1. SVM
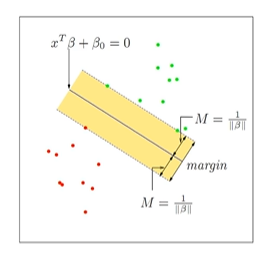
서포트 벡터 머신(SVM: Support Vector Machine)은 분류에 사용하는 머신러닝 지도학습 모델이다. 즉 Support Vector(각 클래스의 점들)를 사용하여 분류를 위한 기준 선, 결정 경계(Decision Boundary)을 정의하는 모델이다.
Margin은 결정 경계와 점선 사이의 거리를 의미하며 (결국 점선과 점선 사이의 거리), boundary의 결정은 각 분포로부터 margin을 최대화하는 것을 목표로 한다.
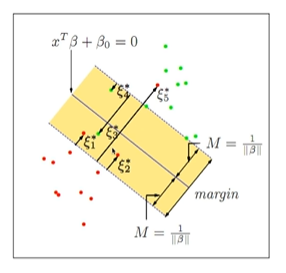
위 그림을 보면, boundary를 넘어선 다른 집단의 데이터가 분포한다. 이때 SVM은 적당한 error를 허용하며, error를 최소화하는 boundary를 결정한다.
2. SVC VS SVR
범주형 변수 : SVC(Support Vector Classification)
- Margin 안에 포함된 점들의 error를 기준으로 model cost를 계산
연속형 변수 : SVR(Support Vector Regression)
- 일정 Margin의 범위를 넘어선 점들에 대한 error를 기준으로 model cost를 계산
scikit-learn에서는 SVM모델의 error를 파라미터 c를 통해 지정할 수 있다.
classifier = SVC(C = 0.01)C값이 클수록 오류를 허용 안하고, 작을수록 오류를 허용한다.
*대개 선형으로 결정 경계를 그을 수 있지만, 아래와 같이 svm이 선형으로 분류할 수 없는 데이터가 있다면?
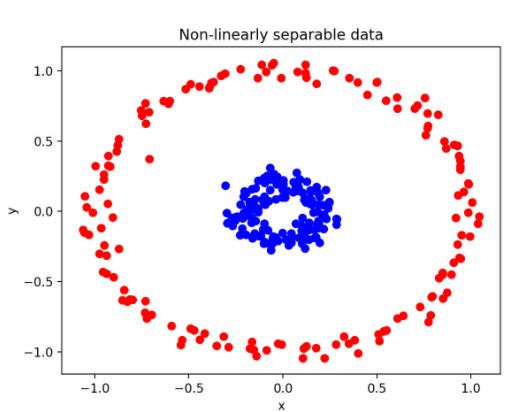
scikit-learn에서는 SVM 모델을 만들 때 kernel을 지정하여 해결할 수 있다.
즉, SVM에서는 선형으로 분리할 수 없는 점들을 분류하기 위해 kernel을 사용한다.
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear')kernel은 원래 가지고 있는 데이터에 더 높은 차원의 데이터로 변환한다.
다항식(polynomial) 커널은 3차원으로, RBF 커널은 점을 무한한 차원으로 변환한다.
kernel 값은 'rbf','linear', 'poly','sigmoid' 등 으로 지정할 수 있다.
