Preview
- 이번 장에서는 시퀀스 데이터를 학습하기 좋은 모델인 RNN계열 모델들을 공부해 볼 것이다.
- 기본 모델인 vanilla RNN과 vanilla RNN의 단점을 보안하기 위해 변형된 모델인 LSTM, GPU를 소개하겠다. 또한 pytorch로 구현된 LSTM을 분석해보겠다.(빠르게 각 모델들의 장단점만 보고 싶다면 결론부터 보자!)
- 또한 이런 RNN 모델들의 장단점을 알아본 후 다음 장에서는 RNN모델들의 단점을 보안하기 위한 seq2seq(sequence-to-sequence)와 seq2seq의 단점을 보안한 Attention계열 모델들을 다룰 예정이다.
이번 장에서는 시퀀스 단위로 학습이 진행되는 RNN모델을 공부해보겠다!
- RNN모델이란?
- RNN의 순전파
- RNN의 역전파
- LSTM모델이란?
- GRU모델이란?
- 결론! RNN계열 모델들의 장단점
RNN(Recurrent Neural Network)모델 이란?
RNN이란 과거의 정보를 사용하여 현재 및 미래의 입력에 대한 신경망의 성능을 개선하는 순환 신경망이다. 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델이며, 시퀀스란 문장과 같은 단어가 나열된 것을 의미한다.
RNN은 주로 시간에 의존적이거나 순차적인 sequential data를 학습하기 위해 활용되며, 내부에 있는 순환 구조에 의해 현재의 정보가 이전 정보에 쌓이면서 정보표현이 가능하다.
🆀 왜 RNN은 sequential data를 학습할 때 활용될까?
🅰 시퀀스 데이터는 독립동등분포 가정을 잘 위배한다. 즉, 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌기 과거 정보 또는 앞뒤 맥락 없이 미래를 예측하거나 문장을 완성하기 불가능하다.
또한 문장과 같은 시퀀스 데이터는 길이가 가변적이기 때문에 이를 잘 다룰 수 있는 RNN모델이 고안되었다.
- RNN의 기본 구조
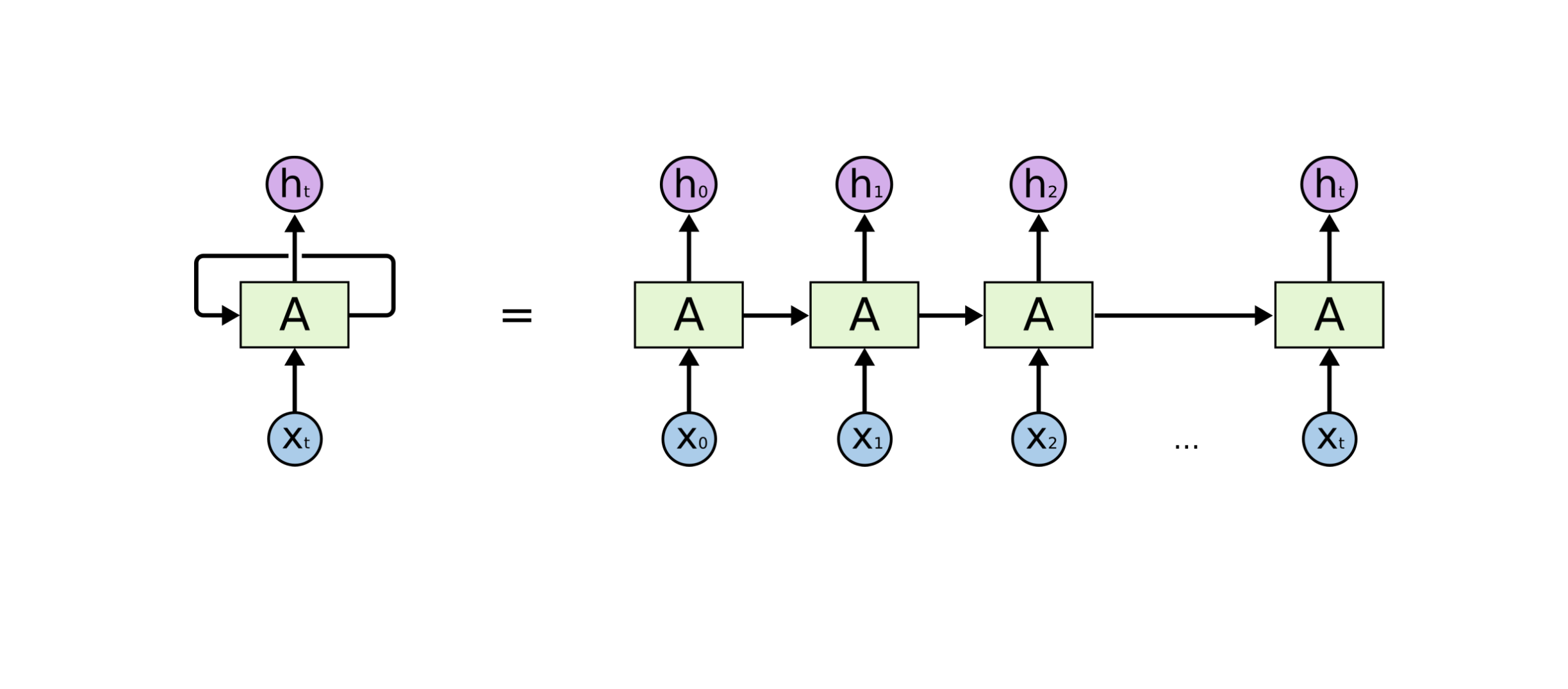
- RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이루고 있다.
- 현재 상태의 hidden state인 ht는 input 데이터인 xt와 직전 시점의 hidden state ht-1를 받아 갱신된다.
- 또한 위 그림의 x1... xt를 보면 시퀀스 길이에 관계없이 인풋과 아웃풋을 받아들일 수 있는 구조임을 알 수 있다.
- 이런 기본적인 RNN모델을 vanilla RNN으로 부른다(vanilla의 의미는 basic이라고 볼 수 있다)
🔜 RNN의 순전파
🆀 좀 더 구체적인 hidden state의 계산식은 어떻게 될까?
🅰 가장 기본적인 RNN 모형은 MLP(Multi Layer Perceptron)와 유사하다

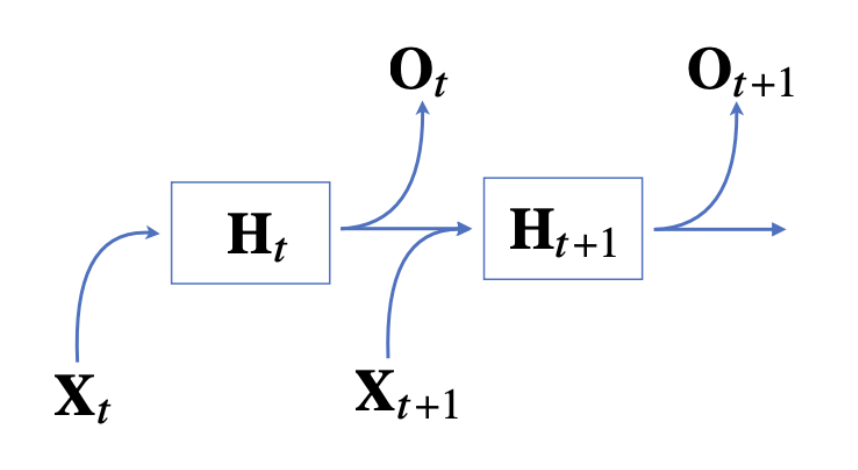
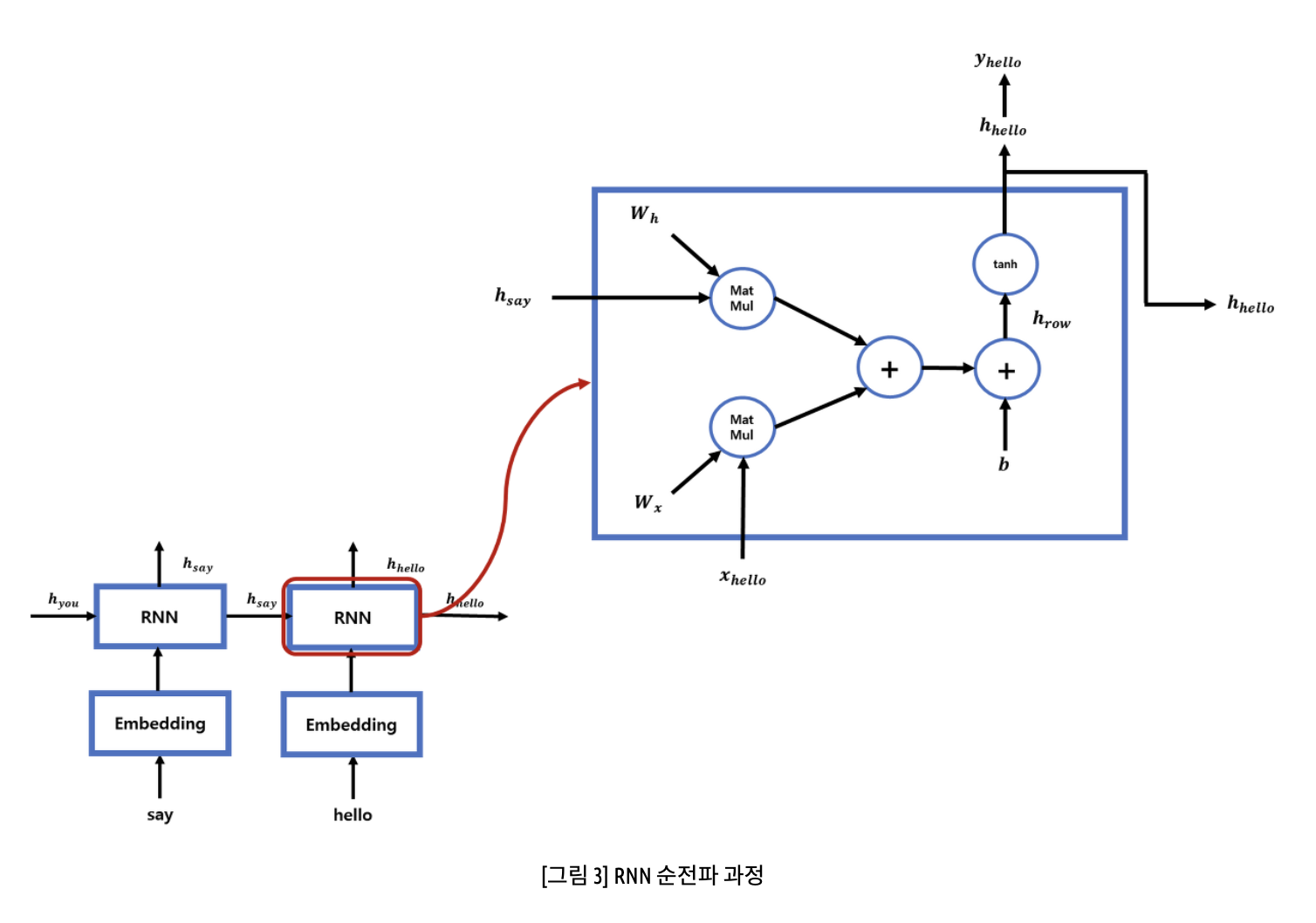
- 잠재변수 Ht는 입력값인Xt X 가중치 행렬, 그 전 잠재변수 Ht-1 X 가중치행렬, bias를 선형결합한 수식에 활성화 함수를 적용해준 값이다.
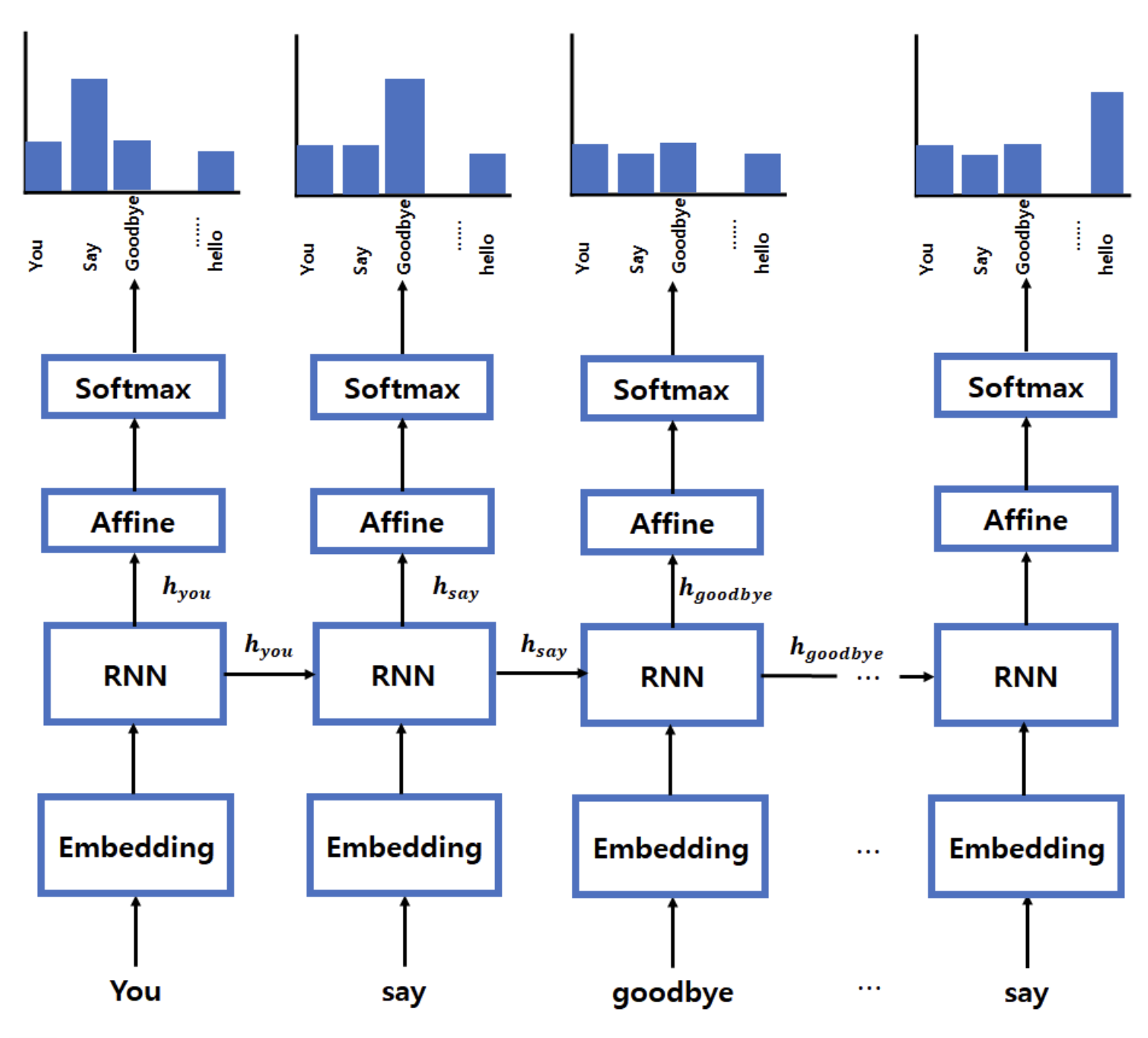
- 즉, RNN의 순전파 과정은 x1~xt까지 위와 같은 방식으로 이전 순서의 잠재 변수를 현재의 입력에 활용하여 각 입력에 대응되는 은닉상태 Ht(현재 시점까지의 정보)로 다음에 나올 값을 예측한다.
- 이때 활성화 함수는 tanh함수(하이터볼릭탄젠트)를 사용한다.
🆀 왜 활성화 함수는 tanh함수를 사용할까?
🅰 그 이유는 tanh는 기울기가 0~1이므로 sigmoid에 비해 미분값이 상대적으로 크기 때문에 기울기 소실 문제를 예방하는 장점있고, CNN과 달리 RNN은 이전 step값을 가져와서 사용하므로 ReLU를 사용하게 되면 이전 값이 커짐에 따라 전체적인 출력이 발산하기 때문이다.
🔙 RNN의 역전파
🆀 RNN의 역전파는 어떻게 이루어질까?
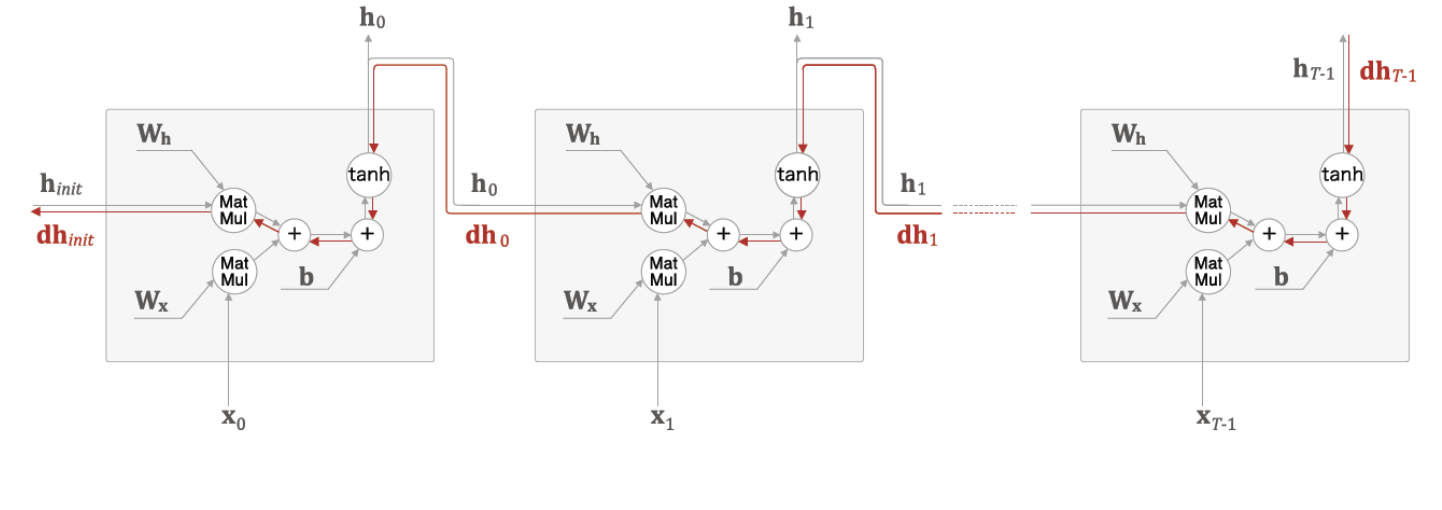
🅰 결론부터 말하면 RNN는 BPTT(Back Propagation Through Time)방식으로 역전파가 진행된다.
- RNN는 잠재변수의 연결그래프를 역순으로 계산하는데 기존 Back Propagation과 다르게 Through Time이 붙은 이유는 time step이 gradient에 영향을 주었기 때문이다.
- 즉, t시점의 gradient는 출력 부분의 이전 시점인 1~t-1시점의 gradient를 전부 더해야한다.
- BRTT를 통해 RNN의 가중치 행렬의 미분을 계산하면 아래와 같다
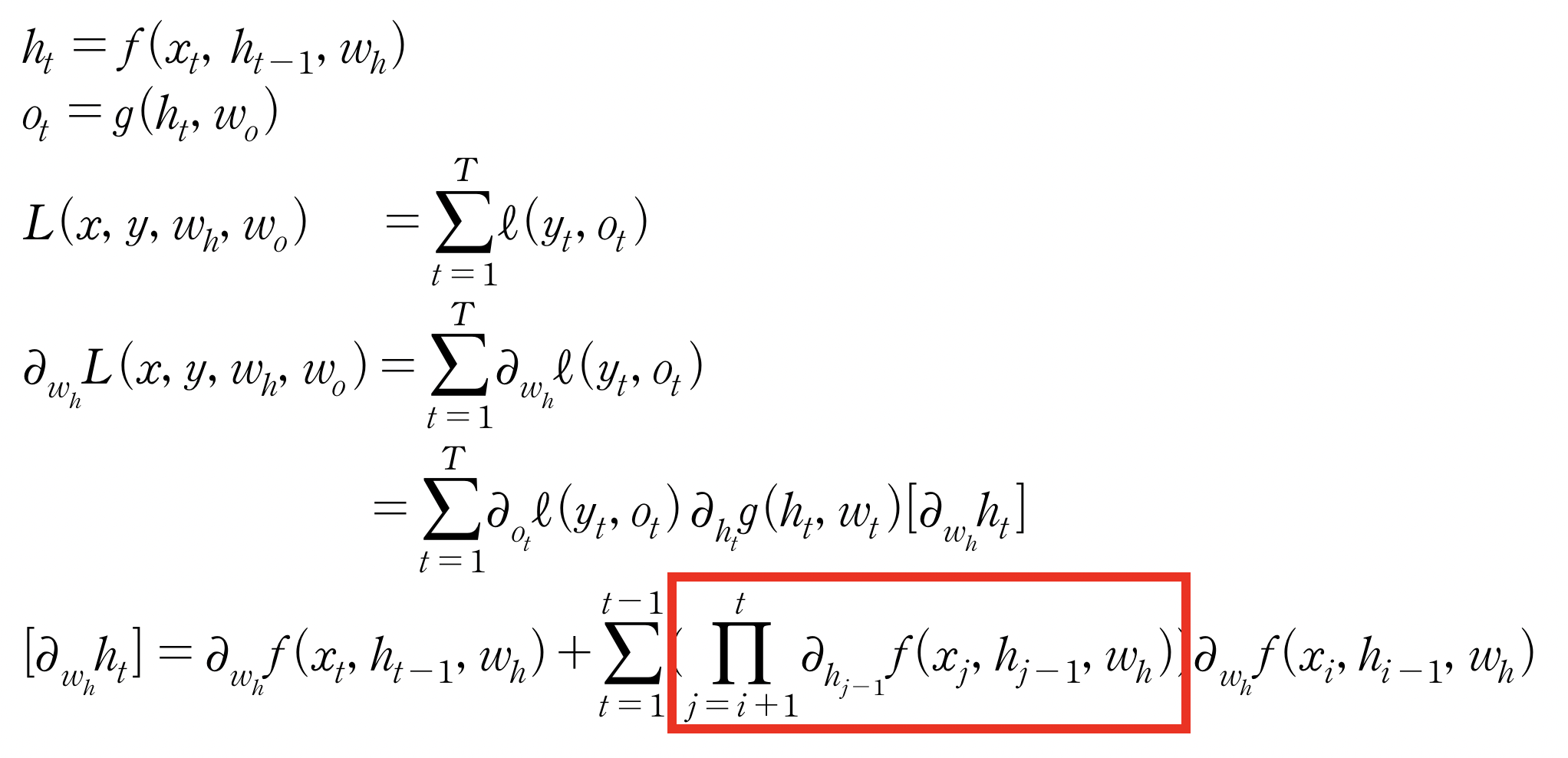
👉 이때 위에 빨간색 박스 친 부분을 보면 시퀀스 길이가 길어질 수록 해당 항이 불안해지기 쉽다.
- 역전파로 전해지는 기울기는 차례로 tanh와 곱의 연산을 통과하게 되고 BRTT는 과거에서 먼 시간으로 갈수록 전달되는 정보의 양이 점점 사라져간다.
- 역전파로 전달되는 기울값이 사라지는 기울기 소실 또는 기울기값이 너무 커져 파라미터 값이 터무늬 없이 커지는 기울기 폭발이 일어나기 때문이다.
- 즉, 시퀀스 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정해지므로 길이를 끊어주는 것이 필요하다
💁♀️ 이렇게 모델이 충분한 기억력을 갖지 못하는 문제를 장기 의존성 문제(the problems of long-term dependencies)라고 한다.
🆀 이런 장기 의존성 문제는 어떻게 해결할 수 있을까?
🅰 두 가지 방법으로 해결할 수 있다.
👉 첫번째 방법은 truncated BPTT을 이용하는 경우이다.
- 시퀀스 길이가 길어지는 경우 BRTT를 통한 역전파 계산이 불안정 해지므로 길이를 끊어내는 것이 필요하고 이렇게 길이를 끊어서 역전파를 계산하는 것을 truncated BPTT라고 한다. truncated BPTT를 이용한 모델은 TimeRNN이 있다.
👉 두번째 방법은 RNN의 장기 의존성 문제를 보안하기 위해 장단기 기억을 가능하게 하는 방법이다. 장단기 기억을 가능하게 설계한 모델은 LSTM와 GRU가 있다.
LSTM(Long Short-Term Memory model)모델이란?
LSTM (Long Short Term Memory)는 기존의 RNN이 출력과 먼 위치에 있는 정보를 기억할 수 없다는 단점을 보완하여 장/단기 기억을 가능하게 설계한 신경망의 구조를 말합니다. 주로 시계열 처리나, 자연어 처리에 사용됩니다.
🆀 LSTM은 어떤 방식으로 장, 단기 기억을 가능하게 할까?
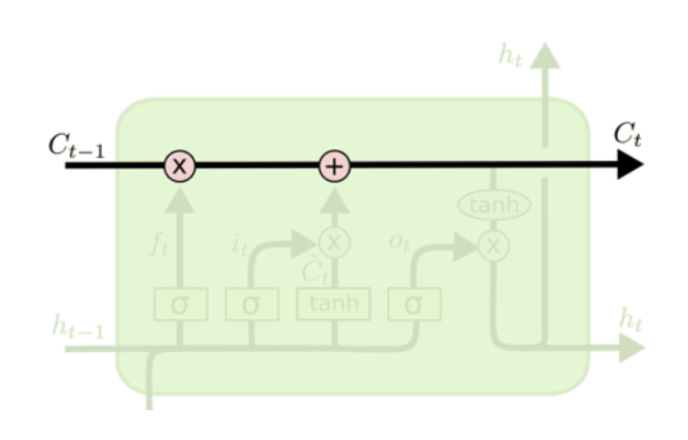
🅰 LSTM도 RNN과 같은 체인구조로 되어 있지만, 단순히 하나의 tanh layer가 아닌 cell state를 추가하여 Ht인 단기 상태(short-term state)와 ct인 장기 상태(long-term state)를 이용해 4개의 layer가 서로 정보를 주고 받는 구조로 되어 있다.
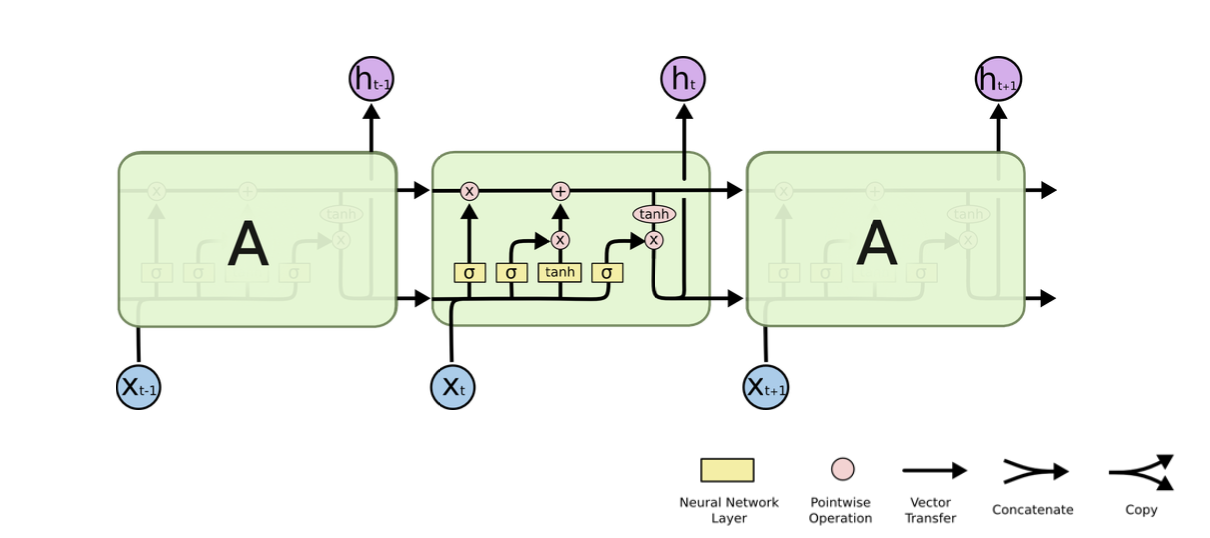
LSTM의 구조
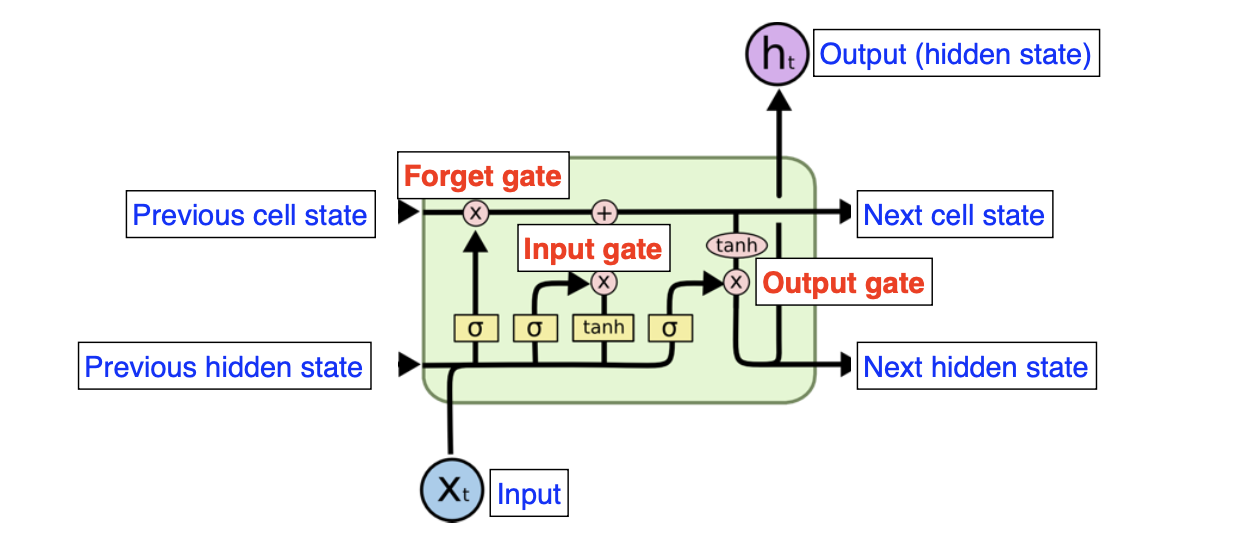
1. Cell state
Cell state는 정보가 바뀌지 않고 그대로 흐르도록 하는 역할이다.
2. Forget gate
Forget gate는 cell state에서 sigmoid layer를 거쳐 어떤 정보를 버릴 것인지 정합니다.
즉. 기존의 정보를 얼마나 잊어버릴지 결정하는 과정으로 sigmoid는 출력 범위가 0~1이기 때문에 들어오는 정보가 0에 가까우면 이전 상태의 정보를 거의 잊어버리고, 1에 가까우면 이전 상태의 정보를 많이 기억하게 됩니다.
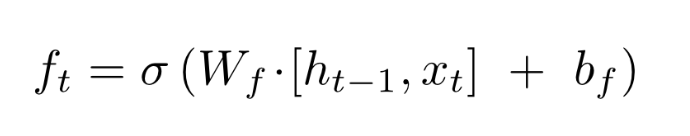

3. Input gate
Input gate는 앞으로 들어오는 새로운 정보 중 어떤 것을 cell state에 저장할 것인지를 정합니다. 먼저 Forget gate에서 ft를 계산한 것과 같이 xt와 ht-1값을 받아 sigmoid layer를 거치고, tanh layer에서 xt와 ht-1값을 받아 두개의 값을 곱하여 새로운 Vector를 만듭니다.
즉. 현재의 정보를 기억하기 위한 gate입니다.
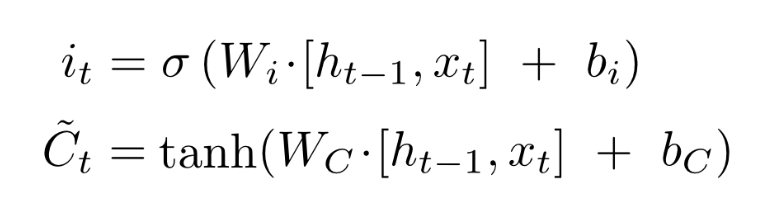

4. Cell state update
이전 Forget gate와 Input gate에서 버릴 정보들과 업데이트할 정보들을 정했다면, Cell state update 과정에서 이 둘의 값을 통해 업데이트를 진행합니다.
이전 Ct-1에 Forget gate에서 구한 ft를 곱해주고 Input gate에서 구한 새로운 Vector를 더해 Ct를 구합니다
즉. 기존의 정보를 얼만큼 잊고 새로운 정보를 얼만큼 대체할지 결정하는 과정입니다.
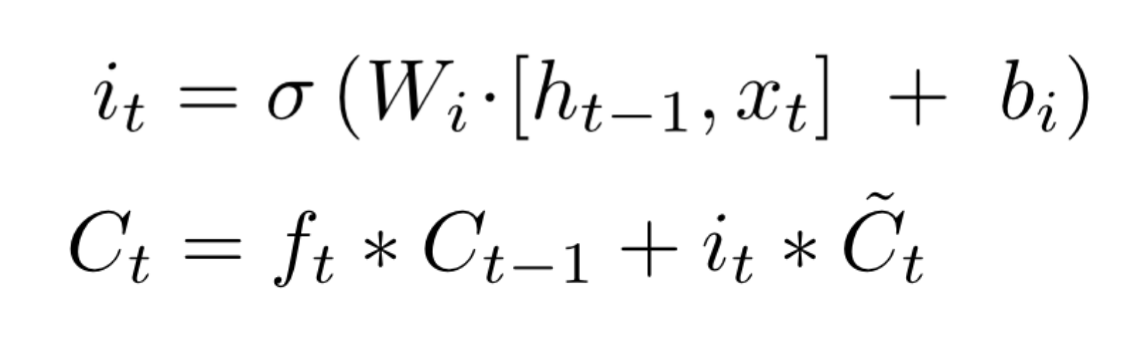
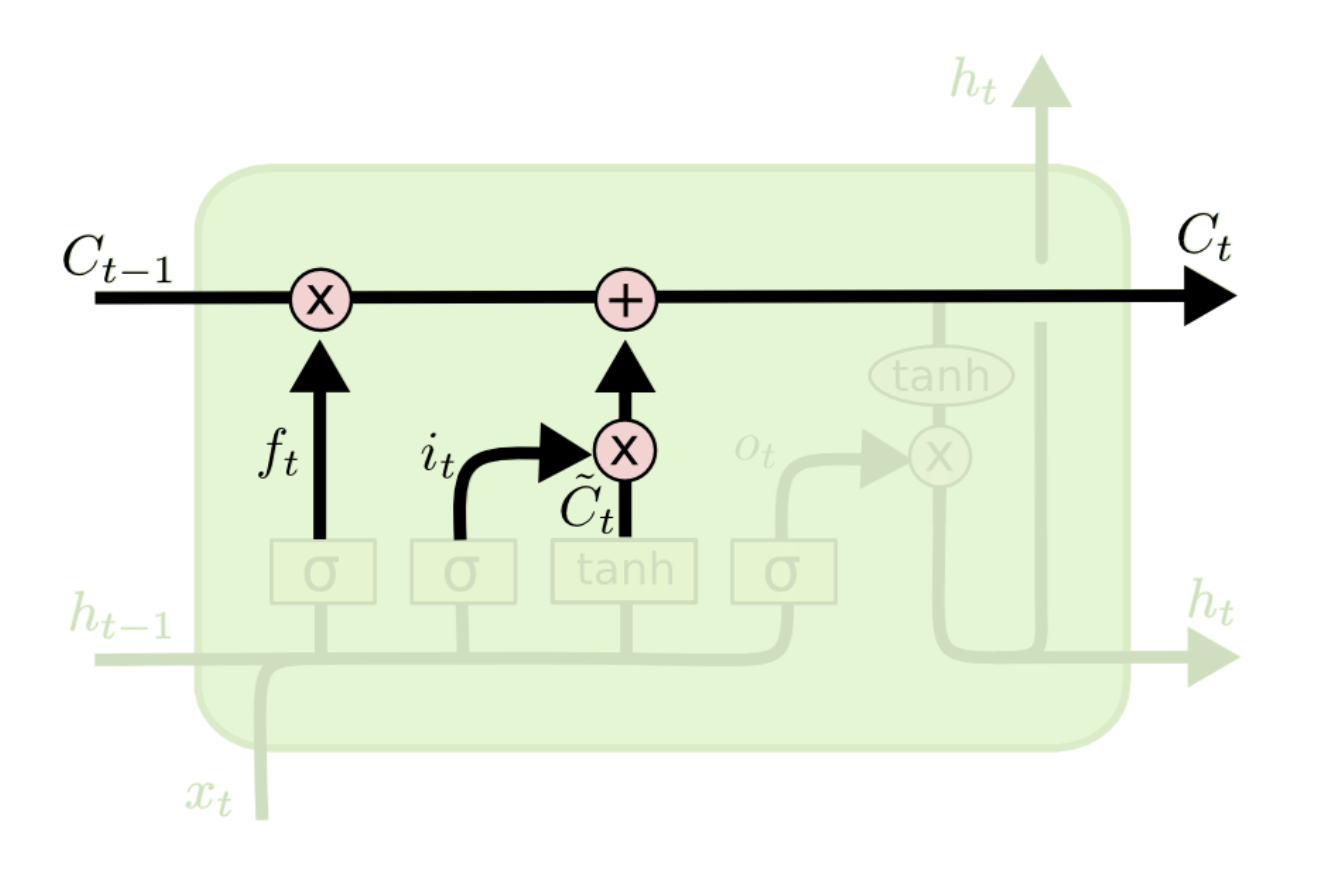
5. Output gate
Output gate는 어떤 정보를 output으로 내보낼지 정하게 됩니다. 먼저 Forget gate의 ft와 같이 sigmoid layer에 input data와 ht-1을 넣어 output 정보를 정한 후 Cell state update과정에서 구한 Ct를 tanh layer에 넣어 sigmoid layer의 output과 곱하여 ht를 구합니다
즉, Ct는 기억만 하는 것이 아닌 Ct를 받아 조정하여 Ht로 출력하게 됩니다.
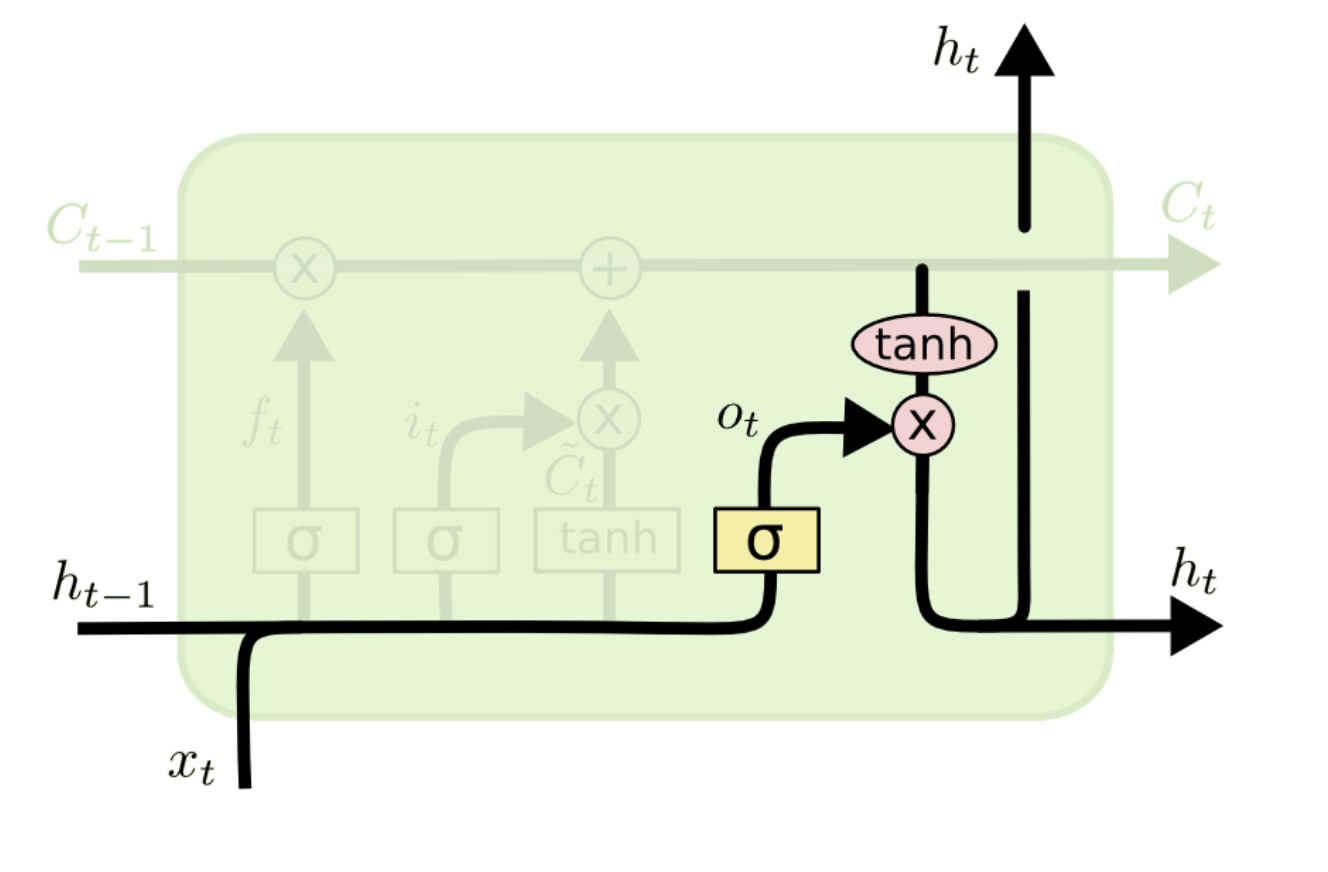
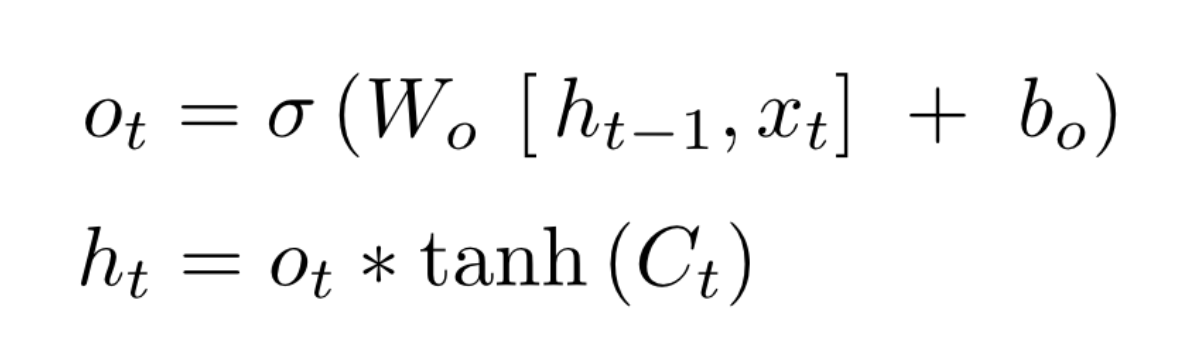
💁♀️ 즉. Ct(long term state)가 forget gate를 지나가면서 필요없는 데이터를 버리고, input gate를 지나가면서 새로운 데이터를 추가합니다. 그 후 Ct는 복사되어 output gate의 tanh 함수로 전달되어 ht와 yt를 만듭니다.
Pytorch로 LSTM 구현해보기
class RecurrentNeuralNetworkClass(nn.Module):
'''
- `N`: number of batches
- `L`: sequence lengh
- `Q`: input dim
- `K`: number of layers
- `D`: LSTM feature dimension
__init__
xdim : input의 dim -> D임, input data인 x.shape = (N , L , Q) : N - 배치사이즈, L - x의 시퀀스 길이, Q - input의 dim
hdim : hidden state의 개수
ydim : 최종 Output의 클래스 개수
n_layer : hidden state의 층 개수 -> K임
forward
h0 : 초기 hidden state, h0 shape = (K, N, D)
c0 : 초기 cell state(long term state), c0 shape = (K, N, D)
rnn_out : rnn연산 후 나온 output
hn : 마지막 hidden state
cn : 마지막 cell state
out : rnn_out의 가장 마지막 시퀀스 데이터를 선형변환한 ^y
'''
def __init__(self,name='rnn',xdim=28,hdim=256,ydim=10,n_layer=3):
super(RecurrentNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.n_layer = n_layer # K
self.rnn = nn.LSTM(input_size=self.xdim,
hidden_size=self.hdim,
num_layers=self.n_layer,
batch_first=True)
self.lin = nn.Linear(self.hdim,self.ydim)
def forward(self,x):
# Set initial hidden and cell states
h0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)# h0.shape = (K, N, D) -> (2,20,28) (num_layer, batchsize, hidden state의 개수)
c0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)# h0.shape = (K, N, D) -> (2,20,28) (num_layer, batchsize, hidden state의 개수)
# RNN
rnn_out,(hn,cn) = self.rnn(x, (h0,c0)) # x:[N x L x Q] => rnn_out:[N x L x D]
# Linear
out = self.lin(rnn_out[:,-1, :]).view([-1,self.ydim]) #rnn_out[:, -1, :] shape : (2, 256) -> y.shape = (2,10), view([-1,self.ydim])는 없어도 되는 코드지만 관습적으로 써줌
return out
R = RecurrentNeuralNetworkClass(name='rnn',xdim=28,hdim=256,ydim=10,n_layer=2).to(device)
loss = nn.CrossEntropyLoss()
optm = optim.Adam(R.parameters(),lr=1e-3)
print ("Done.")💁♀️ RecurrentNeuralNetworkClass의 파라미터를 출력해보면 아래와 같다

LSTM의 장단점
👉 장점
vanilla RNN은 단기 메모리만 가지고 recurrently 하게 학습을 진행 했다면 LSTM은 단기 메모리와 장기 메모리로 나누어서 학습 후 두 메모리를 합치기 때문에 과거의 정보를 훨씬 잘 반영한다.
👉 단점
하지만 이런 복잡한 구조 때문에 계산할 파라미터가 많아져 계산이 오래걸린다.
또한 파라미터가 많아지는데 데이터가 그에 비해 충분하지 않으면 over-fitting이 발생한다
💁♀️ LSTM의 성능은 유지하면서 계산을 줄이는 방법은 없을까? 바로 GPU이다
GRU(Gated Recurrent Unit)이란?
GRU(Gated Recurrent Unit)는 2014년 뉴욕대학교 조경현 교수님이 집필한 논문에서 제안되었습니다. GRU는 LSTM의 장기 의존성 문제에 대한 해결책을 유지하면서, 은닉 상태를 업데이트하는 계산을 줄였습니다. 다시 말해서, GRU는 성능은 LSTM과 유사하면서 복잡했던 LSTM의 구조를 간단화 시켰습니다.
LSTM에서는 출력, 입력, 삭제 게이트라는 3개의 게이트가 존재했습니다. 반면, GRU에서는 업데이트 게이트와 리셋 게이트 두 가지 게이트만이 존재합니다.
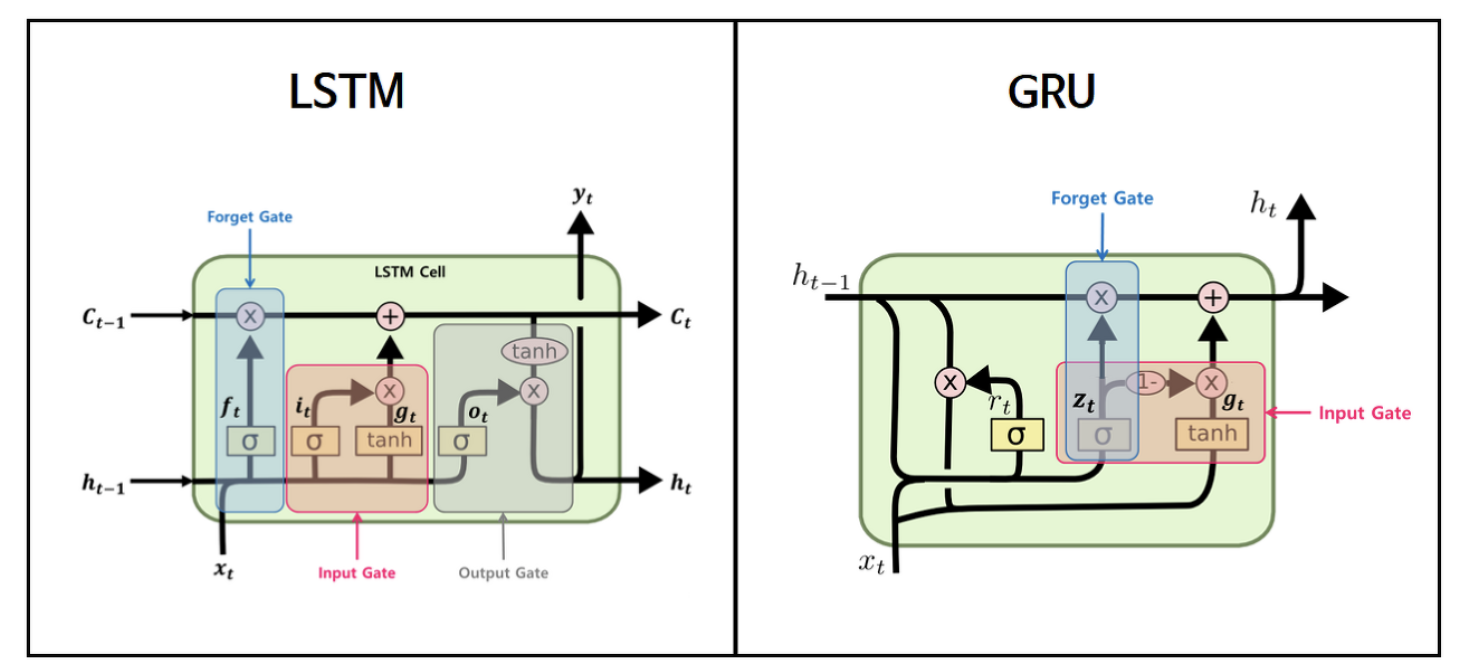
즉, GPU의 핵심은 LSTM의 forget gate와 input gate를 통합해 하나의 update gate를 만들고 Cell state와 Hidden state를 통합해 장기 의존성 문제는 해결하면서 계산을 줄였다.
GRU의 구조
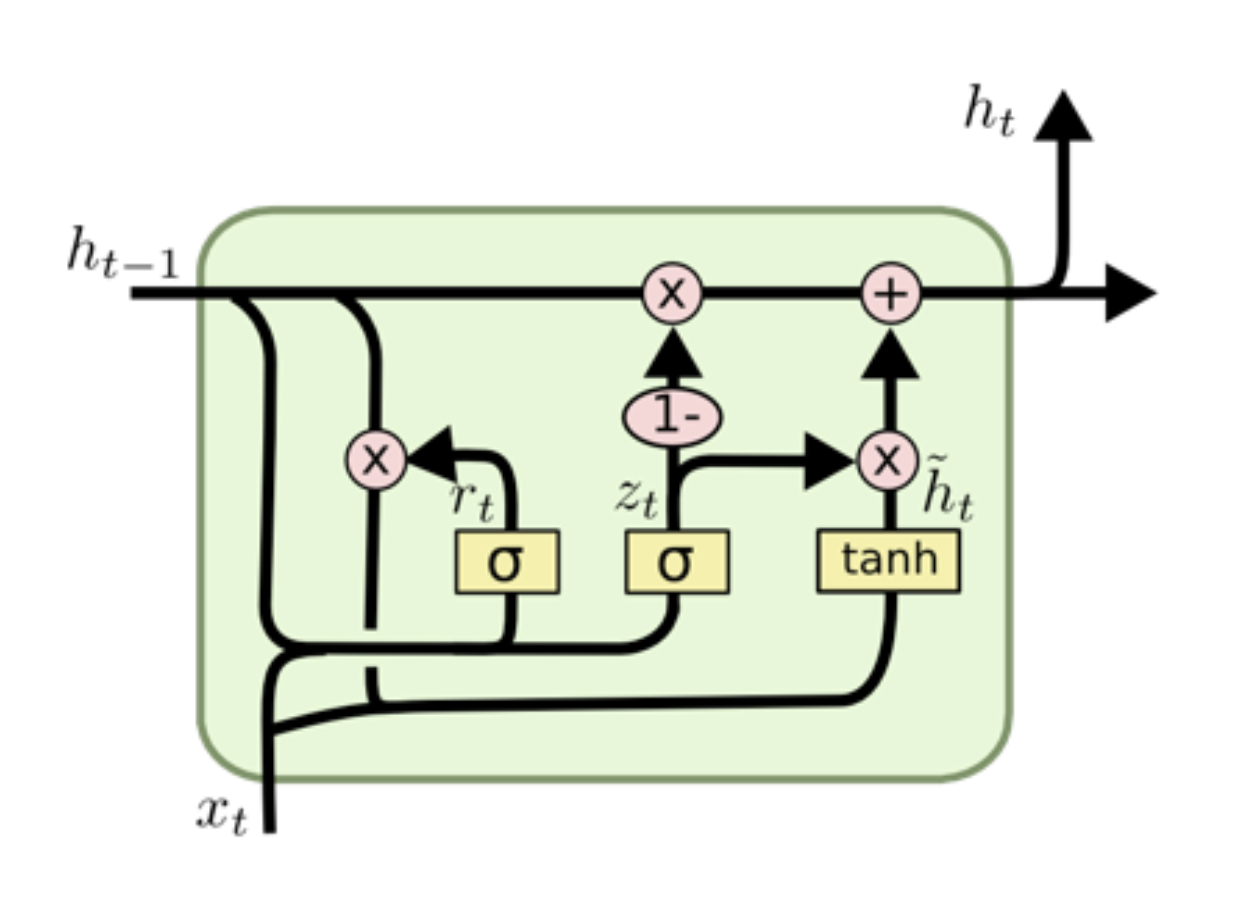
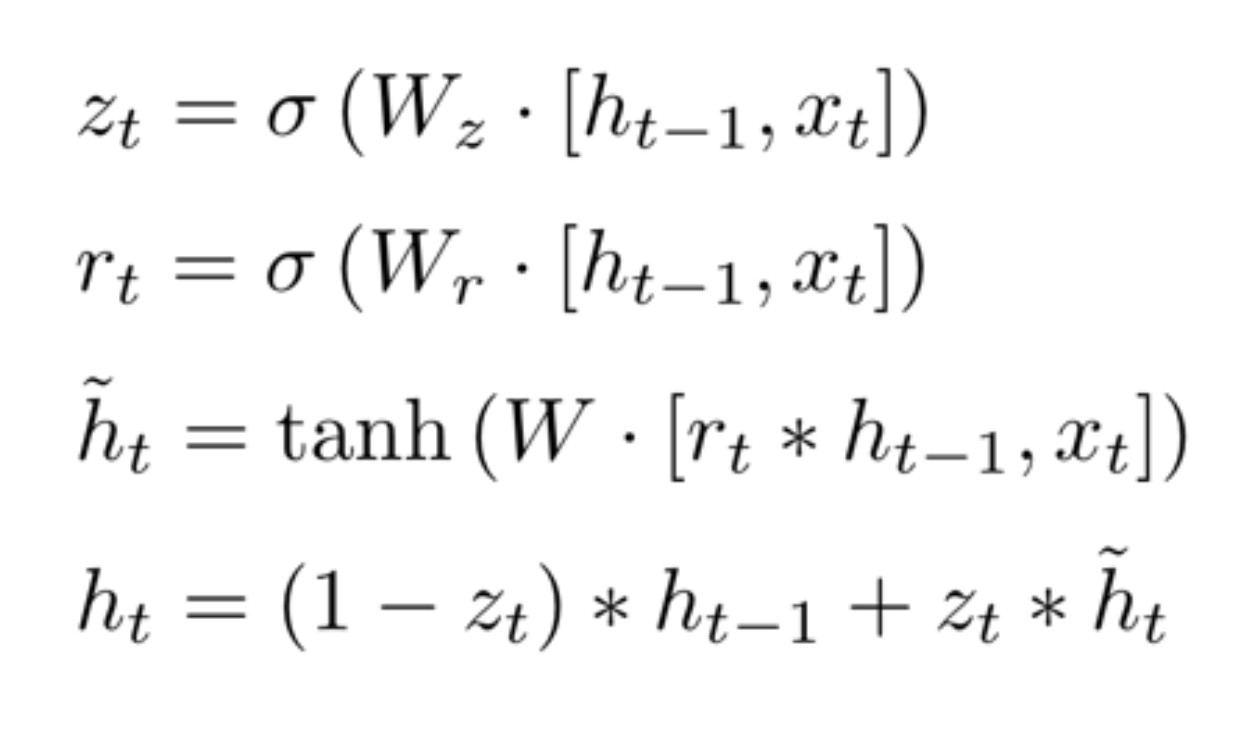
1. reset gate
reset gate는 이전 정보들을 적당히 리셋 시키는 것이 목적이므로 simoid를 통해 구현한다.
이렇게 구해진 rt는 이전 hidden state인 ht-1을 얼마나 활용할 건지에 대한 정보이다.
2. update gate
update gate는 이전, 현재의 정보를 얼마나 반영할 건지 비율을 구한다. 즉, LSTM의 input, forget gate와 비슷한 역할이다.
reset gate에서 구한 rt와 같이 zt를 구한 후 기존 정보인 ht-1와 곱한 후 현재 값 xt와 선형결합을 통한 값을 tanh 함수에 넣어 gt를 구한다
즉. zt는 과거의 정보를 얼만큼 사용할지에 대한 비율이고, (1-zt)는 현재 정보에 대한 비율로 볼 수 있다
ht는 현재 정보의 비율(1-zt)와 gt의 곱과 과거 정보의 비율(zt)와 이전 정보인 ht-1d의 곱을 합해 계산한다.
LSTM과 GRU 성능 비교
👉 GRU는 LSTM보다 학습 속도가 빠르다고 알려져있지만 여러 평가에서 GRU는 LSTM과 비슷한 성능을 보인다고 알려져 있다.
👉 경험적으로 데이터 양이 적을 때는 매개 변수의 양이 적은 GRU가 조금 더 낫고, 데이터 양이 더 많으면 LSTM이 더 낫다고도 한다.
👉 하지만 GRU와 LSTM 중 어떤 것이 모델의 성능면에서 더 낫다라고 단정지어 말할 수 없으며, 기존에 LSTM을 사용하면서 최적의 하이퍼파라미터를 찾아낸 상황이라면 굳이 GRU로 바꿔서 사용할 필요는 없다.
결론! RNN계열 모델들의 장단점
👉 RNN 계열 모델의 장점
- 과거의 정보를 기억하면서 가변적인 데이터를 잘 다룰 수 있기 때문에 시퀀스 데이터를 다루기 용이하다.
- vanilla RNN의 장기 의존성 문제를 해결하기 위해, LSTM이 고안되었고 LSTM의 많은 파라미터 계산을 줄이기 위해 GRU이 고안되며 RNN이 발전되었다.
👉 RNN 계열 모델의 단점
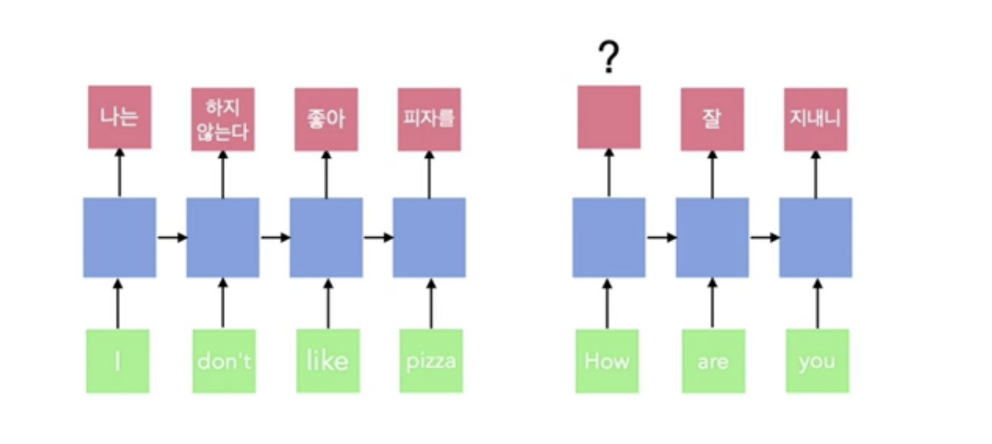
- RNN계열 모델은 입출력의 길이가 다를 경우 순서가 뒤섞이는 문제점이 있어 출력 길이를 조절할 수 있지만 들어오는 문장마다 출력의 길이를 바꿀순없기 때문에 many to many 번역 문제(how are you(3개 시퀀스) -> 잘 지내니(2개 시퀀스))를 해결하기 어렵다는 단점이 있다.
Epilogue
💁♀️ 이런 문제를 해결하기 위해 seq2seq(sequence-to-sequence)과 Attention기반 모델인 Transformer이 고안되었다 해당 모델들은 다음 장에서 다루도록 하겠다.
- 참고-
네이버 부스트캠프 AI Tech 5기 자료
RNN을 알아봅시다
밑바닥부터-시작하는 딥러닝2 6장
LSTM
장단기 메모리와 게이트 순환 유닛(LSTM and GRU)

좋은 글 더 보고싶어요