1. 의사결정나무
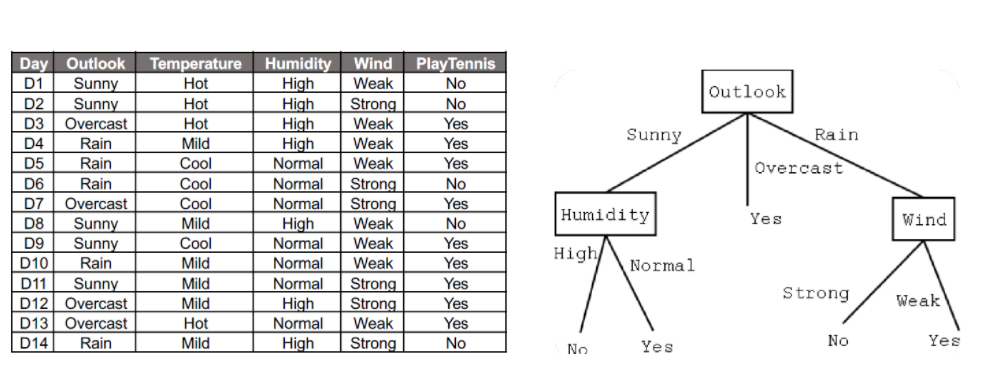
-
노드(node)란? 네모 칸 안에 있는 요소들로, 분류의 기준이 되는 위치
-parent node : 상위노드
-child node : 하위노드
-root node : 가장 상위 노드 (더이상 상위노드 없음)
-leaf node : 가장 아래의 노드 (더이상 하위노드 없음)
-internal node : leaf node가 아닌 노드예를 들어, 위 그림에서 Humidity의 parent node는 Outlook이 되고, Outlook의 child node는 Humidity, Wind가 된다.
-
반응변수에 따라
범주형 변수: 분류 트리
연속형 변수: 회귀 트리
의사결정나무 모델은 설명력이 좋기 때문에 설명이 필요한 경우에 주로 사용한다. 높은 정확도를 요구하며 예측 목적의 분석의 경우에는 회귀 트리보다는 회귀분석이나 신경망 알고리즘 등의 모델을 사용하는 것이 좋다. 한편 의사결정나무 모델은 과적합 발생 확률이 높다.
2. 엔트로피 (Entropy)
1) 불순도(Impurity)
: 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는가?
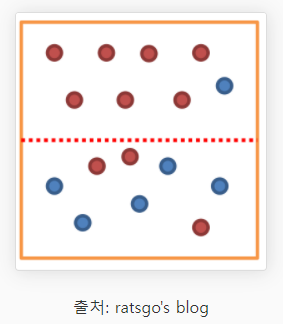
위 그림에서 위쪽 범주는 불순도가 낮고, 아래쪽 범주는 불순도가 높다. 한 범주에 하나의 데이터만 있다면 불순도가 최소이고, 한 범주 안에 서로 다른 두 데이터가 반반 있다면 불순도가 최대이다. 여기서 결정 트리는 불순도를 최소화하는 방향으로 학습을 진행한다.
2) 엔트로피(Entropy)
엔트로피(Entropy)는 불순도(Impurity)를 수치적으로 나타낸 척도.
엔트로피가 높다는 것은 불순도가 높다는 뜻이고, 엔트로피가 낮다는 것은 불순도가 낮다는 뜻이다. 엔트로피가 1이면 불순도가 최대, 0이면 불순도가 최소.
3. 정보 획득 (Information gain)
Information gain: 분기 이전의 엔트로피(parent)에서 분기 이후의 엔트로피(children)를 뺀 수치.
예를 들어, 엔트로피가 1인 상태에서 0.8인 상태로 바뀌었다면 information gain은 0.2이다.
<범주가 하나일 경우>
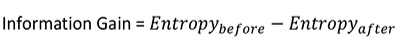
<범주가 두 개이상일 경우>
Information gain = entropy(before) - [weighted average] entropy(after)
: weighted average는 가중 평균으로, 범주가 2개 이상일 경우 가중 평균을 활용하여 분기 이후 엔트로피를 구한다.
결정 트리 알고리즘은 정보 획득을 최대화하는 방향으로 학습이 진행된다. 따라서 어느 feature의 어느 분기점에서 정보 획득이 최대화되는지 판단해야 한다.
4. CART(Classification And Regression Tree) 알고리즘
CART 알고리즘은 불순도를 지니계수(Gini Index)로 계산한다.
지니계수: 불순도를 측정하는 지표로서 데이터의 통계적 분산정도를 정량화해서 표현한 값
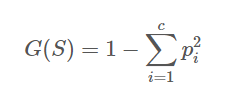
지니계수가 높을수록 데이터가 분산되어있음을 의미하며(낮을수록 좋은 것), 가장 낮은 지니계수를 가진 feature가 결정트리에서 root node가 된다.
