으로 설명하기 위해 두 명의 사용자 A와 B의 예를 들어보자면, 사용자 A는 5개의 추천에 반응하고 그 중 3개를 10분 동안 시청한 다음 세션을 종료했다. 사용자 B가 두 가지 추천에 반응하고 첫 번째 추천 미디어에 5분을 보낸 다음 두 번째 추천 미디어에 90분을 소비했다. 사용자 A가 더 많은 콘텐츠에 참여했지만 사용자 B의 세션은 흥미로운 콘텐츠를 찾았기 때문에 확실히 더 성공적이었다.
따라서 세션 성공을 나타내는 세션 시청 시간 측정은 영화 추천 시스템의 온라인 추적에 좋은 지표이다.
Offline metrics (오프라인 평가 항목)
- 오프라인 측정 항목를 구축하는 목적은 새로운 모델을 신속하게 평가할 수 있도록 하는 것이다.
오프라인 지표는 새로운 모델이 추천의 품질을 향상시킬지 여부를 알려줄 수 있어야 한다.
추천 세트 품질을 측정할 수 있는 이상적인 문서 세트를 구축할 수 있을까?
이를 수행하는 한 가지 방법은 사용자가 완전히 시청한 영화/시리즈를 보고 추천 시스템이 과거 데이터를 사용하여 올바른 정보를 제공하는지 확인하는 것이다.
사용자 추천 목록에 있어야 한다고 자신있게 말할 수 있는 영화/시리즈 세트가 있으면 다음 오프라인 측정항목을 사용하여 추천 시스템의 품질을 측정할 수 있다.
mAP @ N
- 이러한 측정항목 중 하나가 Mean Average Precision(mAP @ N)이다
📝 N = 추천 목록의 길이
오프라인 품질을 측정하는 것이 왜 좋은지 직관할 수 있도록 이 지표가 계산되는 방법을 살펴보면,
정밀도는 영화 추천 목록의 관련 추천과 전체 추천 간의 비율을 측정하는 것이다.

P = 관련 추천 수 / 전체 추천 수
- 정밀도만으로는 목록에서 관련 항목을 초기에 배치하는 데 도움이 되지 않는다.
그러나 목록에서 각 위치 k(k = 1 ~ N)까지 추천 하위 집합의 정밀도를 계산하고 가중 평균을 취하면 목표를 달성할 수 있다.
아래와 같이 다음을 가정합니다.
- 시스템에서는 N=5개의 영화를 추천했다.
- 사용자는 이 추천 목록에서 영화 3개를 시청하고 나머지 2개는 무시했다.
- 시스템이 추천할 수 있는 모든 영화(Netflix 플랫폼에서 이용 가능) 중에서 m = 10만이 실제로 사용자와 관련이 있다(과거 데이터).

다음 다이어그램에서는 1부터 5까지 각 위치 k까지 추천 하위 집합의 정밀도를 계산한다.
< 컷오프 k=1 ~5 까지 정밀도 계산>
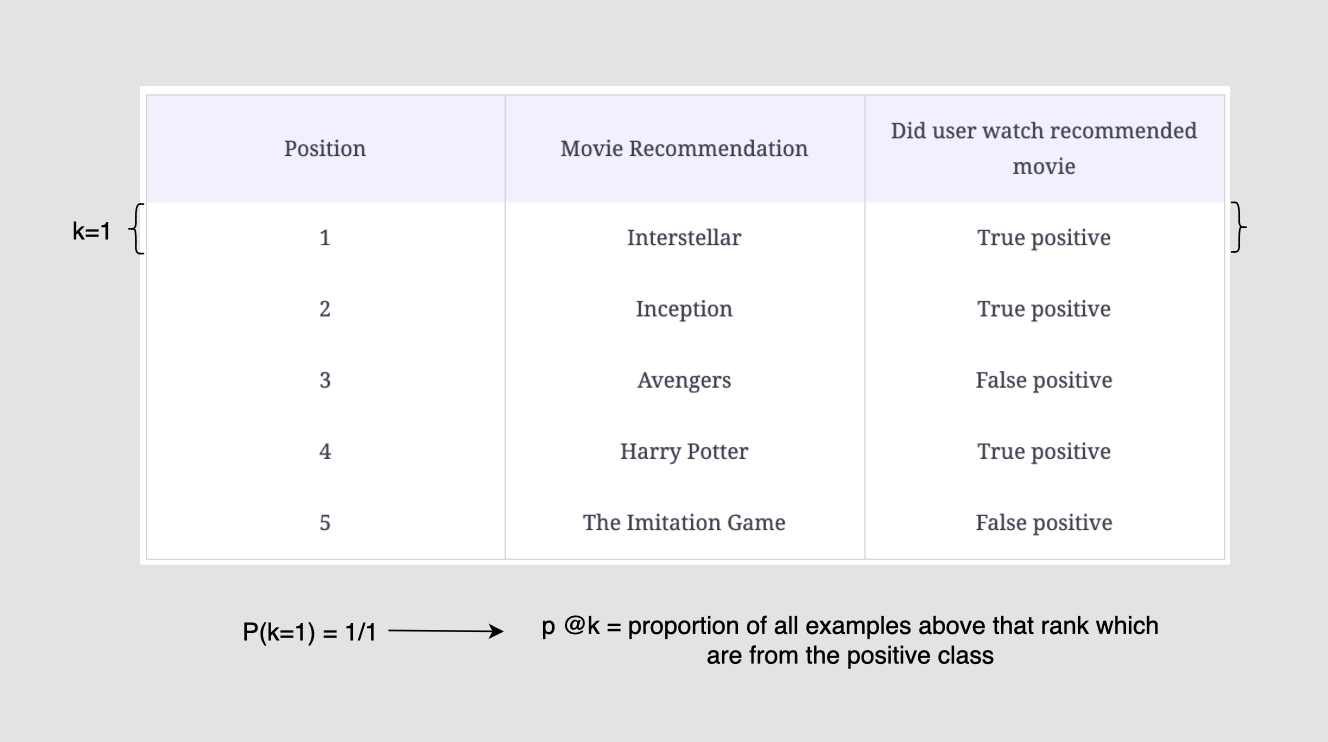
p @ k : 양성 클래스(Posivite class) 에서 순위가 매겨진 모든 예제의 비율
현재 k=1이고, 양성클래스 1개 중 1개를 잘 예측했으므로 P(k=1) = 1/1이다.
[그림] 컷오프 k = 1까지의 정밀도 계산
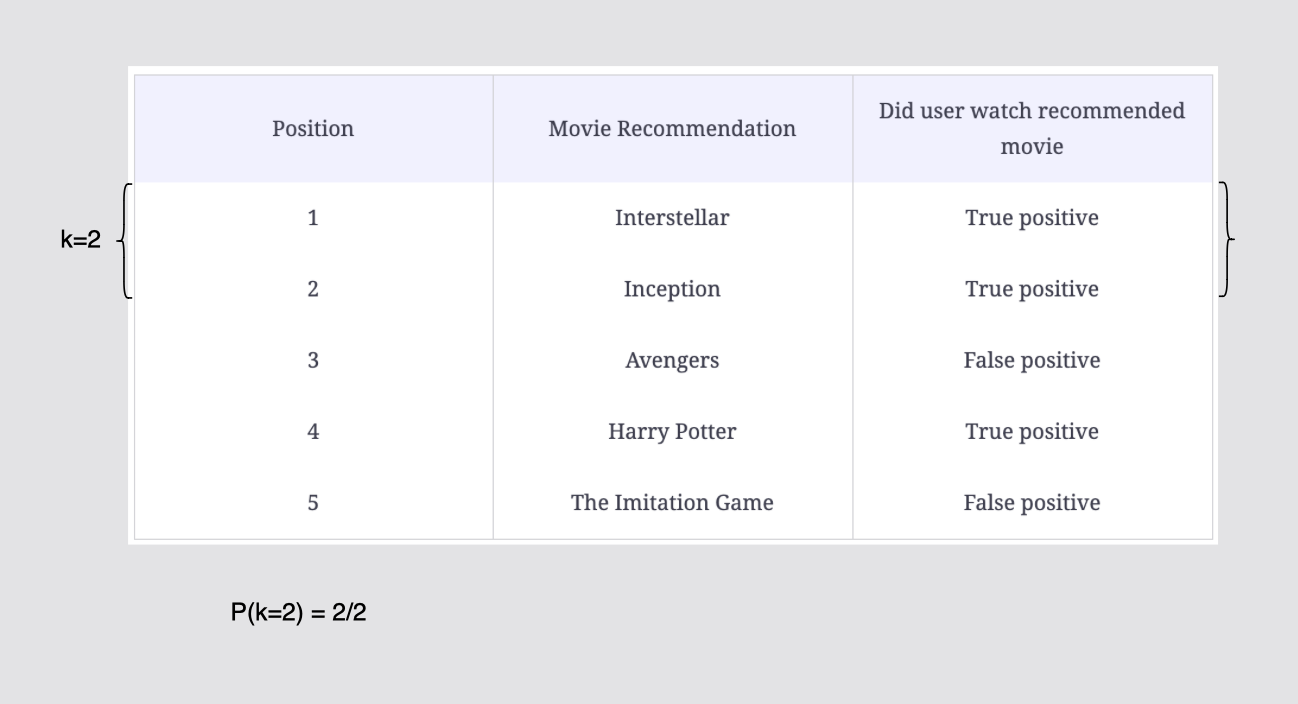
k=2이고, 양성클래스가 총 2개 나왔고 잘 예측했으므로 p(k=2) = 2/2
[그림] 컷오프 k = 2까지의 정밀도 계산
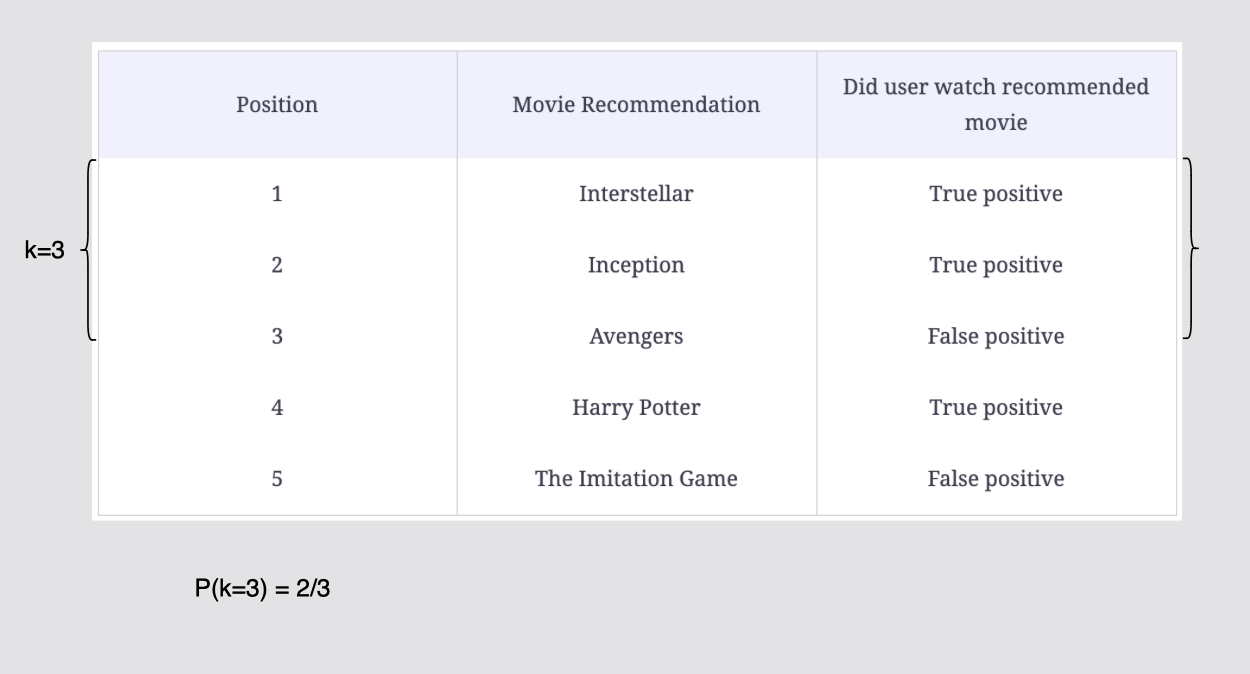
양성 클래스가 3개 나왔지만 위 position 의 3은 추천에서 선택받지 못했다.
p(k=3)은 2/3 이다.
[그림] 컷오프 k = 3까지의 정밀도 계산

총 4개의 positive class에서 3개가 True,
즉 p @ k(k=4) = 3/4
[그림] 컷오프 k = 4까지의 정밀도 계산
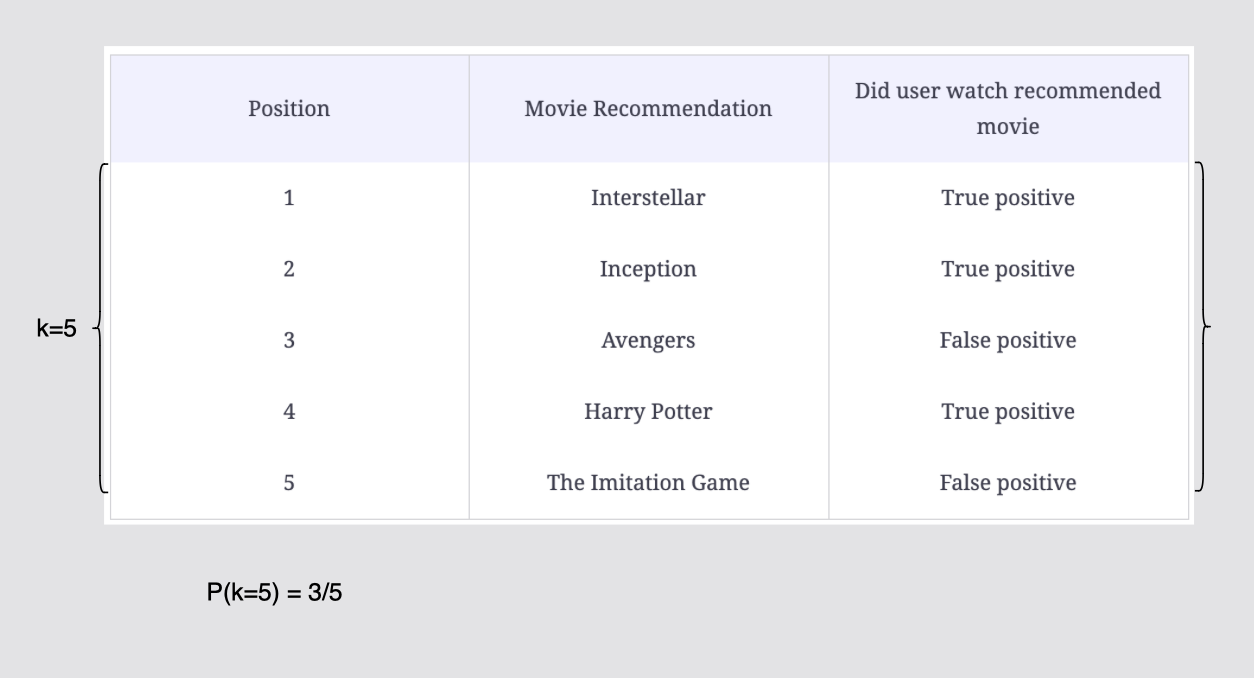
positive class 5개중 k=5 까지 볼 때 3개의 TP로 p(k=5) = 3/5이다.
[그림] 컷오프 k = 5까지의 정밀도 계산
영화 추천 목록과 각 컷오프 "k"(1~5)에서의 정밀도는 다음과 같이 나타낼 수 있다.
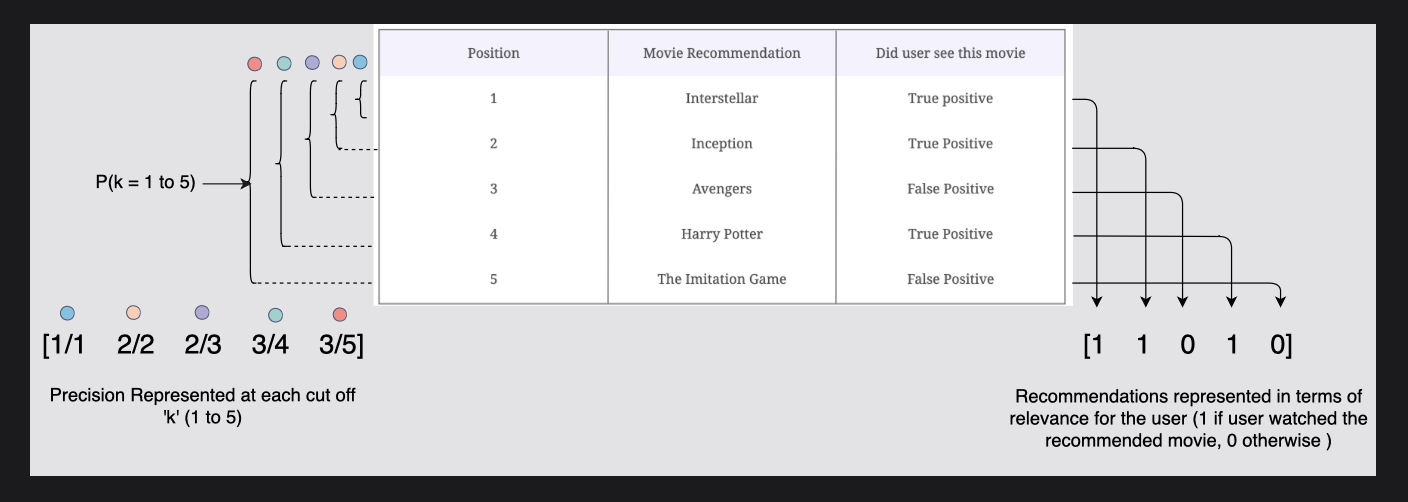
그림에서 보면 왼쪽에서는 "각 컷오프 k(1~5)에서 표현되는 정밀도를 나타내고,
오른쪽에서는 사용자와의 관련성 측면에서 표현된 추천(사용자가 추천 영화를 본 경우 1, 그렇지 않은 경우 0)로 나타낸 것이다.
이제 평균 정밀도(AP)를 계산하기 위해 다음 공식을 사용한다.
위 공식에서 rel(k)는 k번째 항목이 관련이 있는지 여부를 알려준다.
공식을 적용하면 다음과 같다.

rel(k)로 각 위치 k에서의 관련성을 나타내고
예를 들어 rel(k) 첫번째 k=1은 position 1 에서 선택받아 1을 나타내고
P(k)의 첫번째 k=1은 총 1개의 positive class에서 1개가 positive 였으므로 1/1을 나타낸다.
이 둘을 곱해주고, 총 추천됐던 10개의 추천으로 나눠주면 평균 정밀도 AP가 나오게 된다.
[그림] 추천 목록의 평균 정밀도
여기서 k의 추천이 관련이 있는 경우에만 P(k)가 AP에 기여한다는 것을 알 수 있다.
또한 세 가지 추천 목록의 다음 점수를 통해 AP의 "placement legalization"를 관찰한다.
*"Placement legalization"은 추천 시스템에서 사용되는 개념 중 하나로, 추천된 아이템의 배치를 조정하거나 정규화하는 과정이다.

추천 항목에서 목록의 아래쪽인 TP(true positive)인 1은 목록의 위쪽에 있는 mAP에 비해 mAP가 낮아진다. 이는 추천 집합의 시작 부분에 최상의 추천 사항이 있어야 하기 때문에 중요한 부분이다.
마지막으로, mAP의 "평균"은 각 사용자의 평점에 대한 AP를 계산하고 그 평균을 취한다는 의미이다. 따라서 mAP는 대규모 사용자 집합에 대한 측정항목을 계산하여 대규모 사용자 집합에서 시스템이 전반적으로 어떻게 작동하는지 확인한다.
mAP @ N
- 또 다른 측정항목은 Mean Average Recall(mAR @ N)이다.
이는 mAP @ N과 유사하게 작동하는데, 차이점은 정밀도 대신 재현율을 사용한다는 점이다.
추천 목록에 대한 재현율은 목록의 관련 추천 수와 가능한 모든 관련 항목(쇼/영화) 수 간의 비율이다. 다음과 같이 계산할 수 있다.
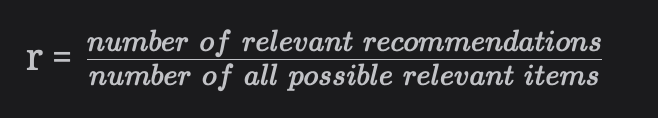
r = 관련 추천 수 / 관련된 추천 항목에서 긍정적인 항목의 수
mAP @ K 예시에서 사용된 것과 동일한 추천 목록을 사용해서 살펴보자.
여기서 N = 5이고 m = 10 이다. 각 위치 k까지 추천 하위 집합의 재현율을 계산해 보자.
< 컷오프 k=1 ~5 까지 재현율 계산>
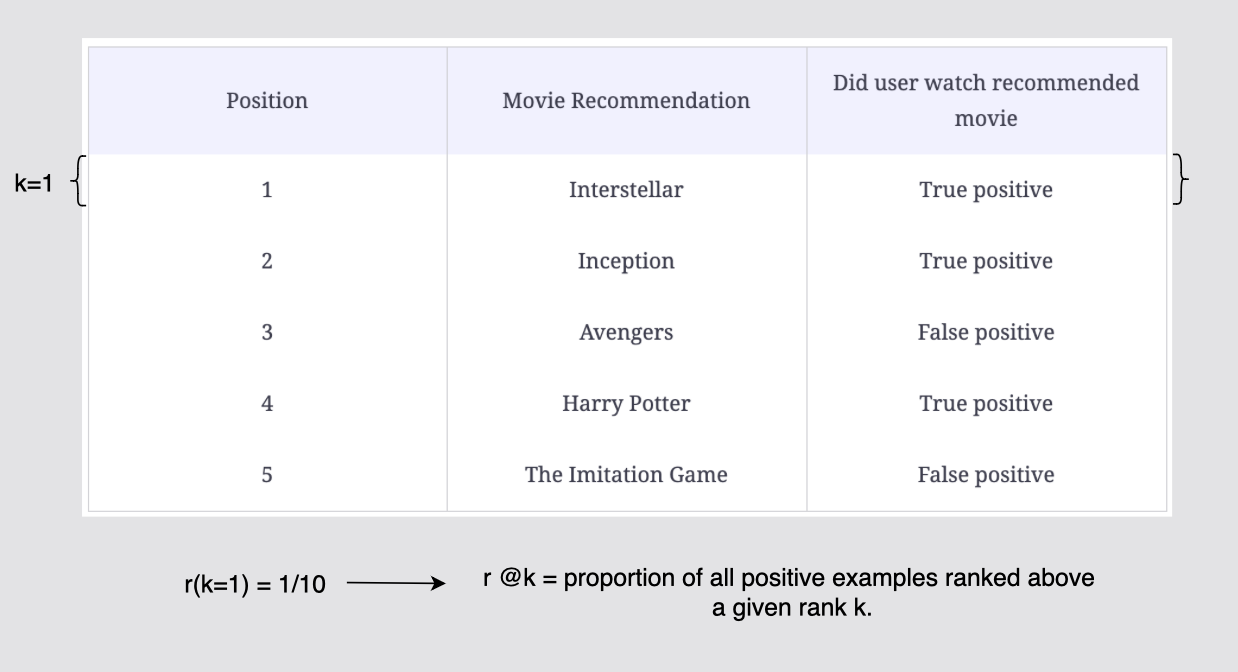
r @ k 는 주어진 순위 k 보다 높게 순위가 매겨진 모든 양성(positive) 예제의 비율이다. 추천 목록 10개에서 k=1 위치에서의 양성 예제의 비율은 r(k=1) = 1/10이다.
[그림] 컷오프 k = 1까지의 재현율 계산
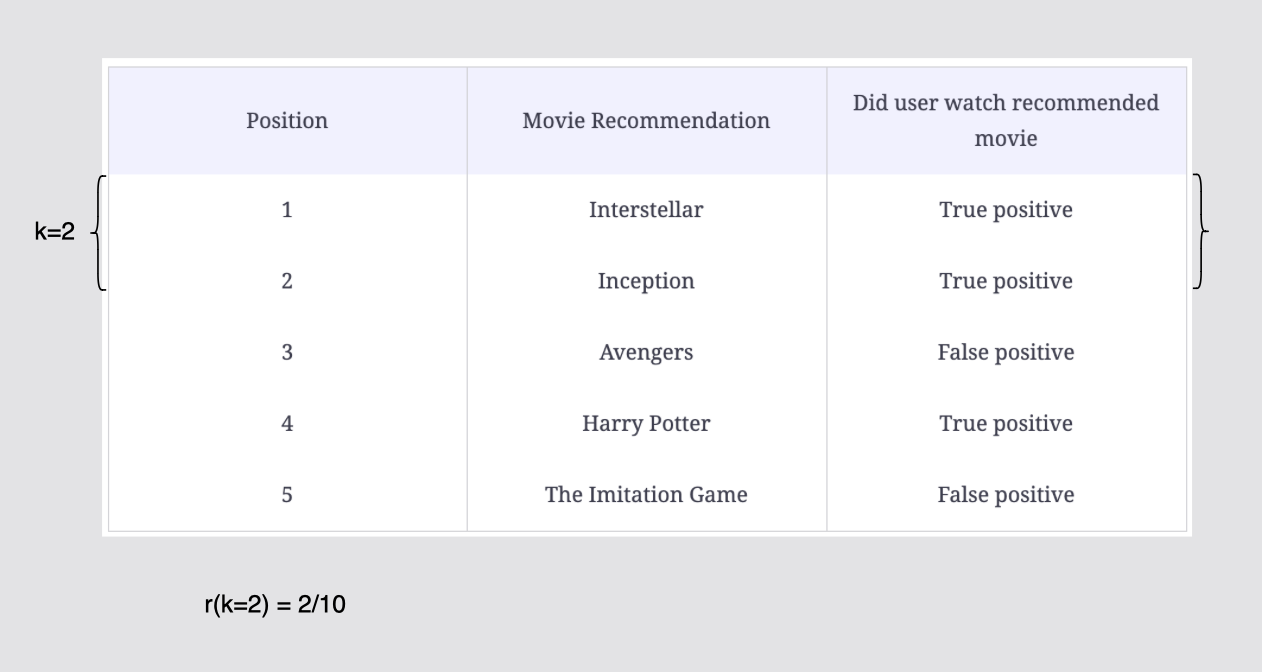
추천 목록 10개에서 k=2 위치에서 양성 예제의 비율은 r(k=2) = 2/10이다.
[그림] 컷오프 k = 2까지의 재현율 계산

역시 추천목록 10개에서 k=3에서의 양성 비율은 r(k=3) = 2/10이다.
[그림] 컷오프 k = 3까지의 재현율 계산
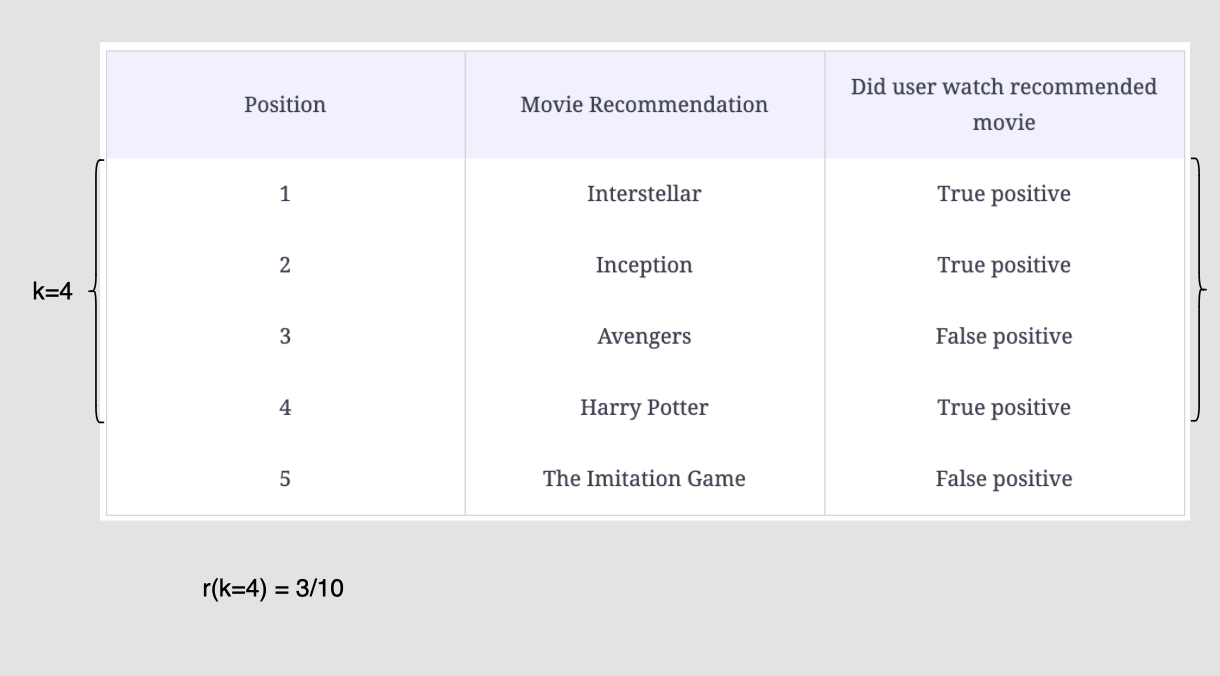
추천목록 10개 중 k=4에서의 재현율은 r(k=4) = 3/10이다.
[그림] 컷오프 k = 4까지의 재현율 계산
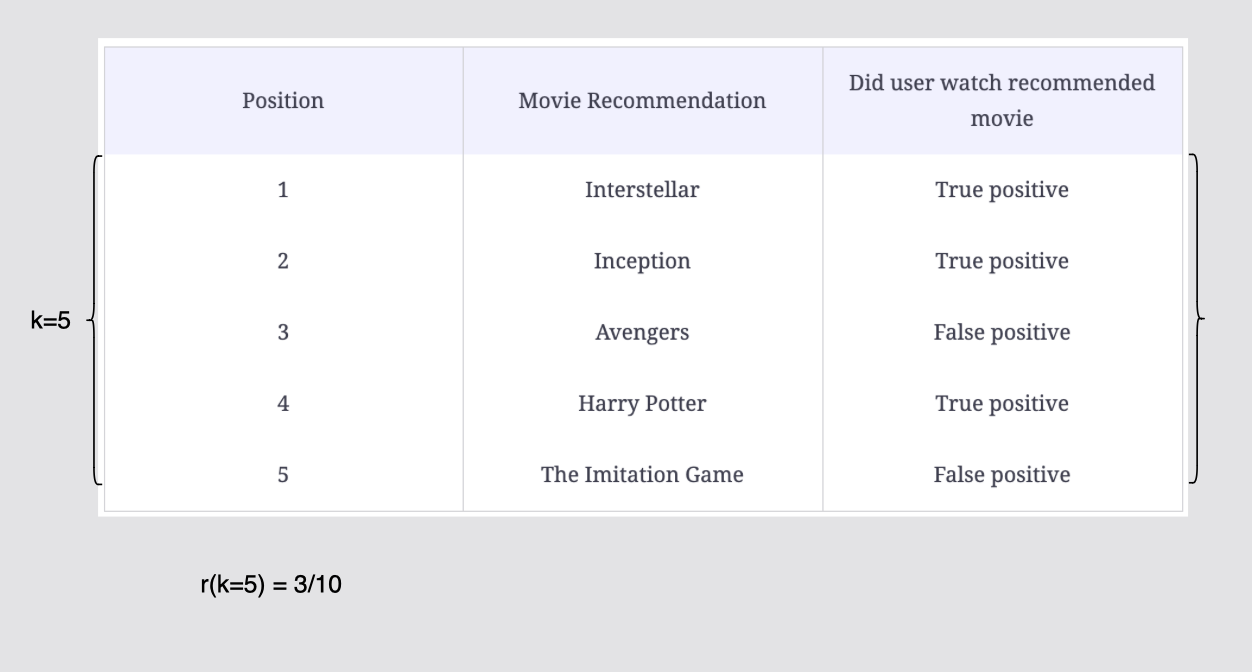
k=5에서의 재현율은 r(k=5) = 3/10이다.
[그림] 컷오프 k = 5까지의 재현율 계산
그러면 평균 재현율(AR)은 다음과 같이 계산된다.

rel(k)는 각 위치 k에서의 양/음 유무를 나타내고 r(k)에서는 위치 k에서의 양성비율을 나타냈고, 이둘을 곱해서 m의 수만큼 나눠주어 AR을 계산한다.
[그림] 위에 제공된 추천 목록의 평균 재현율
마지막으로 mAR의 "평균"은 각 사용자의 평점에 대해 AR을 계산한 다음 그 평균을 취한다는 의미이다. 따라서 높은 수준의 mAR은 추천 세트에서 얻을 수 있는 최고 추천 항목(기록 데이터 기반) 수를 측정한다.
F1 score
📝 두 가지 모델이 있다고 생각하자.
하나는 더 나은 mAP @ N 점수를 제공하고 다른 하나는 더 나은 mAR @ N 점수를 제공한다. 어떤 모델이 전반적인 성능이 더 나은지 어떻게 결정해야 할까?
정밀도와 재현율을 동등하게 중요하게 여기려면 정밀도와 재현율 간의 균형 잡힌 점수를 찾아야한다.
- mAP @ N은 추천이 얼마나 관련성이 있는지에 초점을 맞추고,
반면에 mAR @ N은 추천하는 모델이 추천에서 긍정적인 피드백이 있는 모든 항목을 얼마나 잘 예측하는지를 고려한다. 추천 모델에 대해 이러한 측정항목을 모두 고려하고 자 할때, 최종 측정항목인 'F1 점수'를 고려한다.
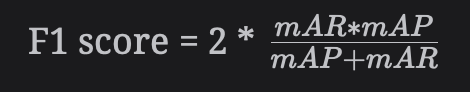
따라서 mAP 및 mAR을 기반으로 한 F1 점수는 모델의 품질을 측정하는 데 상당히 좋은 오프라인 방법이다.
- 추천 세트 크기를 5로 선택했지만 추천 뷰포트 또는 플랫폼 사용자가 일반적으로 참여하는 권장 사항 수에 따라 다를 수 있다.
Offline metric for optimizing ratings (오프라인 평가 항목 최적화)
- 암시적 피드백 데이터를 통해 시스템을 최적화한다는 것을 위에서 확인했다.
그러나 평점(명시적 피드백)을 제대로 받기 위해서는 추천 시스템을 최적화해야 한다고 말한다면 어떨까? 여기서는 평점 예측 오류를 최소화하기 위해 RMSE(Root Mean Squared Error)를 사용하는 것이 합리적이다.
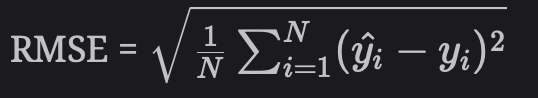
yi^는 영화에 대한 추천 시스템의 예측 평점이고, yi는 사용자가 실제로 부여한 실제 평점이다.
이 두 값의 차이가 오류이고, 이 오류의 평균은 N개의 영화에서 계산된다.
참고사이트
