Grokking the Machine Learning Interview - Recommendation System (6) Training Data Generation
Recommendation System
Grokking the Machine Learning Interview
Recommendation System - (6) Training Data Generation
암시적(Implicit)인 사용자 피드백과 관련하여 추천 작업을 위한 훈련 데이터를 생성하는 과정과 관련된 내용이다.
- 훈련 예시 생성
- 긍정적인 훈련 사례와 부정적인 훈련 사례의 균형
- 가중치 훈련 예시
- 학습 테스트 분할
등의 순서로 언급하겠다.
이전 포스팅에서 언급한 바 있는데, 사용자의 암시적 피드백(Implicit feedback)을 기반으로 추천 모델을 구축한다. 사용자가 추천 받은 미디어와 어떻게 상호작용하여 긍정적이고 부정적인 훈련 사례를 생성하는지 살펴보자.
Generating training examples(훈련 예제 생성하기)
-
사용자 행동을 긍정적이고 부정적인 훈련 사례로 해석하는 한 가지 방법은 사용자가 특정 쇼/영화를 시청한 기간을 기반으로 한다. 사용자가 추천한 영화나 쇼를 대부분 시청한 경우, 즉 80% 이상 시청한 경우를 긍정적인 예로 들 수 있다.
반대로는 사용자가 영화/쇼를 무시하는, 즉 10% 이하로 시청한 부정적인 예로 들 수 있다. -
사용자가 시청한 영화/쇼의 비율이 10%에서 80% 사이에 해당하면 이를 불확실성 버킷에 넣는다. 이 비율은 사용자의 좋아요 또는 싫어요를 명확하게 나타내지 않으므로 이러한 예는 무시된다.
-
예를 들어 사용자가 영화의 55%를 시청했다고 가정해 볼때, 중간에 시청할 정도로 좋아했다는 점에서 이는 긍정적인 사례라고 볼 수 있다. 하지만 많은 사람들이 추천했을 수도 있기 때문에 적어도 중간 정도 시청하면서 정말 재밌는 지 확인하고 싶을 수도 있다. 그러나 결국 자신들의 취향에 맞지 않는다고 결론을 내릴 수도 있다.
따라서 이러한 종류의 오해를 피하기 위해 더 높은 수준으로 확신할 경우에만 사례에 긍정적인 것과 부정적인 것으로 레이블을 지정합니다.
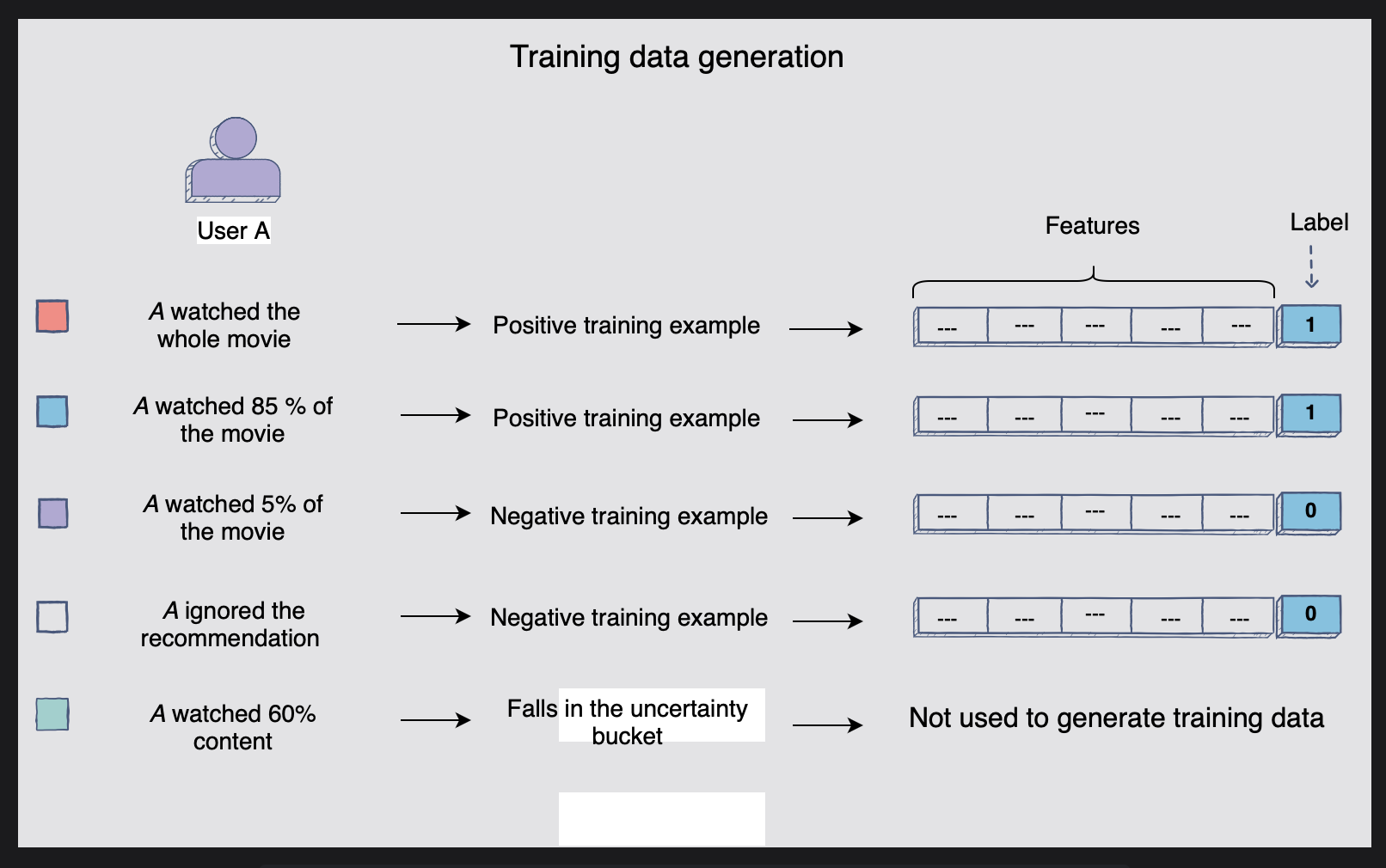
[그림] 사용자 작업에서 생성되는 긍정적 및 부정적 훈련 사례
Balancing positive and negative training examples (긍정 예시와 부정 예시 균형 맞추기)
- 사용자가 로그인할 때마다 Netflix는 수많은 추천을 제공한다.
그러나 사용자는 모든 것을 볼 수 없다. 사람들은 Netflix에서 몰아보기를 하지만, 그래도 긍정적인 경우와 부정적인 경우의 훈련 사례 비율이 크게 향상되지는 않는다.
따라서 긍정적인 훈련 사례보다 부정적인 훈련 사례가 훨씬 더 많다.
긍정 훈련 샘플과 부정 훈련 샘플의 비율 균형을 맞추기 위해 부정 샘플의 예를 무작위로 다운샘플링할 수 있다.
📝 분류기가 더 많은 예가 있는 결과를 선호하지 않도록 부정적인 예와 긍정적인 예의 균형을 맞춘다.
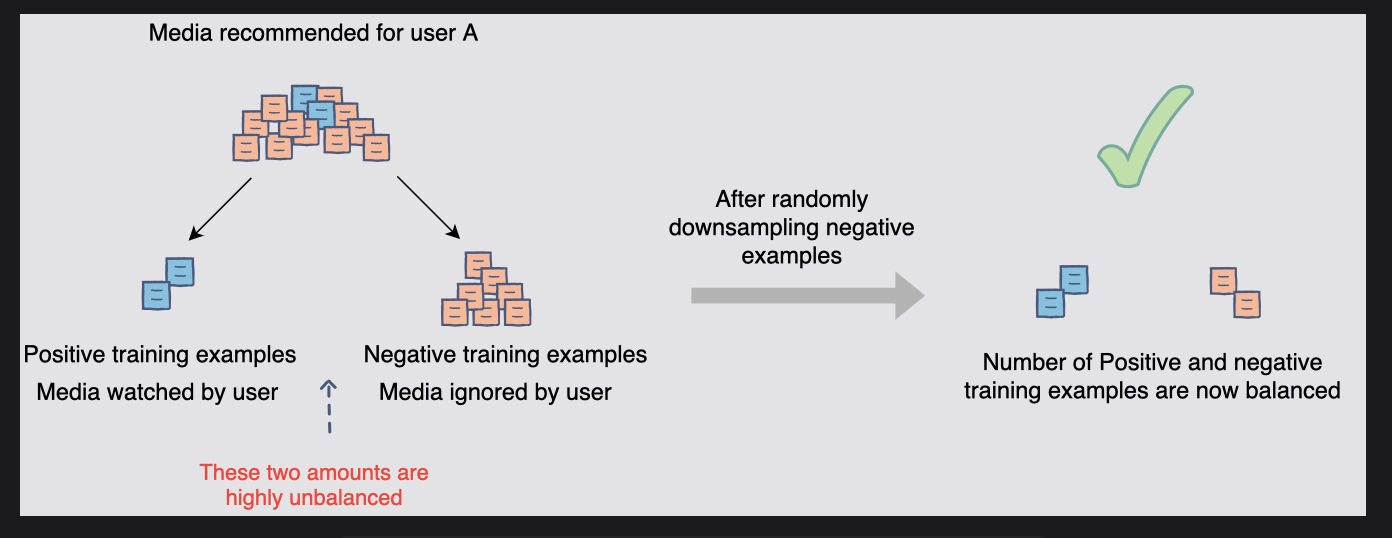
[그림] 긍정 예시와 부정 예시의 균형 맞추기
Weighting training examples (훈련 예제의 가중치)
지금까지의 학습 데이터에는 모든 학습 예제에 동일한 가중치가 적용된다.
즉, 모두 가중치가 1이다. Netflix의 비즈니스 목표에 따르면 주요 목표는 사용자가 플랫폼에서 보내는 시간을 늘리는 것일 수 있다.
세션 시청 시간에 대한 기여도가 더 높은 예시에 더 집중하도록 모델을 장려하는 한 가지 방법은 세션 시간에 대한 기여도를 기준으로 예시에 가중치를 부여하는 것이다.
여기서는 예측 모델의 최적화 함수가 목표에 따라 학습 샘플 당 가중치를 활용한다고 가정한다.
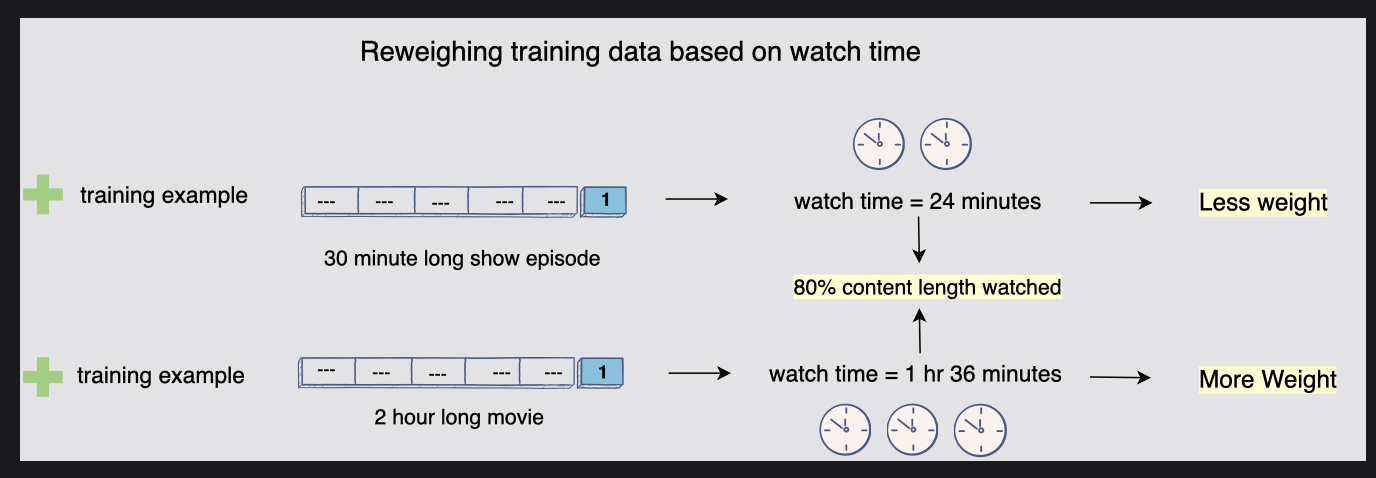
- 위 다이어그램에는 두 가지 긍정 훈련 예시가 있다.
첫 번째는 30분 길이의 쇼 에피소드이고 두 번째는 2시간 길이의 영화이다.
사용자가 시청한 두 미디어의 80% 시간은 쇼의 경우 이는 24분에 해당하지만 영화의 경우 1시간 36분이다.
모델이 어떤 종류의 미디어가 세션 시청 시간을 늘리는지 학습할 수 있도록 첫 번째 예보다 두 번째 예에 더 많은 가중치를 할당한다. 📝 이러한 가중치를 활용할 때 주의할 점은 모델이 시청 시간이 더 긴 콘텐츠만 추천할 수 있다는 것이다. 따라서 시청 시간에만 집중하지 않도록 가중치를 선택하는 것이 중요하다. 온라인 A/B 실험을 기반으로 사용자 만족도와 시청 시간 사이의 적절한 균형을 찾아야 한다.
Train test split
- 이제 모델 학습을 위해 훈련 데이터를 분할한 다음 모델을 테스트할 차례이다.
학습 하는 동안에 사용자의 상호 작용 패턴이 일주일 내내 다를 수 있다는 사실을 염두해야 한다. 따라서 일주일 내내 추천목록과 상호 작용을 사용하여 모델 학습 중에 모든 패턴을 캡쳐한다.
훈련 데이터 행 중 2/3, 즉 66.6%를 무작위로 선택하여 학습 목적으로 활용한다.
나머지 1/3, 즉 33.3%는 검증 및 모델 테스트에 사용될 수 있다.
그러나 이러한 무작위 분할은 일주일 전체 데이터에 대한 모델 학습 목적을 무효화한다. 또한 데이터에는 시간이라는 차원이 존재한다. 즉, 이전 추천과의 상호 작용을 알고 있으며 향후 추천과의 상호 작용을 예측하려고 하는 것이 목적이다.
- 따라서 한 시간 간격의 데이터에 대해 모델을 훈련하고 다음 시간 간격의 데이터에 대해 모델의 유효성을 검사한다. 이렇게 하면 모델이 실제 시나리오에서 어떻게 작동하는지 더 정확하게 파악할 수 있다.
📝 미래를 예측하려는 의도로 모델을 구축하고 있는 것이다.
다음 그림에서는 6월에 생성된 데이터를 학습 데이터로 사용하고, 검증 및 테스트 목적으로 7월 첫째 주와 둘째 주에 생성된 데이터를 사용한다.
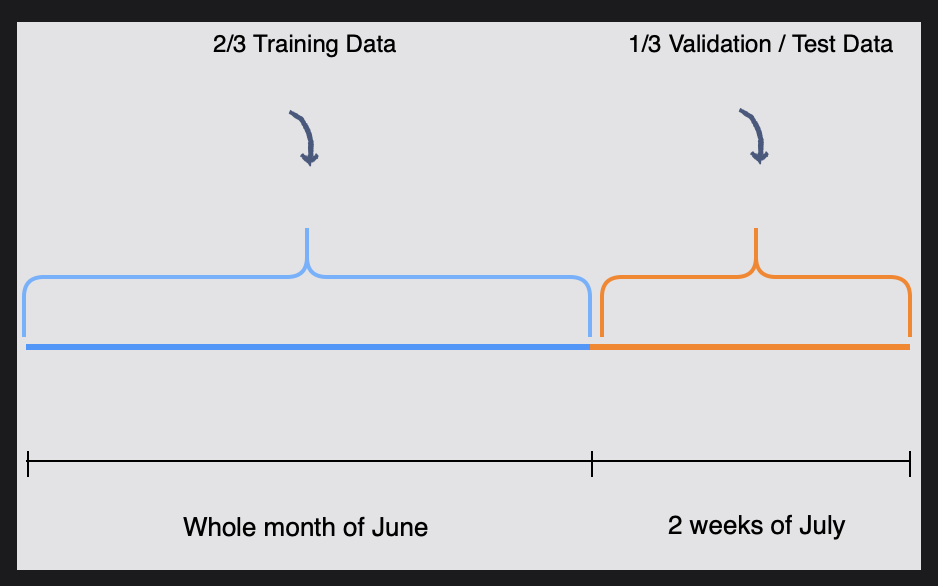
[그림] 학습(training), 검증(validation), 테스트(testing) 데이터 분할
Netflix의 가입자는 수백만 명에 달하지만 평균적으로 주당 최대 3편의 영화/1편의 프로그램을 시청할 수 있다. 따라서 충분한 양의 데이터를 생성하려면 데이터를 수집하는 기간을 늘려야 한다. 따라서 여기서는 모델을 훈련하기 위해 한 달 전체의 데이터를 사용한다.
참고사이트
