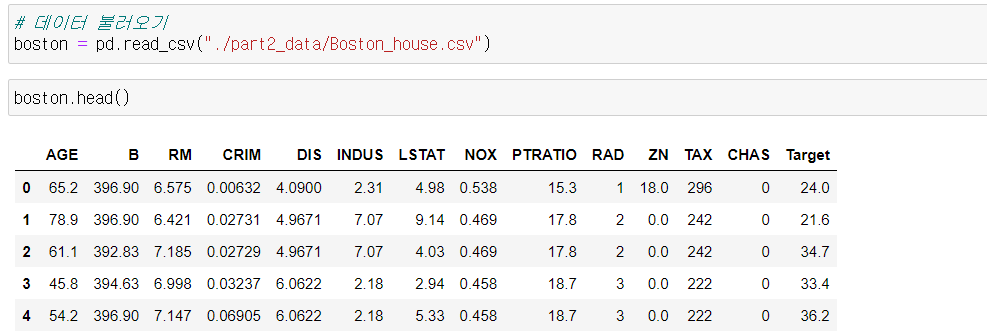
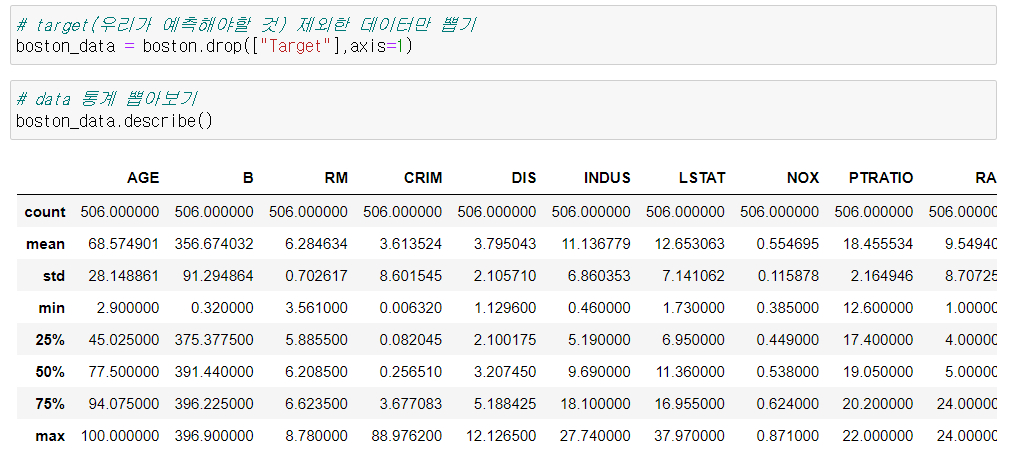
실습에 사용할 데이터 셋은 보스턴 집값 데이터로, 변수는 다음과 같다.
타겟 데이터
1978 보스턴 주택 가격
506개 타운의 주택 가격 중앙값 (단위 1,000 달러)
특징 데이터
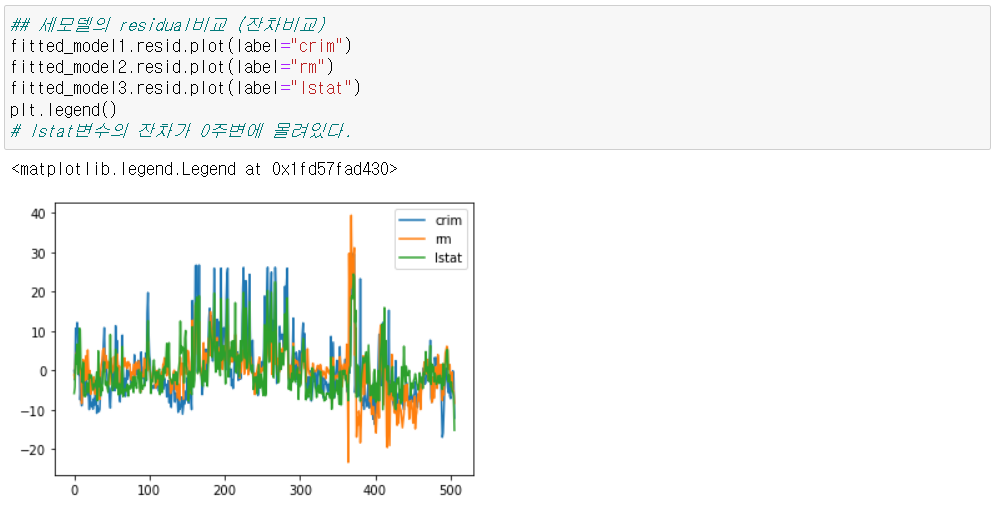
CRIM: 범죄율
INDUS: 비소매상업지역 면적 비율
NOX: 일산화질소 농도
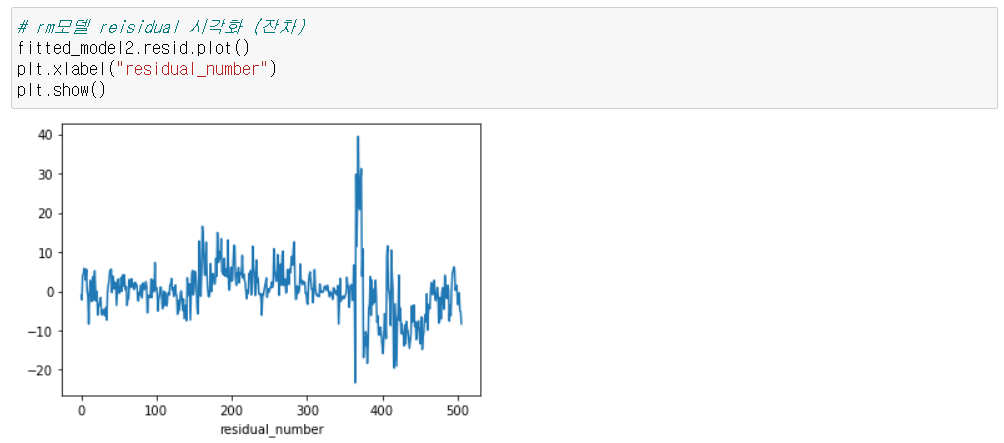
RM: 주택당 방 수
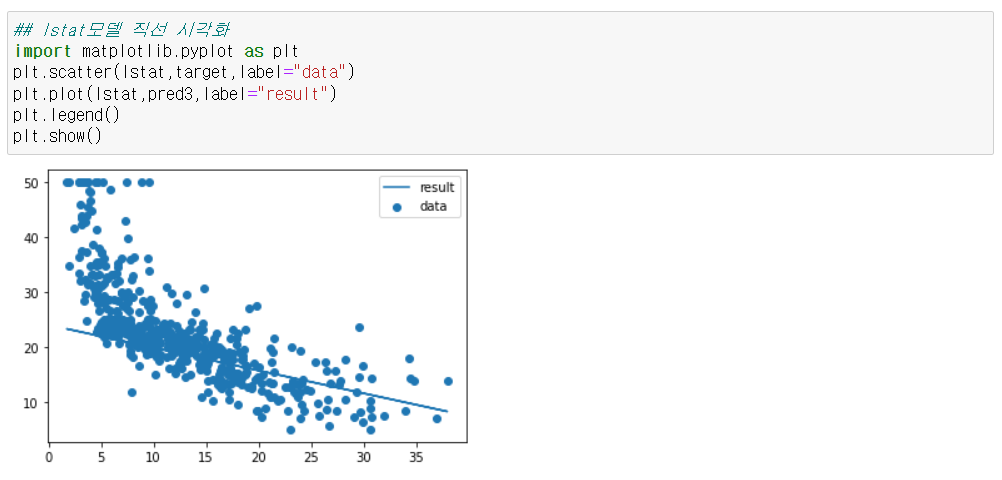
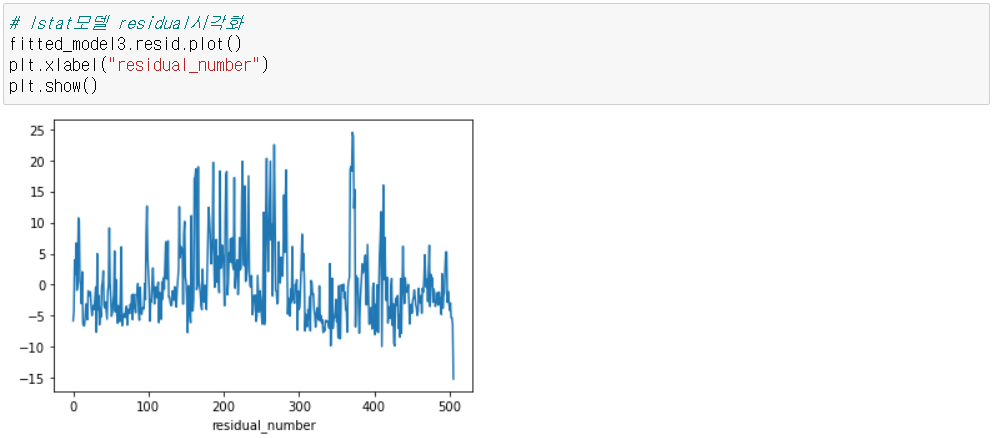
LSTAT: 인구 중 하위 계층 비율
B: 인구 중 흑인 비율
PTRATIO: 학생/교사 비율
ZN: 25,000 평방피트를 초과 거주지역 비율
CHAS: 찰스강의 경계에 위치한 경우는 1, 아니면 0
AGE: 1940년 이전에 건축된 주택의 비율
RAD: 방사형 고속도로까지의 거리
DIS: 직업센터의 거리
TAX: 재산세율- Statsmodels을 활용한 단순선형회귀분석

단순회귀분석 결과를 해석 할 때,
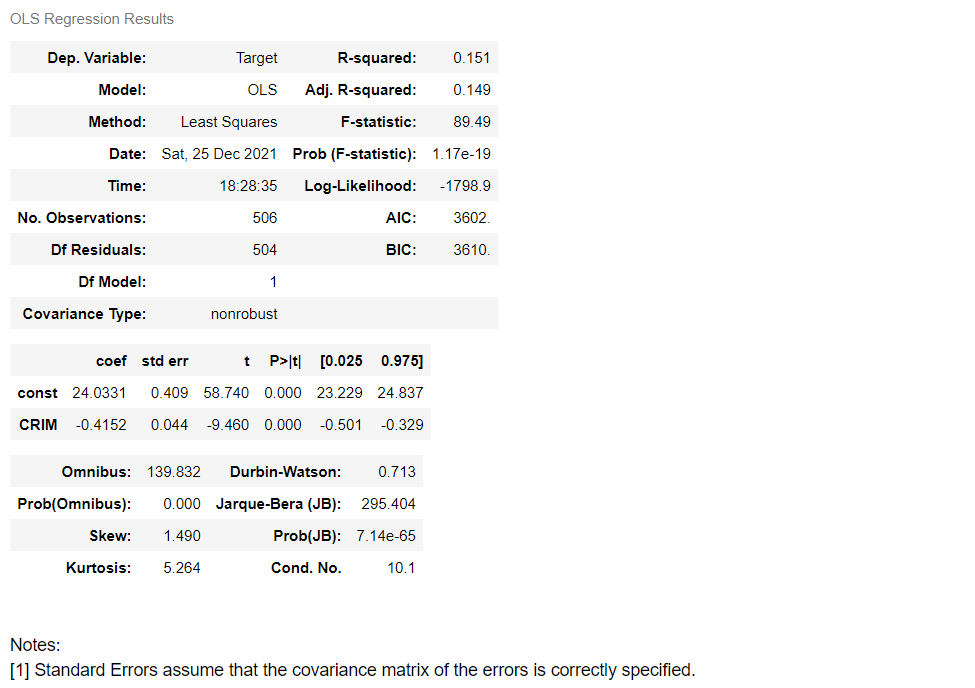
결정계수 확인>모형의 적합도 확인>회귀계수확인>t값과 t값의 유의확률 확인 순으로 해석을 진행한다.
먼저, R-squared값을 보면 0.151로 나와있는 것을 볼 수 있다. 이는 회귀모형의 설명력이 15.1%라는 뜻이다.실제로는 설명력이 조금 낮지만 실습이기 때문에 계속 회귀분석의 해석을 진행한다.
회귀모형의 F값이 89.49, 유의확률(Pr>F)은 0.000으로 통계적으로 유의한 모형인 것으로 나타났다.
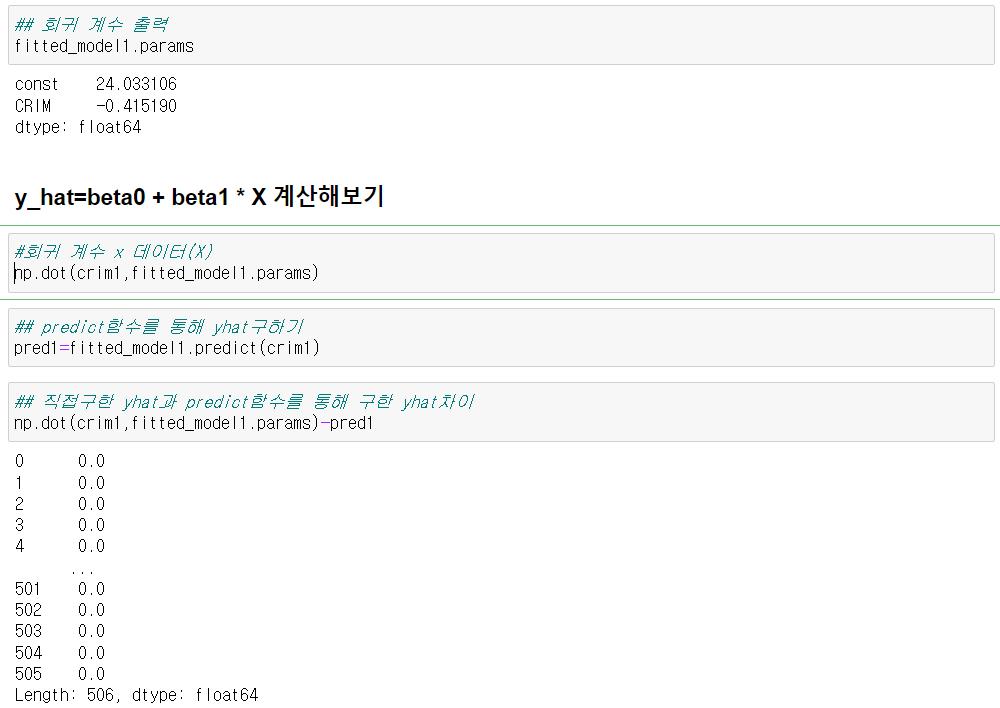
Intercept(절편)이란 모든 독립변수가 0일 경우에 예측되는 값을 말한다. 결과 중 Intercept(절편)의 t값은 58.740, P>|t|값은 0.000으로 이 회귀모형의 절편값은 유의한 것으로 나타났으며 그 값은 24.0331으로 나타났다.
CRIM의 t값은 -9.460, P>|t|값은 0.000으로 이 변수도 유의하여 CRIM의 계수는 -0.4152으로 도출됐다. 따라서 이 회귀모형의 식은 다음과 같다.
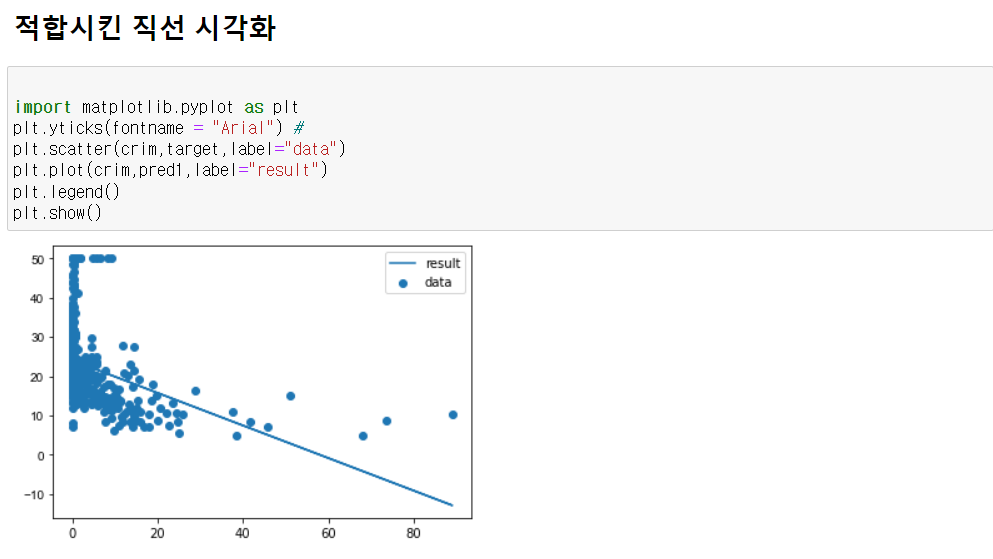
y= 24.033+(-0.415190*CRIM)



- sklearn을 활용한 단순선형회귀분석
- statsmodel과 sklearn차이
statsmodel의 경우, summary()사용 가능하며, 잔차와 학습 데이터에 대한 반응 변수의 추정값을 따로 계산하지 않아도 된다. 또한 전처리 과정 없이 데이터를 바로 모형이 적합할 수 있다.
반면 sklearn은 데이터 전처리해야 한다. (범주형 데이터)
