1. KNN (K-Nearest neighborhood)
데이터로부터 거리가 가까운 k개의 다른 데이터의 레이블을 기반하여 분류하는 알고리즘. 분류나 회귀를 할 때 사용한다.
-Distance d(a,b)의 선택
- 범주형 변수 : 해밍 거리
- 연속형 변수 : 유클리디안 거리, 맨하탄 거리
*과적합의 문제
-Training set을 가장 잘 맞히는 머신은 Test set에서는 잘 동작하지 않을 수 있다.
-Training error는 error를 과소추정하는 성향이 있다.
*k-겹 교차 검증 (K-Fold Cross Validation)
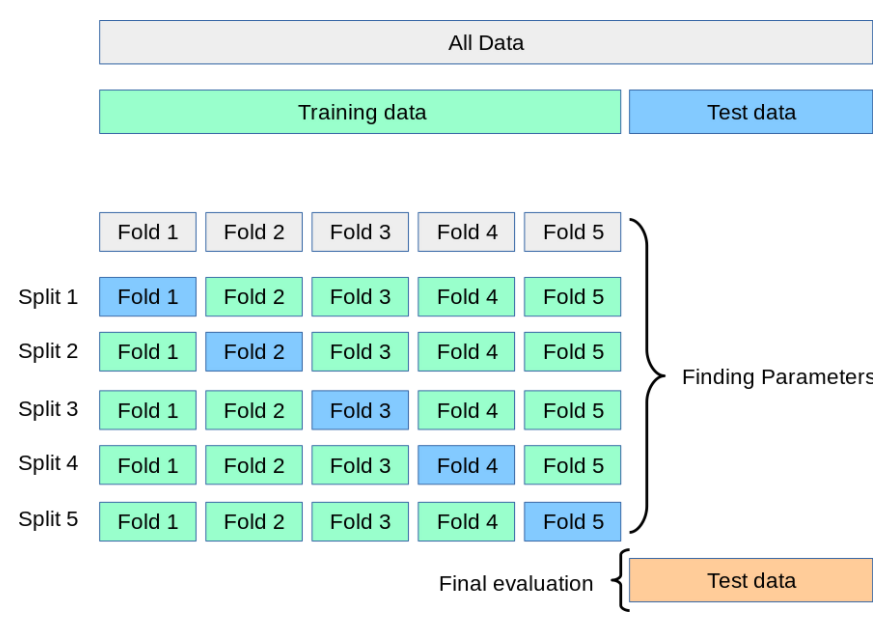
일반적으로 사용되는 교차 검증 방법 중 하나로, Training set과 Validation을 여러번 나눈 뒤 모델의 학습을 검증한다.
보통 회귀 모델에 사용되고, 데이터가 독립적이고 동일한 분포를 가질 때 사용한다.위 그림에서는 데이터를 K등분(5등분)한 뒤, 1/5를 검증데이터로 나머지 4/5를 학습데이터로 나누다. 각각의 1/5를 검증데이터로 바꾸며 성능을 평가한다. 그 결과 총 5개의 성능 결과가 나올 것이고 5개의 평균을 학습 모델의 성능이라 판단한다.
scikit learn의 cross_val_score을 활용해, 교차 검증을 통해 모델 학습을 진행하고 성능을 평가한다.
*계층별 k-겹 교차 검증 (Stratified k-fold cross validation)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
이 경우, 데이터셋을 나열 순서대로 k개의 폴드로 나누는 것은 항상 좋지만은 않으므로 이때 계층별 k-겹 교차검증을 활용한다. (분류일 경우 사용)
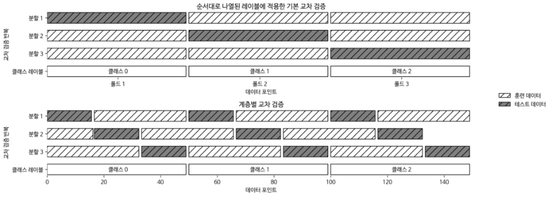
90%가 클래스 A, 10%가 클래스 B인 데이터라면 계층별 교차 검증은 각 폴드에 9:1 비율대로 만든다.
