Grokking the Machine Learning Interview - Recommendation System (7) Ranking
Recommendation System
Grokking the Machine Learning Interview
Recommendation System (7) Ranking
추천 시스템의 모델링 옵션을 살펴본다.
- 접근 방식 1: 로지스틱 회귀 또는 랜덤 포레스트
- 접근 방식 2: 희소 및 밀집 피처를 사용한 Deep NN (딥러닝 뉴럴 네트워크)
- 네트워크 구조
- 순위 재지정
순위 모델은 우리가 논의한 다양한 추천 후보 생성 소스에서 최고의 후보를 선택하는 것이다.
그런 다음 이러한 모든 추천 후보의 앙상블이 생성되고 사용자가 해당 비디오 콘텐츠를 시청할 확률을 기준으로 후보의 순위가 매겨진다.
여기서 목표는 사용자와 후보 미디어(예: P(watch|(User, Media)))가 주어진 미디어를 사용자가 시청할 확률을 기준으로 콘텐츠 순위를 지정하는 것이다.
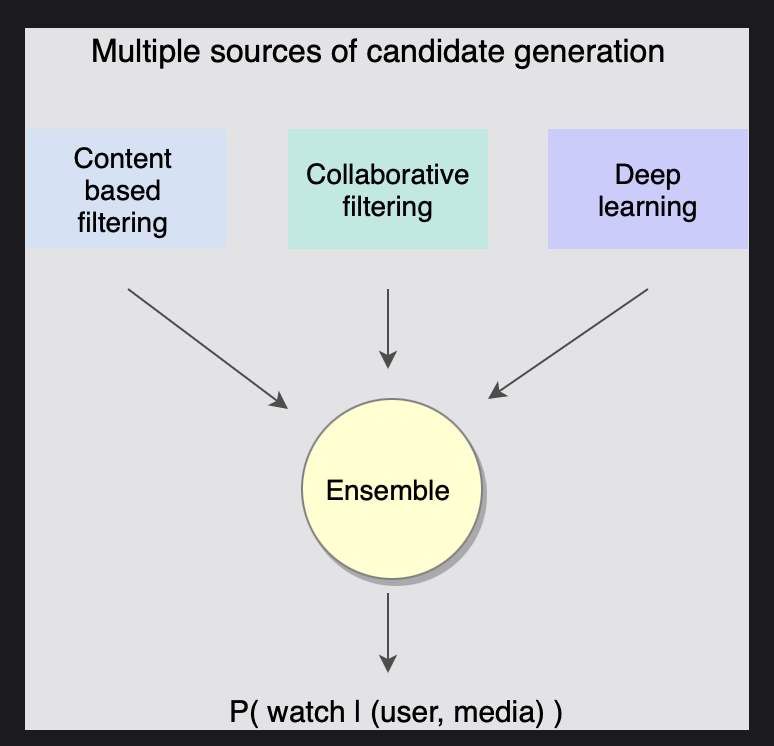
[그림] 후보자 생성 모델들의 앙상블
- 시청 확률을 예측할 수 있는 몇 가지 방법이 있다.
먼저 단순한 접근 방식을 시도하여 얼마나 멀리 예측할 수 있는지 확인한 다음에 복잡한 모델링 접근 방식을 적용하여 시스템을 더욱 최적화하는 것이 합리적이다. - 먼저 로지스틱 회귀 또는 트리 앙상블 방법을 사용하는 몇 가지 접근 방식에 대해 논의한 다음 밀집하고 희소한 특성을 갖춘 딥 러닝 모델을 논의한다.
- 딥 러닝은 희소한 피처를 통해 학습할 수 있어야 하며 단순한 접근 방식보다 뛰어난 성능을 발휘해야 한다. 그러나 이전 문제에서 논의한 것처럼 딥러닝 모델을 사용한 일반화에는 훨씬 더 많은 데이터(1억 개 정도의 훈련 예제)와 훈련 용량/시간(100배 더 많은 CPU 주기)이 필요하다.
접근 방식 1. 로지스틱 회귀와 랜덤 포레스트 (Logistic regression or random forest)
단순한 모델을 훈련하는 것이 좋은 이유에는 여러 가지가 있다.
- 제한된 학습 데이터
- 학습 및 모델 평가 역량이 제한됨
- ML 모델이 결정을 내리는 방식을 실제로 이해하고 이를 최종 사용자에게 보여주기 위해 모델 설명 기능이 필요함
- 더 복잡한 접근 방식을 시도하기 전에 테스트 세트 손실을 얼마나 줄일 수 있는지 확인하려면 초기 기준이 필요함
피처 엔지니어링 포스팅에서 논의한 다른 중요한 피처 등과 함께 다양한 후보 선택 알고리즘의 출력 점수도 순위 모델에서 사용되는 상당히 중요한 인풋이다.
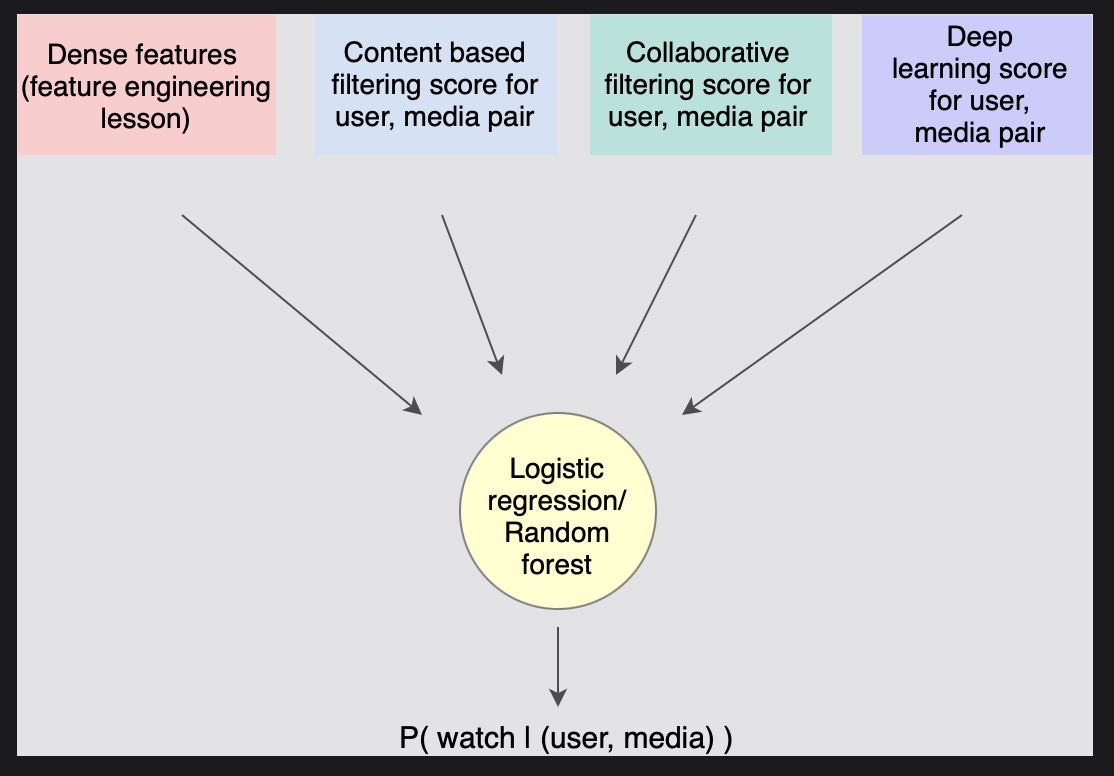
- 테스트 오류를 최소화하고 테스트 데이터에 대해 최상의 결과를 제공하는 훈련 및 정규화를 위한 하이퍼파라미터를 선택하는 것이 중요하다.
접근 방식 2. 희소 및 밀집 벡터와 딥러닝
-
이 문제를 모델링하는 또 다른 방법은 딥러닝을 활용하는 것이다.
접근 방식 1(로지스틱 회귀나 랜덤 포레스트)에서 논의된 요소 중 일부는 이제 이 딥러닝 모델을 교육하기 위한 핵심 요구 사항이다. -
수억 개의 학습 예제를 사용할 수 있어야 함
-
용량 및 모델 해석 가능성 측면에서 이러한 모델을 평가할 수 있는 능력을 갖는 것은 그다지 중요하지 않음
Netflix의 규모를 고려하면 위의 요구 사항을 충족하는 것이 문제가 되지 않는다.
대규모 데이터를 활용하면 앞에서 설명한 단순한 접근 방식보다 확실히 뛰어난 성능을 발휘할 수 있다.
사용자가 미디어를 시청할지 여부를 예측하려는 아이디어이므로 이 학습 작업을 위해 희소하고 밀집된 피처를 사용하여 딥러닝을 훈련한다.
이러한 네트워크에 공급되는 두 가지 매우 강력한 희소 피처는 사용자가 이전에 시청한 비디오와 사용자의 검색어일 수 있다. 이러한 희소 피처의 경우 학습 작업의 일부로 미디어 및 검색어 임베딩도 학습하도록 네트워크를 설정할 수 있다.
과거 시청 내역 및 검색어에 대한 이러한 특수 임베딩은 사용자의 다음 시청할 미디어에 대한 아이디어를 예측하는 데 매우 강력할 수 있다. 이를 통해 모델은 플랫폼에서 사용자의 최근 미디어 콘텐츠 상호 작용을 기반으로 추천 순위를 개인화할 수 있다.
여기서 중요한 측면은 검색어와 과거 시청 콘텐츠가 모두 목록별 기능이라는 것이다.
레이어의 크기가 고정되어 있다는 점을 고려하여 네트워크에 어떻게 공급할지 고민해야 한다.
CNN(컨볼루션 신경망)의 풀링 레이어와 유사한 접근 방식을 사용하고 네트워크에 입력하기 전에 과거 시청한 ID와 검색 텍스트 용어 임베딩을 평균화한다.
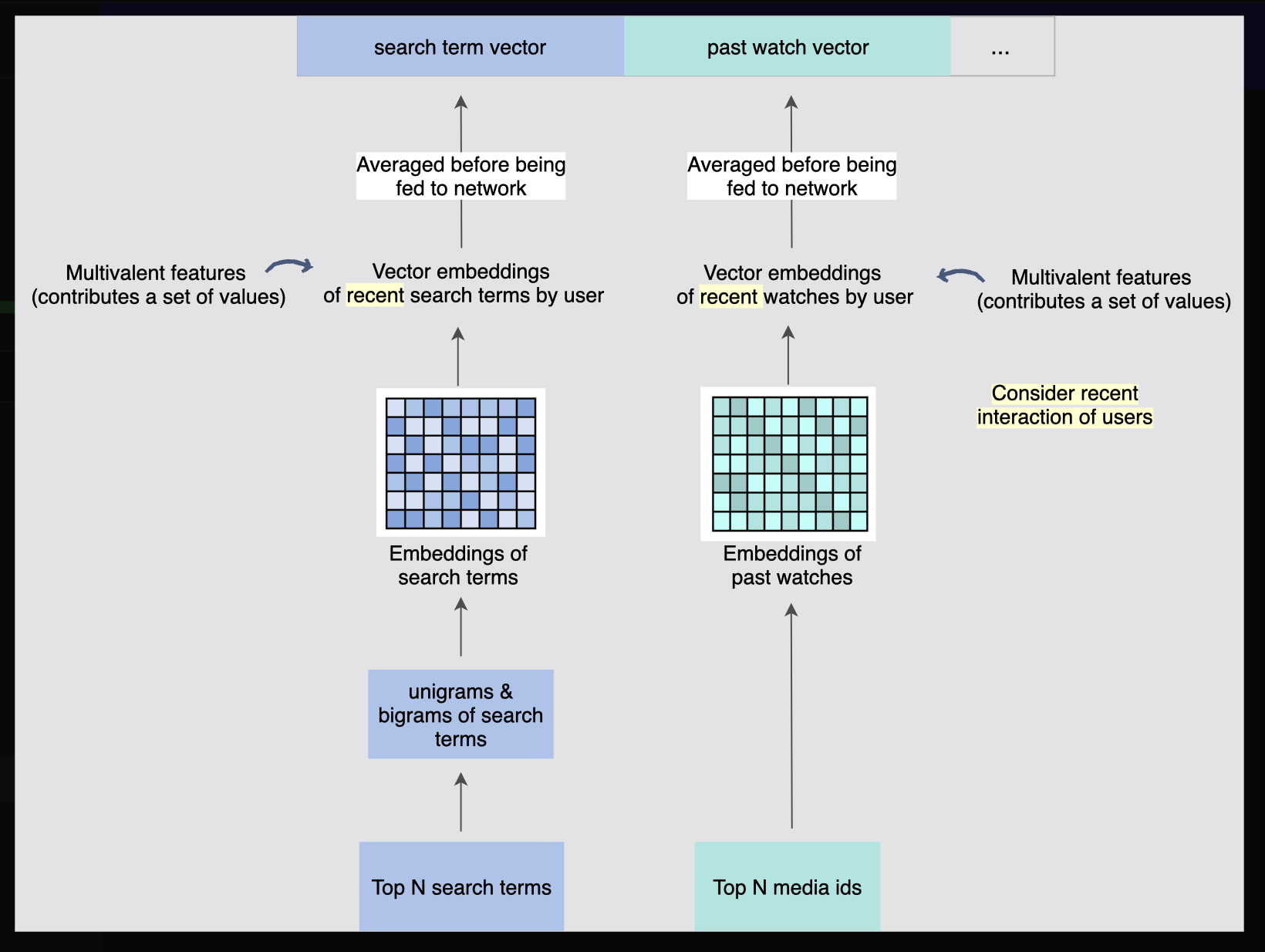
[그림] 시청했던 기록 및 사용자의 검색어를 기반으로 피처를 생성
- 사용자의 검색어나 어휘(단어) 범위를 벗어나는 내용은 0 임베딩(모두 0으로 구성된 벡터)으로 매핑된다. 📝 어휘(단어)는 고유한 ID 공간을 가진다.
네트워크를 설정하는 한 가지 방법은 이러한 희소 데이터 임베딩을 활용하고 이를 신경망에 공급하는 방법이다.
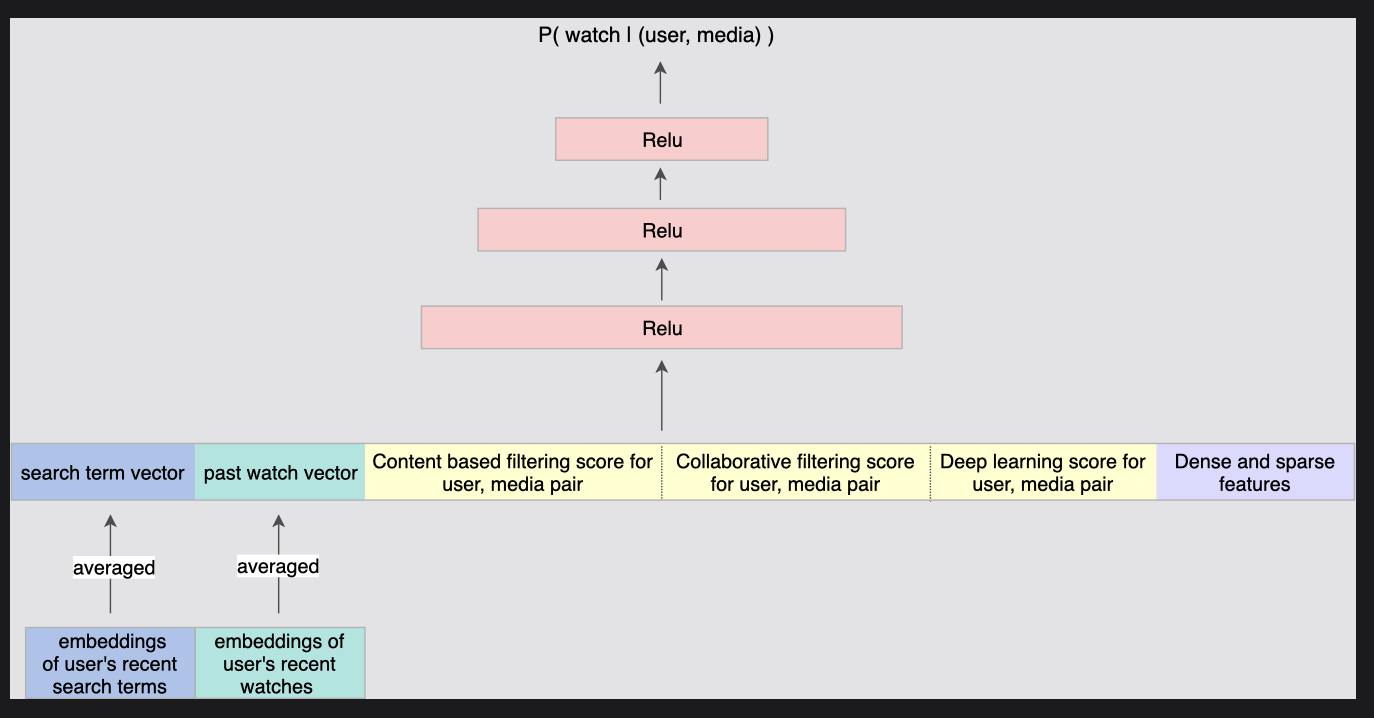
[그림] 임베딩한 벡터와 다른 밀집 벡터들을 딥러닝 모델에 학습시킴
위에 표시된 것처럼 다른 기능과 함께 학습한 임베딩 위에 계층화된 여러 RELU 단위로 설정할 수 있다. 최상위 계층은 로지스틱 손실을 사용하여 미디어를 시청할지 여부를 예측한다.
Network structure (네트워크 구조)
- 몇 개의 레이어를 설정해야 할까?
- 각 레이어에는 몇 개의 활성화 함수를 사용해야 할까?
이러한 질문에 대한 가장 좋은 대답은 RELU 기반 활성화 함수를 사용하여 2~3개의 숨겨진 레이어로 시작한 다음 숫자를 가지고 이것이 테스트 오류를 줄이는 데 어떻게 도움이 되는지 확인해야 한다는 것이다. 일반적으로 더 많은 레이어와 단위를 추가하면 처음에는 도움이 되지만 그 유용성은 빠르게 감소한다. 오류율 감소에 비해 계산 및 시간 비용이 더 높아질 수 있다.
Re-ranking (재순위 설정)
-
사용자 페이지의 상위 10개 추천은 매우 중요하다.
시스템에서 시청 확률을 제공하고 그에 따라 결과의 순위를 매긴 후 결과의 순위를 다시 지정할 수 있다. -
추천에 다양성을 부여하는 등 다양한 이유로 순위를 다시 매기는 작업이 수행된다.
추천 영화 상위 10개가 모두 코미디인 시나리오를 생각해 본다면, 상위 10개 추천에 각 장르 중 2개만 유지하기로 결정할 수도 있다. 이렇게 하면 사용자에게 상위 추천 항목에 5가지 다른 장르가 표시된다. -
미디어 추천을 위해 과거 시청도 고려하고 있다면 순위를 다시 매기는 것이 도움이 될 수도 있다. 이전에 시청한 일부 미디어를 추천 목록 아래로 이동하여 추천 목록이 이전 시청으로 인해 전복되는 것을 방지한다.
참고사이트
