앙상블(Ensemble)
- Ensemble Learning
: 여러 개의 기본 모델을 활용하여 하나의 새로운 모델을 만들어내는 개념
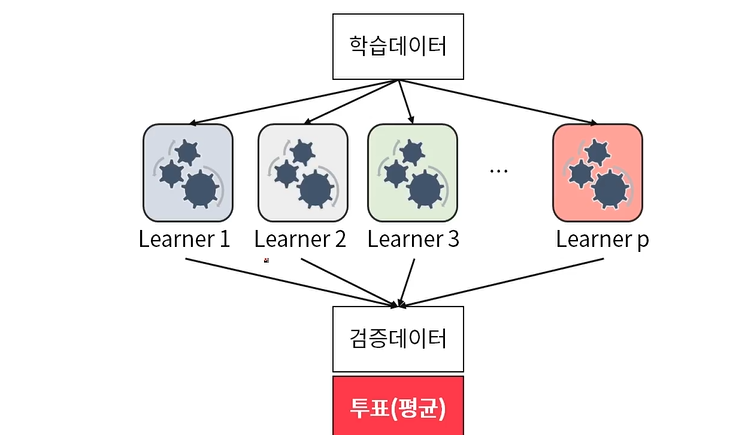
Test데이터에 대해 다양한 의견(예측값)을 수렴하기 위해 overfitting이 잘 되는 모델을 기본적으로 사용하며, Tree기반 모델 (Boosting,RandomForest)을 자주 사용한다. 즉, 앙상블의 기본 알고리즘으로 일반적으로 사용하는 것은 결정트리이다.
앙상블은 과적합(overfitting) 감소 효과가 있으며, 개별 모델 성능이 잘 안 나올 때 앙상블 학습을 이용하면 성능이 향상될 수 있다.
앙상블 학습의 유형은 전통적으로 보팅(Voting), 배깅(Bagging)과 부스팅(Boosting)이 있다.
1. 보팅(Voting)
보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식이다. 보팅의 경우, 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합하는 것이고, 배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행하는 것이다.
<보팅의 유형>
1) 하드 보팅: 다수결 원칙으로, 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정하는 것이다.
2)소프트 보팅: 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정한다. 일반적으로 소프트 보팅을 사용한다.
VotingClassifier
from sklearn.ensemble import VotingClassifier
#개별모델 생성(로지스틱 회귀, KNN)
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
#개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현
vo_clf= VotingClassifier(estimators = [('LR',lr_clf),('KNN',knn_clf)],voting='soft')
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2, random_state = 156)
#VotingClassifier 학습/예측/평가
vo_clf.fit(X_train,y_train)
pred=vo_clf.predict(X_test)
acc = accuracy_score(y_test,pred)
print(acc)2. 배깅(Bagging)
배깅(Bagging): 모델을 다양하게 만들기 위해 데이터를 재구성 즉, 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물 집계 (Aggregration).
따라서, 학습 데이터가 충분하지 않더라도 충분한 학습효과를 주어 높은 bias나 underfitting 문제, 높은 variance로 인한 overfitting문제를 해결하는데 도움을 준다.
Classification과 regression 모두 사용 가능하며, 주로 Decision Tree 에서 많이 사용하지만 어떤 알고리즘에도 사용 가능하다.
-Bootstrapping
: 반복복원추출
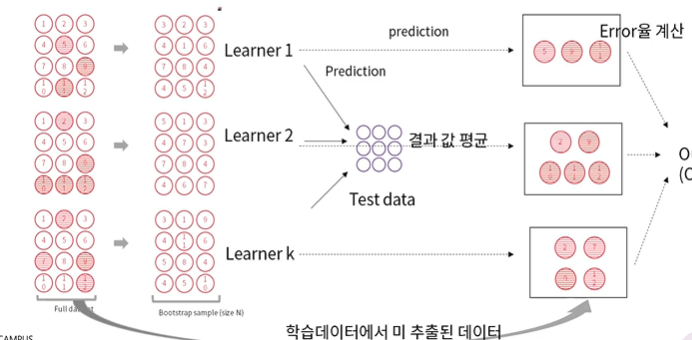
배깅의 대표적인 알고리즘: 랜덤 포레스트(Random Forest)
모델을 다양하게 만들기 위해 데이터뿐만 아니라, 변수도 재구성. 모델의 분산을 줄여 일반적으로 Bagging보다 성능이 좋음
Bagging Classifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
model=BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators = 10,
max_samples=1.0, max_features=1.0,
bootstrap=True,oob_score=False,random_state=100)
model.fit(X_train,y_train)
pred = model.predict(X_test)
accuracy = accuracy_score(y_test,pred)
f1 = f1_score(y_test,pred,average='macro')
print(f"f1:{f1:4f} accuracy:{accuracy:.4f}")랜덤 포레스트(Random Forest)
from sklearn.ensemble import RandomForestClassifier
X = data.data
y = data.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2, random_state = 156)
#랜덤 포레스트 학습/예측/평가
rf = RandomForestClassifier(random_state=0)
rf.fit(X_train,y_train)
pred = rf.predict(X_test)
acc = accuracy_score(y_test,pred)
print(acc)
랜덤 포레스트(Random Forest) 하이퍼 파라미터 및 튜닝
from sklearn.model_selection import GridSearchCV
#랜덤 포레스트 하이퍼 파라미터 튜닝
params = { 'n_estimators':[100],
'max_depth':[6,8,10,12],
'min_samples_leaf':[8,12,18],
'min_samples_split':[8,16,20]}
#랜덤 포래스트 객체 생성 후 gridsearchcv수행
rf=RandomForestClassifier(random_state=0,n_jobs=-1)
grid_cv=GridSearchCV(rf,param_grid=params,cv=2,n_jobs=-1)
grid_cv.fit(X_train,y_train)
pred=grid_cv.predict(X_test)
acc=accuracy_score(y_test,pred)
print(acc)
#gridsearchcv를 이용해 최적으로 학습된 estimator로 예측 수행
gb_pred=grid_cv.best_estimator_
pred = gb_pred.predict(X_test)
gb_acc=accuracy_score(y_test,pred)featureimportances 속성을 이용해 feature의 중요도를 살펴볼 수 있다.
Decision Tree (회귀 ver)
from sklearn.tree import DecisionTreeRegressor
decision_tree_model = DecisionTreeRegressor() # 의사결정나무 모형
tree_model1 = decision_tree_model.fit(train_x, train_y)
predict1 = tree_model1.predict(test_x)
print("RMSE: {}".format(sqrt(mean_squared_error(predict1, test_y)))) 
Bagging Decision Tree (회귀 ver)
bagging_decision_tree_model1 = BaggingRegressor(base_estimator =
decision_tree_model, n_estimators = 5, verbose = 1)
tree_model2 = bagging_decision_tree_model1.fit(train_x, train_y)
predict2 = tree_model2.predict(test_x) #
print("RMSE: {}".format(sqrt(mean_squared_error(predict2, test_y)))) 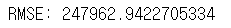
3. 부스팅(Boosting)
부스팅(Boosting): 오분류된 데이터에 초점을 맞추어 더 많은 가중치를 주는 방식 즉, 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법
초기에는 모든 데이터가 동일한 가중치를 가지지만, 각 round가 종료된 후 가중치와 중요도를 계산한다. 복원추출 시에 가중치 분포를 고려하며, 오분류된 데이터가 가중치를 더 얻게 됨에 따라 다음 round에서 더 많이 고려된다. Boosting기법으로는 AdaBoost,Gradient Boosting 등이 있다.
1) AdaBoost
: 오류 데이터에 가중치를 부여하면서 부스팅을 수행한다.
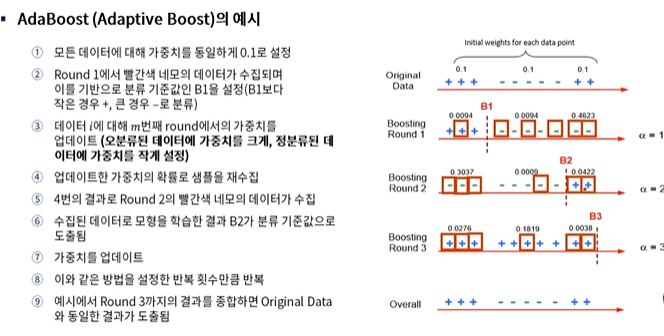
2) Gradient Boosting
: 이전 round의 합성 분류기의 데이터 별 오류를 예측하는 새로운 약한 분류기를 학습
(가중치 업데이트 방식: 경사 하강법(Gradient descent)을 사용)
경사하강법: 반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법
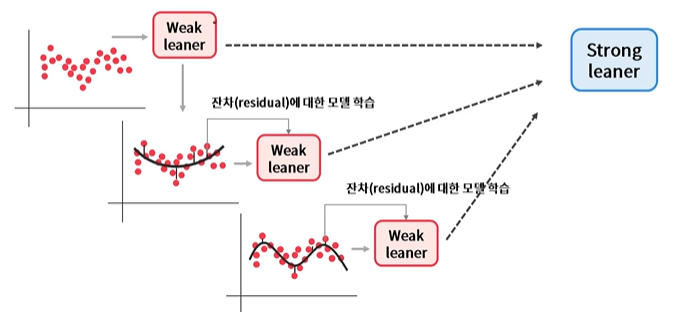
GradientBoostingClassifier 클래스 제공한다.
<Kaggle 등 데이터 경진대회 플랫폼에서 항상 상위권을 차지하는 알고리즘 XGBoost, LightGBM, CatBoost>
1. XGBoost
: Gradient Boosting 개념을 의사 결정 나무에 도입한 알고리즘으로 데이터 별 오류를 다음 round 학습에 반영시킨다는 측면에서 기존 Gradient Boosting과 큰 차이는 없다. 다만, XGBoost는 Gradient Boosting과는 달리 학습을 위한 목적식에 Regularization term이 추가되어 모델 과적합이 되는 것을 방지해 준다.
#사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
from sklearn.metrics import f1_score,accuracy_score
X = df[df.columns.difference(['Survived'])]
y= df['Survived']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1,random_state=42)
model = XGBClassifier(n_estimators=100,learning_rate=0.1,max_depth=5)
model.fit(X_train,y_train)
pred = model.predict(X_test)
accuracy = accuracy_score(y_test,pred)
f1 = f1_score(y_test,pred,average='macro')
print(f"f1:{f1:4f} accuracy:{accuracy:.4f}")
plot _importance( )로 feature importance 시각화 가능하다
from xgboost import plot_importance
import matplotlib.pyplot as plt
plot_importance(model)
plt.show()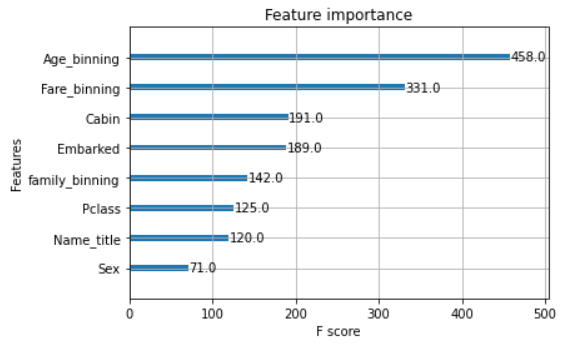
2. LightGBM
-XGboost와 다르게 leaf-wise loss사용한다. (loss를 더 줄일 수 있음)
-XGboost 대비 2배 이상 빠른 속도, GPU지원한다.
-overfitting에 민감하여, 다량의 학습데이터를 필요로 한다.
import lightgbm as lgb
from lightgbm import LGBMClassifier
from sklearn.metrics import f1_score,accuracy_score
X = df[df.columns.difference(['Survived'])]
y= df['Survived']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1,random_state=100)
model = LGBMClassifier(max_depth=5,learning_rate=0.1,n_estimators=100,
random_state=100)
model.fit(X_train,y_train)
pred = model.predict(X_test)
accuracy = accuracy_score(y_test,pred)
f1 = f1_score(y_test,pred,average='macro')
print(f"f1:{f1:4f} accuracy:{accuracy:.4f}")3. Catboost
-잔차 추정의 분산을 최소로 하면서 bias를 피하는 boosting 기법.
-관측치를 포함한 채로 boosting하지말고, 관측치를 뺀채로 학습해서 그 관측치에 대한 unbiased residual을 구하고 학습하자는 아이디어
-Categorical features가 많은 경우 잘 맞는다고 알려져 있음
-Categorical feature를 one-hot encoding방식이 아니라, 수치형으로 변환하는 방법을 제안.
일반적으로 성능은 CatBoost > LightGBM > XGBoost이다.
4. 스태킹(Stacking)
from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import VotingClassifier
model1 = [('rf',RandomForestClassifier()),('lr',LogisticRegression())]
model2 = RandomForestClassifier()
stacking_model = StackingClassifier(estimators=model1,final_estimator=model2,cv=5)
stacking_model.fit(X_train,y_train)
pred= stacking_model.predict(X_test)
accuracy=accuracy_score(y_test,pred)
f1=f1_score(y_test,pred,average='macro')
print(f'f1:{f1:.4f} accuracy:{accuracy:.4f}')
https://www.globhy.com/article/buying-horizontal-carbonized-bamboo-flooring-from-china-while-living-in-new-york
https://www.globhy.com/article/why-bamboo-flooring-is-the-eco-friendly-champion-of-sustainable-homes
https://www.hentai-foundry.com/user/bothbest/blogs/20350/Choosing-Bamboo-Flooring-for-My-London-Home
https://yamap.com/users/4784209
https://forum.iscev2024.ca/member.php?action=profile&uid=1357
https://my.usaflag.org/members/bothbest/profile/
https://myliveroom.com/bothbest
https://forum.geckos.ink/member.php?action=profile&uid=642
https://competitorcalendar.com/members/bothbest/profile/
https://www.fruitpickingjobs.com.au/forums/users/bothbest/
https://thefwa.com/profiles/bamboo-flooring
https://chanylib.ru/ru/forum/user/9508/
https://greenteam.app/bothbest
http://www.v0795.com/home.php?mod=space&uid=2304271
https://wearedevs.net/profile?uid=201358
https://www.templepurohit.com/forums/users/chinahousehold/
https://tutorialslink.com/member/FlooringBamboo/68089
https://www.tkaraoke.com/forums/profile/bothbest/
https://www.aipictors.com/users/bothbest
https://forum.index.hu/User/UserDescription?u=2129081
http://programujte.com/profil/75582-chinabamboo/
https://lamsn.com/home.php?mod=space&uid=1290622
https://nexusstem.co.uk/community/profile/chinabamboo/
https://brain-market.com/u/chinabamboo
https://malt-orden.info/userinfo.php?uid=414587
https://www.halaltrip.com/user/profile/255692/chinabamboo/
https://goodgame.ru/user/1698091
https://vcook.jp/users/42177
https://library.zortrax.com/members/china-bamboo/
https://aprenderfotografia.online/usuarios/chinabamboo/profile/
https://plaza.rakuten.co.jp/chinabamboo/
https://plaza.rakuten.co.jp/chinabamboo/diary/202508270000/
https://plaza.rakuten.co.jp/chinabamboo/diary/202508270001/
https://eternagame.org/players/538402
https://www.slmath.org/people/82724
https://www.aipictors.com/users/chinabambooflooring
https://vocal.media/authors/china-bamboo-bfc
https://www.giantbomb.com/profile/chinabamboo/
https://www.keedkean.com/member/44724.html?type=profile