나이브 베이즈 알고리즘은 텍스트 분류에서 많이 사용되는 알고리즘이다.
EX) 텍스트 출현 빈도 분류(정상메일/스팸메일) 확률을 각각 계산 후 확률이 더 높은 쪽으로 결과 출력.
1. Gaussian Naive Bayes
1) 데이터, 모듈 불러오기
from sklearn import datasets #내장 데이터셋 사용(iris와 같은)
from sklearn.naive_bayes import GaussianNB
import pandas as pdiris = datasets.load_iris() #샘플 데이터 load
df_X=pd.DataFrame(iris.data) # feature
df_Y=pd.DataFrame(iris.target) #labeldf_X.head()
df_Y.head()
2) 가우시안 나이브 베이즈 모델
gnb = GaussianNB() #가우시안 나이브 베이즈 모델
fitted=gnb.fit(iris.data,iris.target) #학습 시작
y_pred=fitted.predict(iris.data) #학습 결과를 기존 데이터에 적용fitted.predict_proba(iris.data)[[1,48,51,100]] #특정 변수의 결과 뽑기(확률)
predict_proba 함수는 각 샘플에 대해 어느 클래스에 속할 확률을 0에서 1 사이의 값으로 돌려준다.
위의 결과는 학습 결과를 확률로 나타낸 것으로, target은 0,1,2 총 3가지 경우가 있다.
1번째 데이터의 경우 0인 범주의 확률이 1이고, 48번째의 데이터의 경우 0인 범주의 확률이 1이다.
51번째의 데이터는 1인 범주의 확률이 0.94이고 100번째 데이터의 경우 2인 범주일 확률이 1이다.
fitted.predict(iris.data)[[1,48,51,100]] #특정 변수의 결과 뽑기(범주)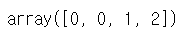
이는 예측한 범주를 출력한 것이다.
-Confusion matrix 구하기
from sklearn.metrics import confusion_matrix #혼동행렬
confusion_matrix(iris.target,y_pred)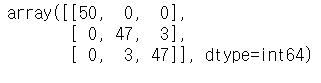
범주의 경우 3개의 오답이 발생한 것을 볼 수 있다.
-Prior 설정하기
나이브베이즈에서는 prior를 설정할 수 있다. 특정 결과의 출현확률이 더 많다고 가중치를 주는 행위이다.
# "2범주"에 prior를 주는 경우
gnb2=GaussianNB(priors=[1/100,1/100,98/100])
fitted2 = gnb2.fit(iris.data, iris.target)
y_pred2 = fitted2.predict(iris.data)
confusion_matrix(iris.target,y_pred2)
prior을 설정 안해주었을 때 보다 가중치를 높게 준 "2범주"의 정확도가 올랐다. (해당 범주의 오답 개수가 줄었음)
하지만 가중치가 낮아진 "1범주"의 경우 오답이 눈에 띄게 늘었다.
이처럼 가중치를 주는 prior 설정을 통해서 특정 범주의 정확성을 높일 수 있다. 그러나 이는 trade-off의 관계로 다른 범주의 정확성이 낮아진다.
2. Multinomial naive bayes
1) 데이터, 모듈 불러오기
iris 데이터는 연속형 Featue변수를 갖고 있기 때문에, 다항분포 나이브 베이즈를 실습할 수 없다. 따라서 난수를 생성하는 방식을 통해 Multinomial Naive Bayes모델을 실습한다.
from sklearn.naive_bayes import MultinomialNB # Multinomial Naive Bayes 라이브러리
import numpy as np # 난수생성을 위한 행렬 라이브러리
X = np.random.randint(5, size=(6, 100)) # 0부터 4까지 난수 생성, 변수 100개, sample size = 6
y = np.array([1, 2, 3, 4, 5, 6])2) Multinomial naive bayes 모델
clf = MultinomialNB()
clf.fit(X, y)print(clf.predict(X[2:3]))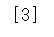
인덱스 "2"에 온 target(3)을 맞추었다.
clf.predict_proba(X[2:3])
x[2]는 "범주3"일때 확률이 1로 나타난다. 그 결과 3으로 예측을 한 것이고 이는 정답이다.
-Prior 설정하기
clf2 = MultinomialNB(class_prior = [0.1,0.5,0.1,0.1,0.1,0.1])
clf2.fit(X,y)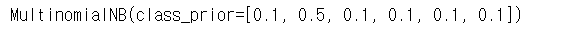
Multinomial Naive Bayes의 경우 parameter의 이름이 class_prior로 바뀌었다.
이번에는 범주가 "1"~"6"까지 6개가 있기에 prior 리스트에 6개 값을 넣었고 "범주 2"에 가중치를 주었으니, "범주2"의 확률이 올라갔을 것을 예측할 수 있다.
clf2.predict_proba(X[2:3]) 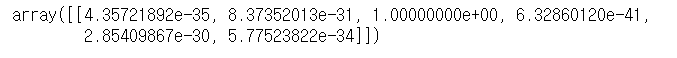
예측값은 "범주3"의 확률이 1로 가장 높다. 하지만, 자세히 보면 이전 .predict_proba() 결과와 비교해볼때, 가중치를 부여한 "범주2"의 확률이 5.872e-35에서 2.936e-34로 증가한 것을 확인할 수 있다.
