Human-level Performance
1. Human-level performance 배경
- Deep Learning의 발전으로 컴퓨터 성능이 인간의 성능과 견주어도 지지 않을 정도로 실효성이 입증 되었고, 이에 따라 사람과 컴퓨터간의 비교 연구가 진행되었다.
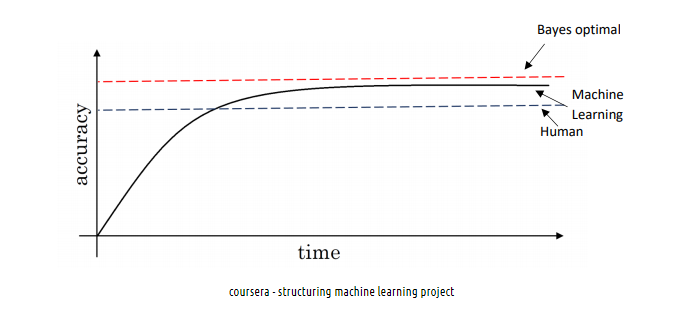
- 위 그래프는 시간에 따라 사람과 컴퓨터의 정확도 추이를 나타낸 것인데, 인간의 수준을 넘은 시점 부터는 컴퓨터 성능의 성장 속도가 줄어들고 Bayes opimal error를 능가하지 못한다.
- 컴퓨터가 인간의 수준을 넘어선 뒤로 성능 향상이 저조한 이유는, 인간의 수준이 Bayes error에 가깝고 컴퓨터가 인간 성능의 수준을 도달하지 못했을 경우 인간이 개입해서 성능을 끌어올릴 수 있기 때문이라고 한다.
- classification task에서, 사람의 에러가 Traning error 보다 낮다고 할 때, 우리는 variance를 줄이려고 노력할 텐데, Human-level의 performance는 Bayes error와 거의 근접해서 이를 사용해서 Model을 개선 방향을 정할 수 있다. (이때의 간격을 Avoidable Bias라고 함)
- 오늘날의 머신러닝 알고리즘은 human-level performance와 경쟁하는데, 사람이 거의 완벽에 가깝게 해내는 일이 있기 때문에 머신러닝은 human-level performance를 파악하고 이를 따라잡는 방향으로 학습이 이루어져야한다.
- 이때, human-level performane가 정의되어 있어야 함
2. human-level performance의 정의
-
human-level performance는 목적에 따라 다른데, 예를 들어 의학 이미지 분류에서의 에러율을 볼 때
일반인 에러율 3%, 일반 의사 에러율 1%, 경험 많은 의사 0.7%, 의사로 구성된 팀 0.5% 라고 했을때, 한 명의 의사의 인식률을 뛰어넘는 것이 목적이라면 일반 의사의 에러율이 human-level performance로 정의되고 bayes optimal error를 추정하기 위한 것이 목적이라면, 의사로 구성된 팀의 에러율이 human-level performance로 정의될 수 있다.
3. Avoidable bias
variance
- variance = validation error - training error
- 이론상으로는 엄청난 학습 데이터 상에서 학습 시킬 때 언제나 variance를 0에 가깝게 줄일 수 있으므로, 충분히 많은 데이터를 가지면 variance는 'avoidable' 하고 'unavoidable variance'는 존재하지 않음
bias
- Bias는 'Bias에 기여하는 오류' 이고,
- Bias = 이상적인 오류율('Unavoidable bias') + Avoidable bias
Avoidable bias (회피 가능한 bias)
-
avoidable bias를 이용해 bias를 줄여야 하느지, varaice를 줄여야 하는지 파악할 수 있다.
-
avoidable bias를 측정하기 위해서는 human-level error가 정의되어야 한다.
-
avoidable bias = training error - human level error (학습 오류와 이상적 오류와의 차이를 통해 계산됨)
: 이 값이 음수라면, 학습데이터에서의 성능이 이상적인 성능보다 좋은 것. 학습 데이터에 대해서 overfitting 되고 있다는 것이고, 알고리즘이 학습 데이터에 대해 너무 많이 기억하고 있다는 것이다. 이때는 bias를 줄이기보다 variance를 줄이는 방법에 초점을 맞춰야 함)
[1] avoidable bias > variance 라면
bias를 줄이는데 집중하여- layer 추가
- epoch 추가
- 더 나은 optimizer 사용
- 새로운 모델 시도
- hyperparamerter search
[2] avoidable bias < variance 라면,
varaince를 줄이는데 집중하여- regularization 추가 (dropout, L2 regulariztion)
- 학습 데이터 추가
- 새로운 모델 시도
- hyperparameter search
unavoidable bias (회피 불가능한 bias)
-
가장 좋은 머신러닝 모델도 10%의 오류를 가진다고 치면, 해당 오류는 알고리즘 bias에서 피할 수 없는 부분임
*variance
: 개발 데이터 오류와 학습 데이터 오류 간의 차이
조금 이해가 안되서, 예시로 작성한 어떤 게시물을 빌려 써보자면,
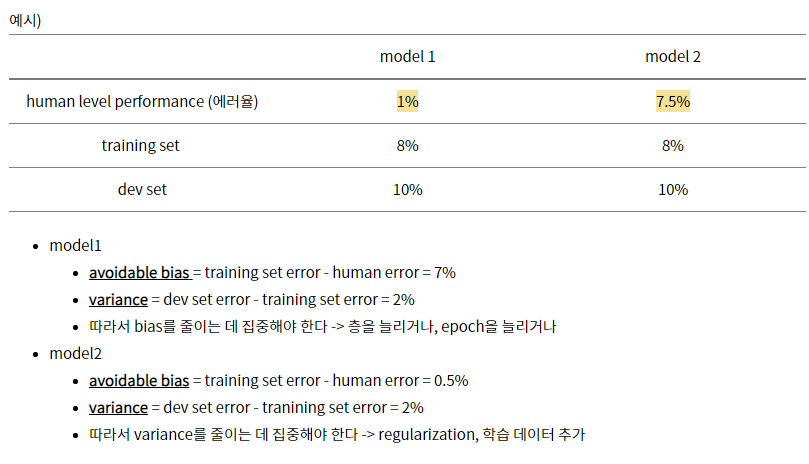
case 1.
- human-level performance 1%
- training error 8%
- dev error 10%
=> training set에서 알고리즘 성능과 인간의 차이가 매우 크다면 training set에서 잘 피팅되지 않으므로 bias 문제에 중점
: 해결점은 위의 bias 해결 방법 수행
(더 큰 신경망 train, 더 오래 train)
case 2.
- human-level performance 7.5%
- training error 8%
- dev error 10 %
=> training set 에서 알고리즘 성능과 인간과 차이가 매우 작음. variance 문제에 중점
: 해결점은 위의 variance 해결 방법 수행
(일반화 시도)
3. 이상적인 오류율
- 이상적인 오류율은 인간이 상대적으로 잘하는 작업에서 인간에게 시켜서 인간이 한 결과가 학습데이터 결과물에 비해 얼마나 정확한지 측정하면 됨
- 인간이 하기 어려운 작업은 추천 영화 예측 & 사람에게 어떤 광고를 보여줄지는 이상적인 오류율을 추정하기 어려울 수 있음
- human-level error를 bayes error의 추정치로 생각한다.
4. human-level performance의 이해
- 사례를 들어서 이야기해보자면, 0.7% 오류에 도달했을 때 bayes error를 추정하는데 신경쓰지 않은 이상, bayes error에서 얼마나 떨어져 있는지 알기가 어려운데 (위에서 의사팀 0.5%를 기반으로 bayes error를 추정해야 avoidable bias 측정이 가능함), 그래서 avoidable bias를 얼마나 줄여야 할지 모름
- human-level performance와 가까운 선상에 있는 경우, bias와 variance 효과를 제거하기가 굉장히 더 어렵고, 결과적으로는 지속적으로 머신러닝에서 발전을 이루기가 어려움
5. 정리
- human-level performance 추정치를 알면 bayes eror의 예상값을 알 수 있음
- 알고리즘에서 bias를 줄일지, variance를 줄일지 의사 결정 하기 쉬움 : 이런 테크닉은 human-level performance 를 도달하기 전까지 잘 작동함
이후에는 bayes error 추정 값을 구하기 어렵기 때문에 의사결정을 내리는데 어려움이 있음
참고사이트
