Recommendation System
1.Grokking the Machine Learning Interview - Recommendation System (1) Problem Statement
추천 시스템은 우리가 매일 사용하는 대부분의 플랫폼에서 사용된다. 예를 들어:Amazon 홈페이지에서의 맞춤형 제품 추천핀터레스트 피드에 트렌드와 검색 기록을 바탕으로 한 핀넷플릭스의 나의 취향 및 인기 영화를 바탕으로 한 영화 추천 여기서는 Netflix 영화 추천
2.Grokking the Machine Learning Interview - Recommendation System (2) Metrics
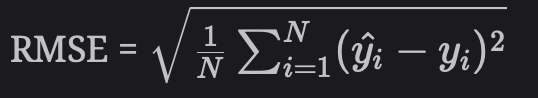
Grokking the Machine Learning Interview Recommendation System (2) Metrics 추천 시스템의 성능을 판단하는 데 사용되는 온라인 및 오프라인 지표를 살펴본다. 측정항목(메트릭)유형 온라인 지표 참여율
3.Grokking the Machine Learning Interview - Recommendation System (3) Architectural Components
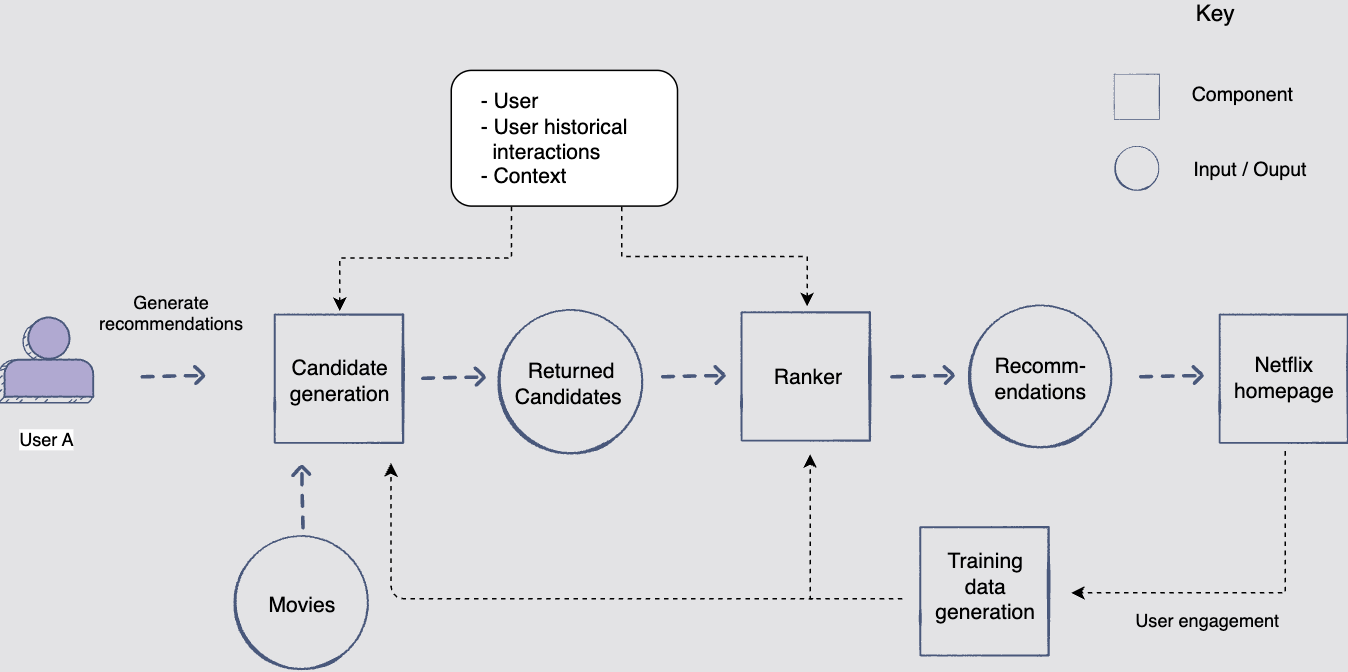
대규모 영화 데이터에서는 다단계 순위 문제로 최상의 추천을 생성하는 것을 고려하는 것이 합리적이다. 그 이유는 우리가 선택할 수 있는 영화가 너무나 많기 때문에 개인화된 추천을 제공하려면 복잡한 모델이 필요하다.그러나 복잡한 모델을 전체 말뭉치(코퍼스)에서 실행하려고
4.Grokking the Machine Learning Interview - Recommendation System (4) Feature Engineering

추천 후보 생성 및 순위 모델을 위한 피처 엔지니어링영화 추천 플랫폼에서 피처 엔지니어링 프로세스를 시작하려면 먼저 영화/쇼 추천 프로세스의 주요 요소를 식별한다. (1) 로그인한 사용자(2) 영화/쇼 콘텐츠(3) 상황(예: 계절, 시간 등)<그림> 미디어 추천
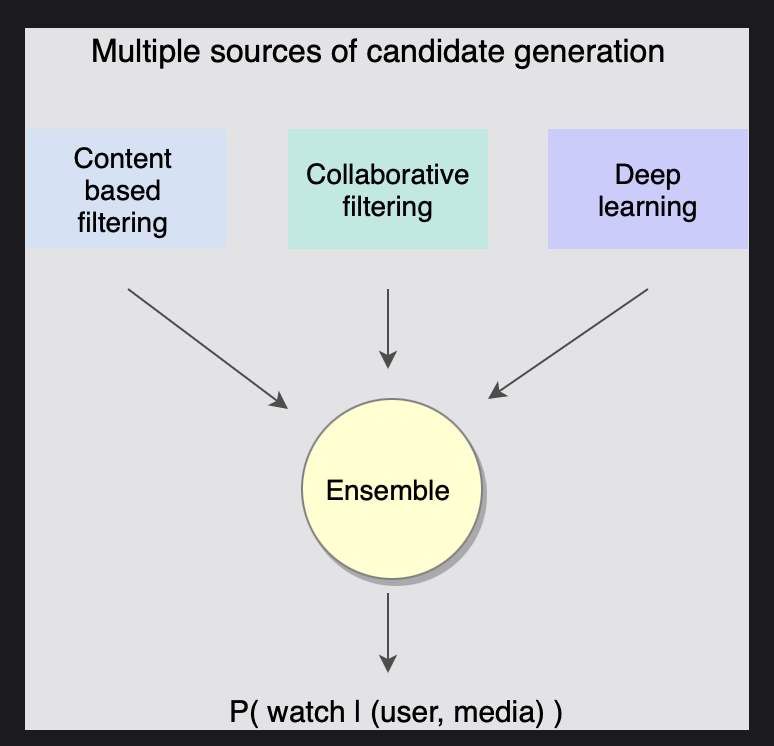
5.Grokking the Machine Learning Interview - Recommendation System (5) Candidate Generation

Grokking the Machine Learning Interview - Recommendation System 5. Candidate Generation 추천 후보자 생성 기술 협업 필터링 (Collaborative filtering) 방법 1:
6.Grokking the Machine Learning Interview - Recommendation System (6) Training Data Generation
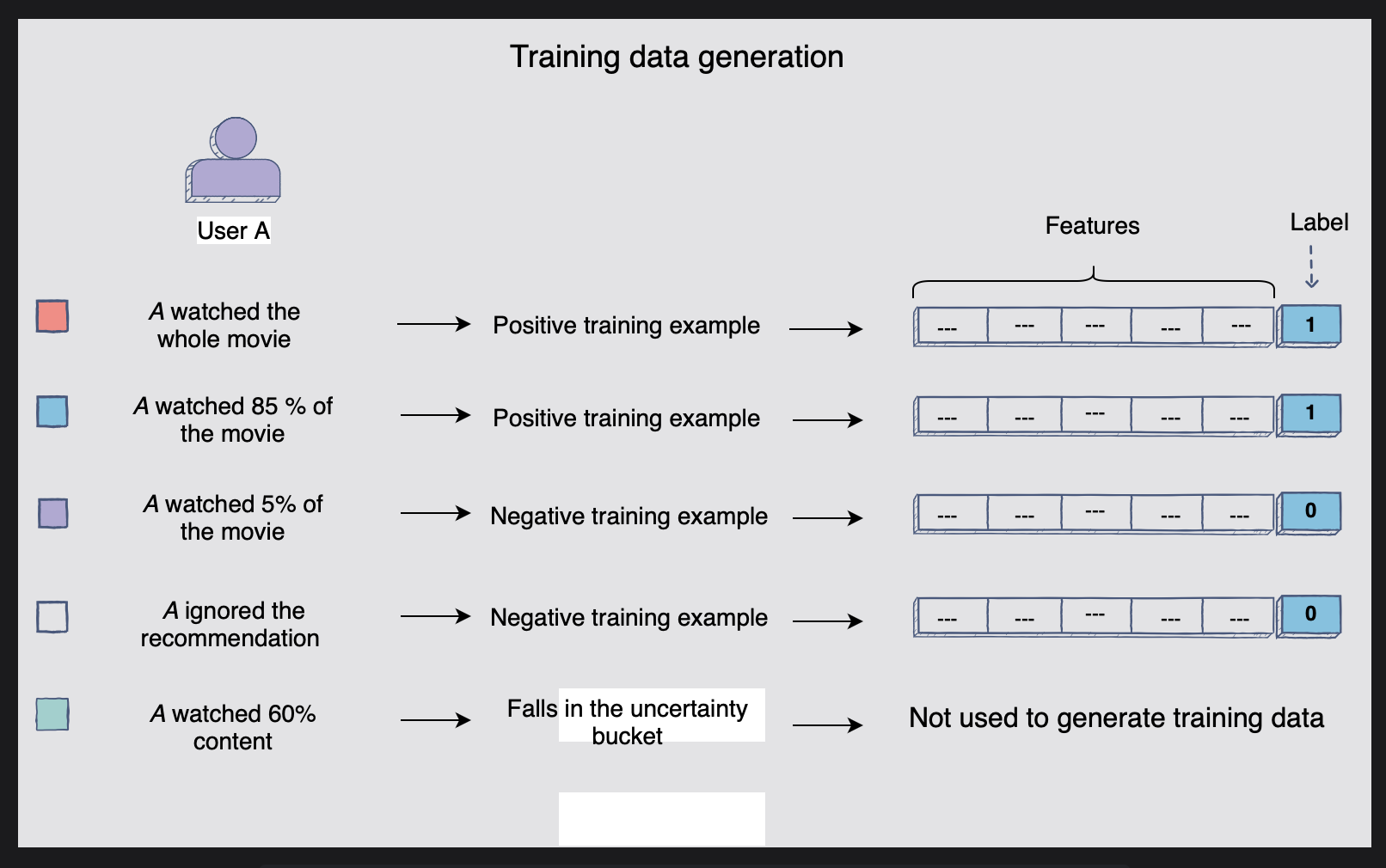
암시적(Implicit)인 사용자 피드백과 관련하여 추천 작업을 위한 훈련 데이터를 생성하는 과정과 관련된 내용이다. 훈련 예시 생성긍정적인 훈련 사례와 부정적인 훈련 사례의 균형가중치 훈련 예시학습 테스트 분할등의 순서로 언급하겠다. 이전 포스팅에서 언급한 바 있는데
7.Grokking the Machine Learning Interview - Recommendation System (7) Ranking
추천 시스템의 모델링 옵션을 살펴본다.접근 방식 1: 로지스틱 회귀 또는 랜덤 포레스트접근 방식 2: 희소 및 밀집 피처를 사용한 Deep NN (딥러닝 뉴럴 네트워크)네트워크 구조순위 재지정순위 모델은 우리가 논의한 다양한 추천 후보 생성 소스에서 최고의 후보를 선택