DeepLearning
1.🧠 딥러닝이란? | 내가보려고정리한AI🧐

앞으로 내가 AI에 대해 공부한 내용은 '내가보려고정리한AI🧐'시리즈에 정리하려고 한다. 블로깅을 하는 표면적인 이유는 내가 공부한 내용들을 AI에 관심있는 사람들에게 알려주기 위함이며 나의 지식을 공유하며 좀 더 심층적으로 공부하기 위한 목표를 가지고 있다.
2.🤖 Perceptron을 이해하고 Pytorch로 MLP 구현해보기 | 내가보려고정리한AI🧐
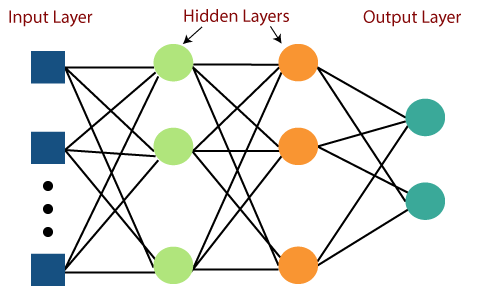
인공신경망의 시초가 되는 모델인 perceptron에 대해 알아보고 여러 Layer를 거치며 딥 해진 Multi-Layer Perceptron을 pytorch로 구현해보자!
3.⛰️ 최적화(Optimization)-1. 일반화(Generalization)편 | 내가보려고정리한AI🧐
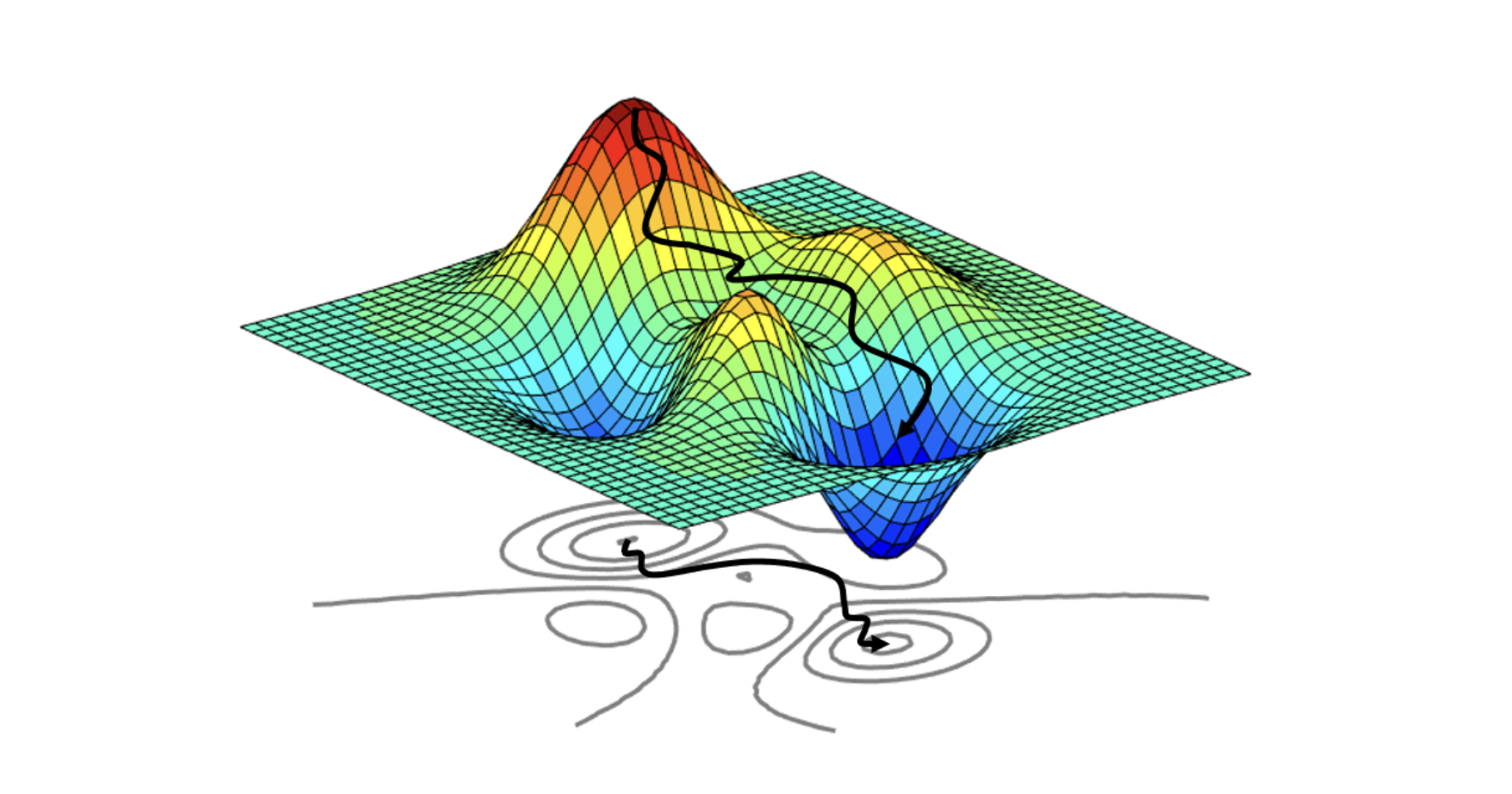
이전 장에서 신경망에 대해 알아봤다면 이번에는 신경망 학습의 목적인 최적화를 알아볼 것이다.
4.⛰️ 최적화(Optimization)-2. 경사하강법(Gradient descent)편 | 내가보려고정리한AI🧐
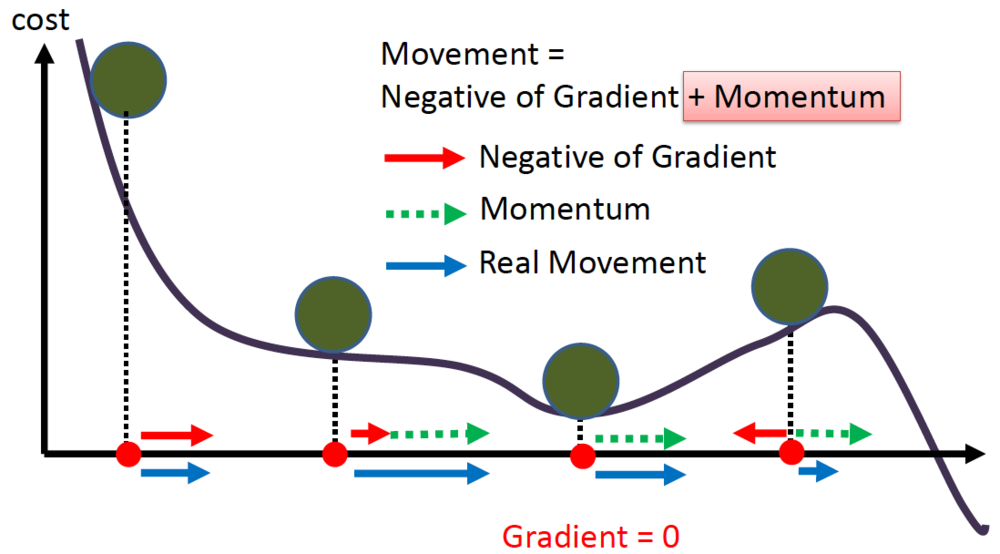
최적화를 위해 손실함수 값이 낮아지는 방향으로 가기 위해 1차 미분계수를 이용하는 알고리즘인 경사하강법의 종류에 대해 알아보겠다.
5.⛰️ 최적화(Optimization)-3.정규화(Regularization) | 내가보려고정리한AI🧐
신경망이 학습데이터에만 너무 특화되어 있지 않고, 일반화(generalization)가 가능하도록 규제(penalty)를 가하는 기법을 알아보겠다
6.⛰️ 최적화(Optimization)-4.앙상블(Ensemble) | 내가보려고정리한AI🧐
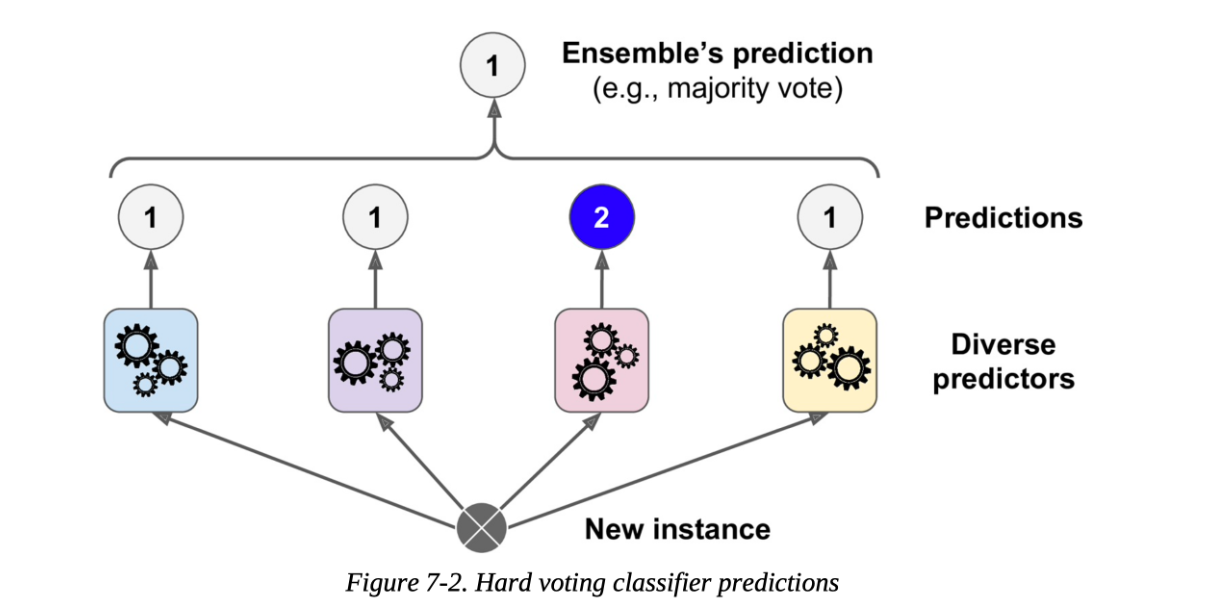
최적화된 모델을 만들기 위해 여러개의 분류기(모델)을 생성하고, 그 예측을 결합함으로서 하나의 강력한 모델 대신 약한 모델 여러개를 조합해 더 정확한 예측에 도움을 주는 방식인 앙상블에 대해 알아보겠다.
7.🤖 CNN(Convolutional Neural Network)을 이해하고 Pytorch로 구현해보자 | 내가보려고정리한AI🧐
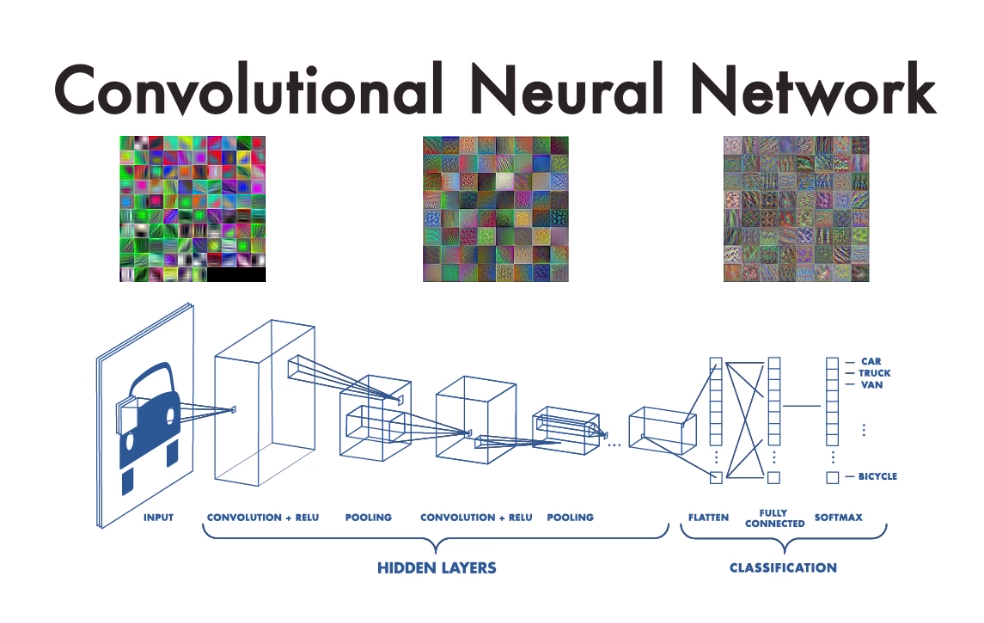
기존 까지 공부한 딥러닝 모델은 선형결합 - 비선형변환을 반복하며 모든 노드가 연결되어 있는 Fully Connected Layer로 구성된 percentron 모델이였다면, 이번 장에서는 CNN의 기본 원리와 pytorch로 구현된 CNN모델을 분석해보겠다.
8.🤖 RNN(Recurrent Neural Network)과 LSTM, GPU를 이해보고 Pytorch로 구현해보자 | 내가보려고정리한AI🧐
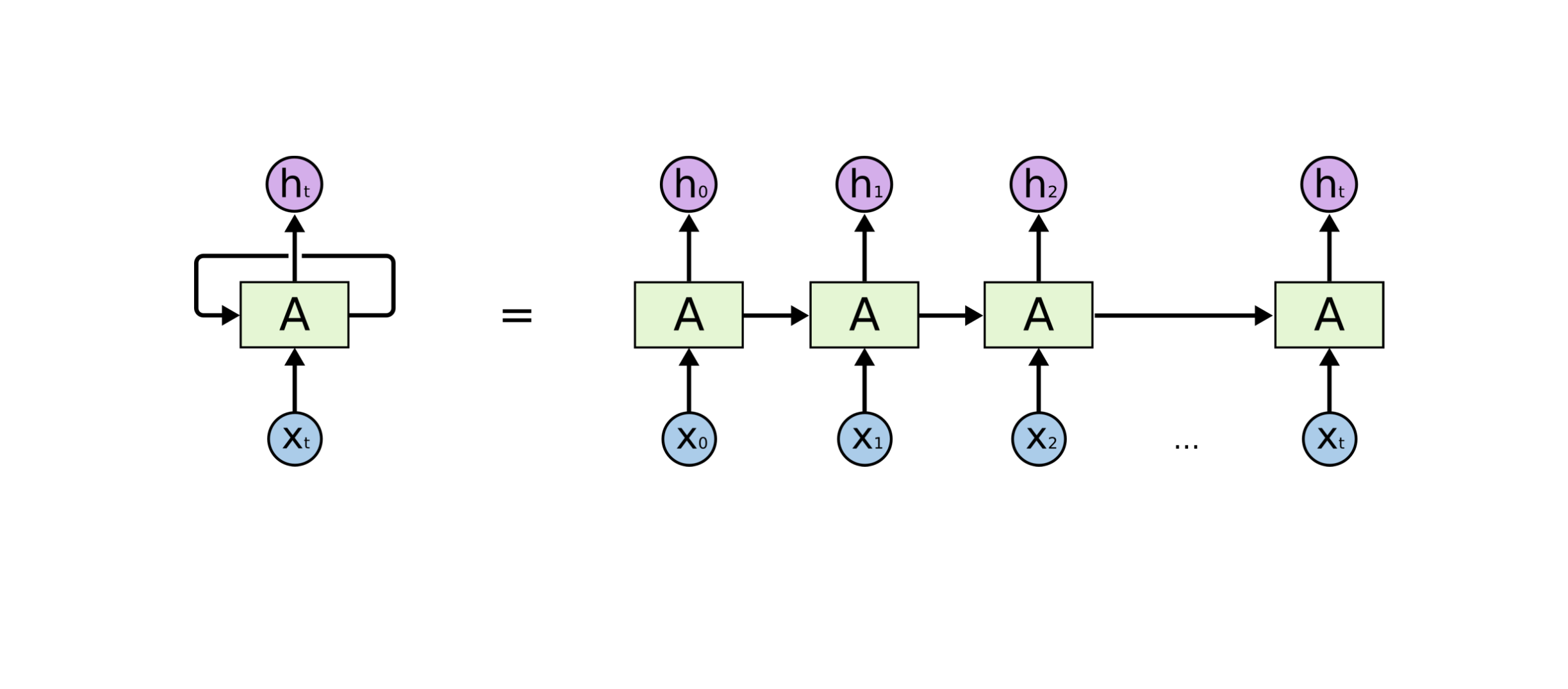
이번 장에서는 시퀀스 데이터를 학습하기 좋은 모델인 RNN계열 모델들을 공부해 볼 것이다. 기본 모델인 vanilla RNN과 vanilla RNN의 단점을 보안하기 위해 변형된 모델인 LSTM, GPU를 소개하겠다. 또한 pytorch로 구현된 LSTM을 분석해보자
9.🤖 Computer Vision이란? | 내가보려고정리한AI🧐

사람은 시각, 청각 등과 같이 오감을 통해 세상과 상호작용을 하면서 성장한다. 사람이 감각을 통해 받아들이는 정보의 75%는 시각을 통해 온다고 한다. 이런 인간의 시각을 모방하는 것이 Computer Vision이라고 할 수 있다.
10.📸 Image Classification(이미지 분류)(1)-LeNet,AlexNet,VGG부터 Degradation까지 | 내가보려고정리한AI🧐
이번 장부터는 Computer Vision의 tasks 중 image classification의 발전 과정을 살펴볼것이다. LeNet-5, AlexNet, VGG까지 모델들을 알아보며 깊은 layer를 가질 때 발생하는 Degradation problem을 살펴보겠다
11.📸 Image Classification(이미지 분류)(2)- GoogLeNet, ResNet,DenseNet,SENet,EfficientNet| 내가보려고정리한AI🧐
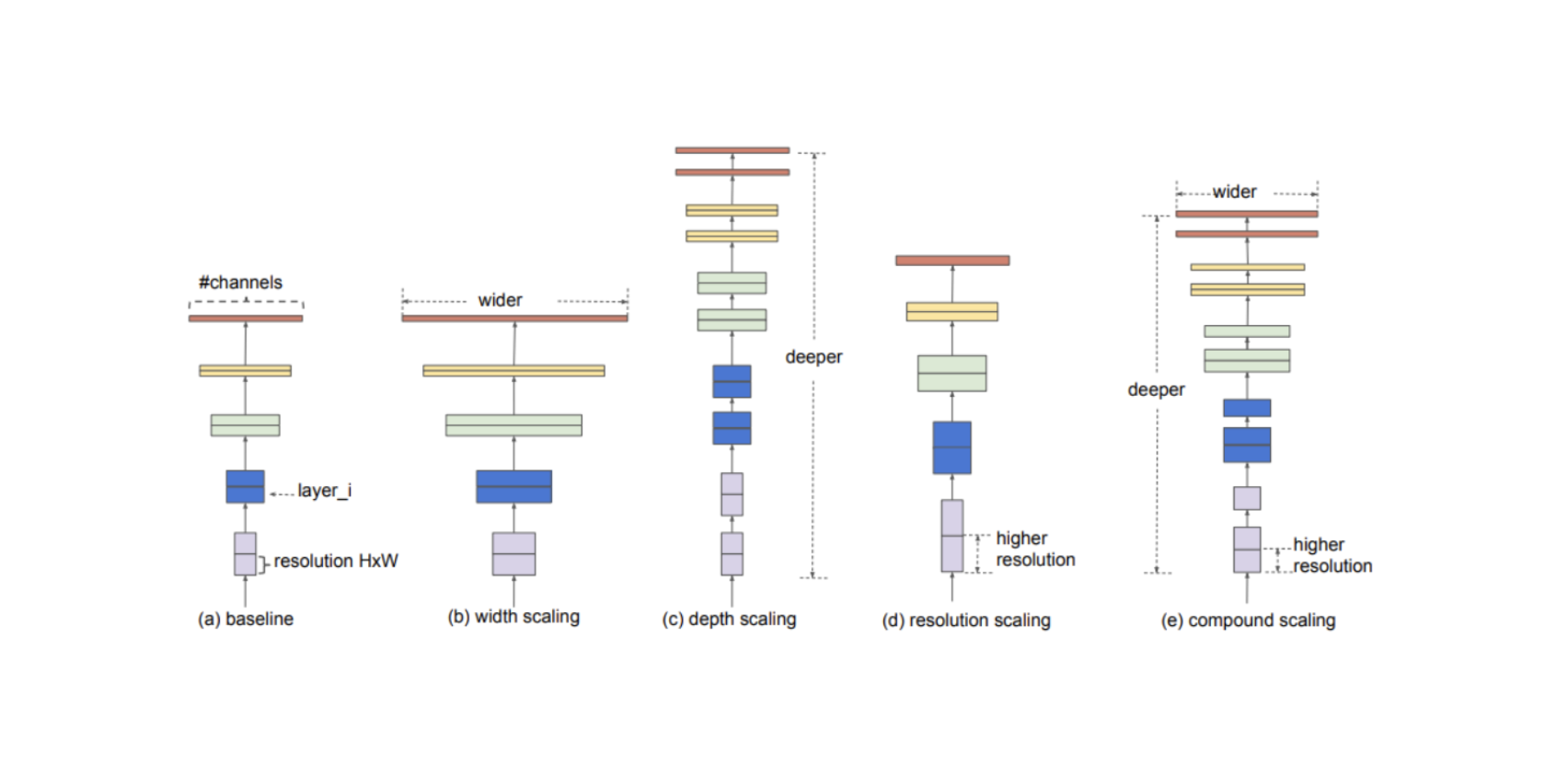
이번 장에서는 GoogLeNet, ResNet가 Degradation problem를 어떻게 해결하였는지 알아보고, DenseNet, SENet, EfficientNet을 통해 Image Classification 성능을 더 높이는 방법을 알아보겠다.
12. 📸 Data augmentation(데이터 증강) - Image편 | 내가보려고정리한AI🧐
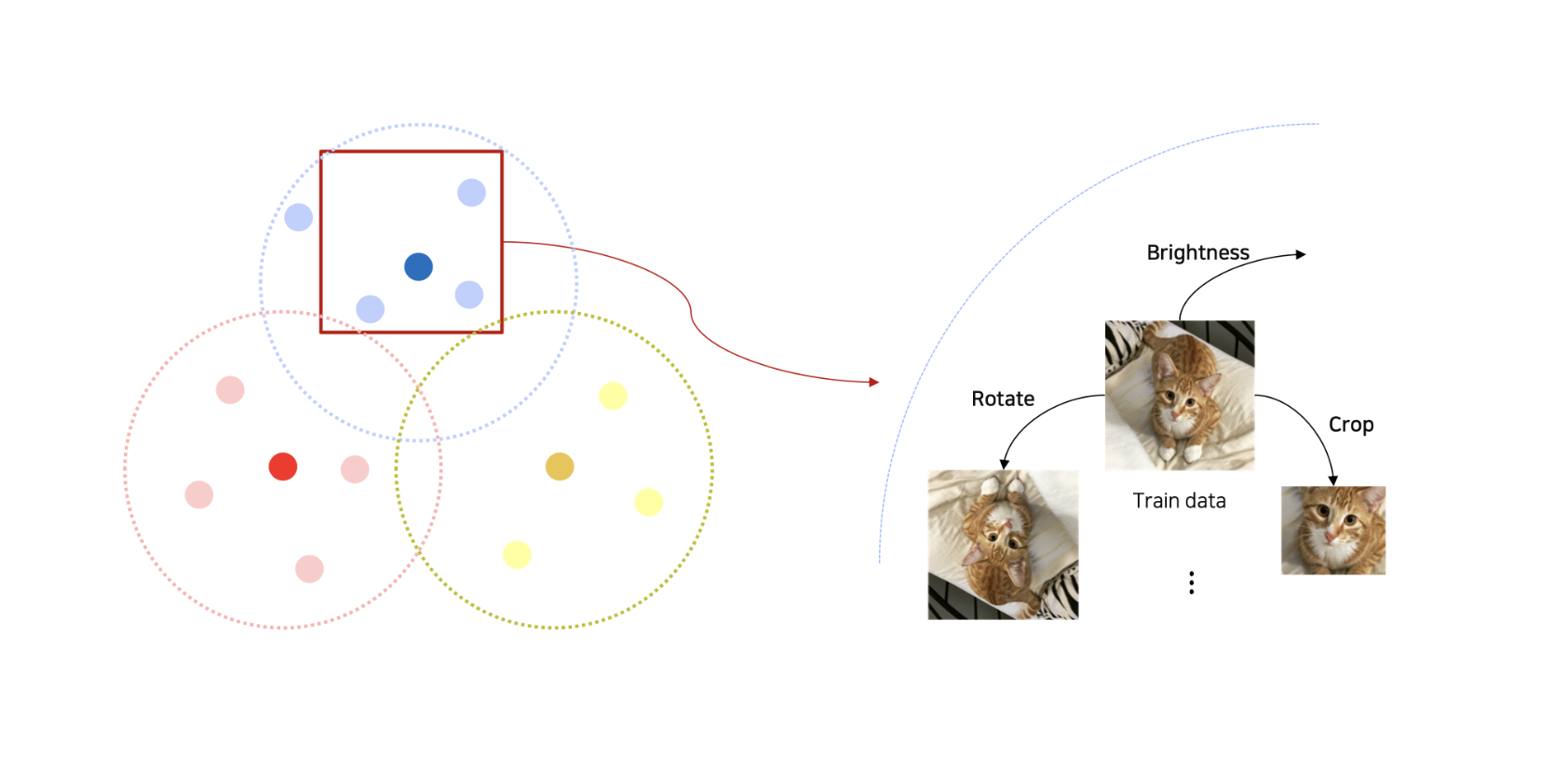
학습 데이터는 세상의 모든 데이터와 항상 같을까? 학습데이터는 항상 현실 데이터와 차이가 있을 수 밖에 없다. 이런 차이를 Data augmentation를 통해서 줄여나갈 수 있다.이번 장에서는 Image Data의 augmentation을 알아보겠다.
13. 📸 Image Classification(이미지 분류)(3)- 👨🏫Transfer learning, Knowledge distillation, Noisy Student까지 | 내가보려고정리한AI🧐

학습된 모델을 Transfer 해서 학습하는 Transfer learning와, Knowledge distillation 방법을 알아보고, Self-training with noisy student인 Recap을 알아보겠다.
14.[Object Detection] 2 stage detectors
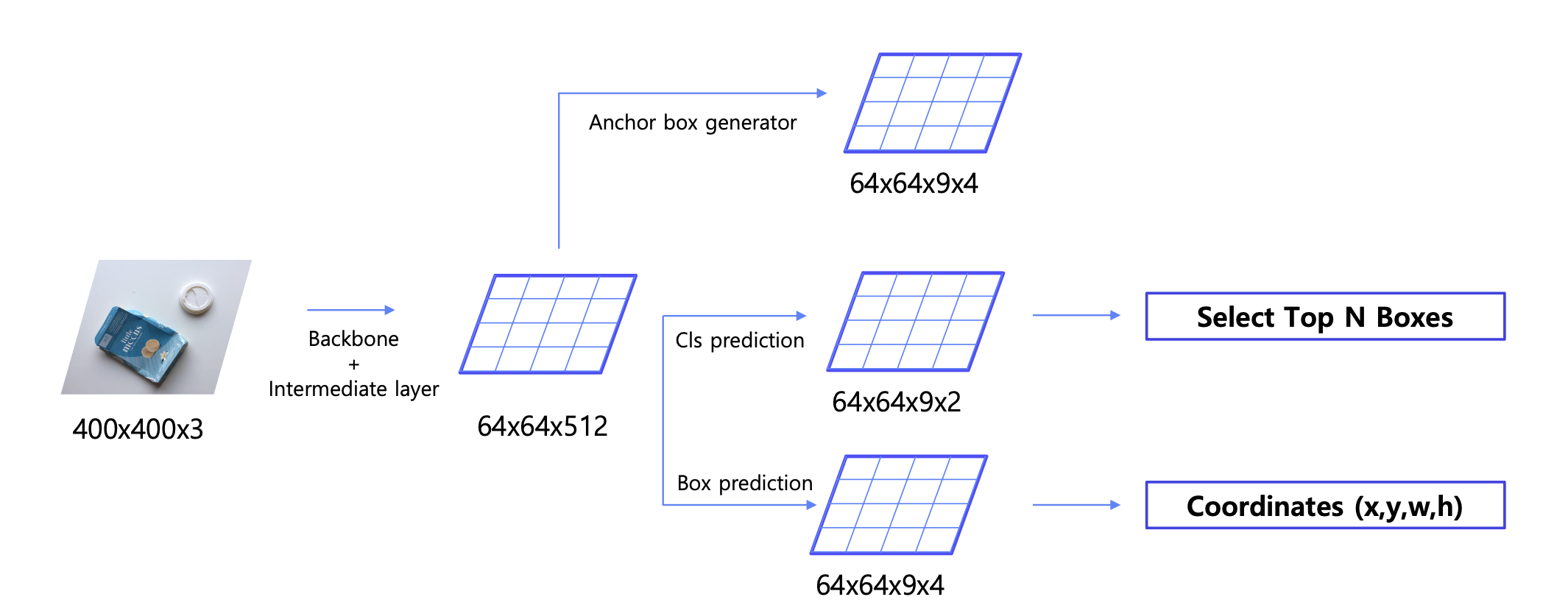
Object Detection 모델들은 크게 2 Stage Detector와 1 Stage Detector로 구분이 가능합니다. 저희는 그 중 먼저 2 Stage Detector에 대해 학습해봅시다. 이번 강의에서는 R-CNN부터 SPPNet, Fast R-CNN, 그
15.[Object Detection] Neck
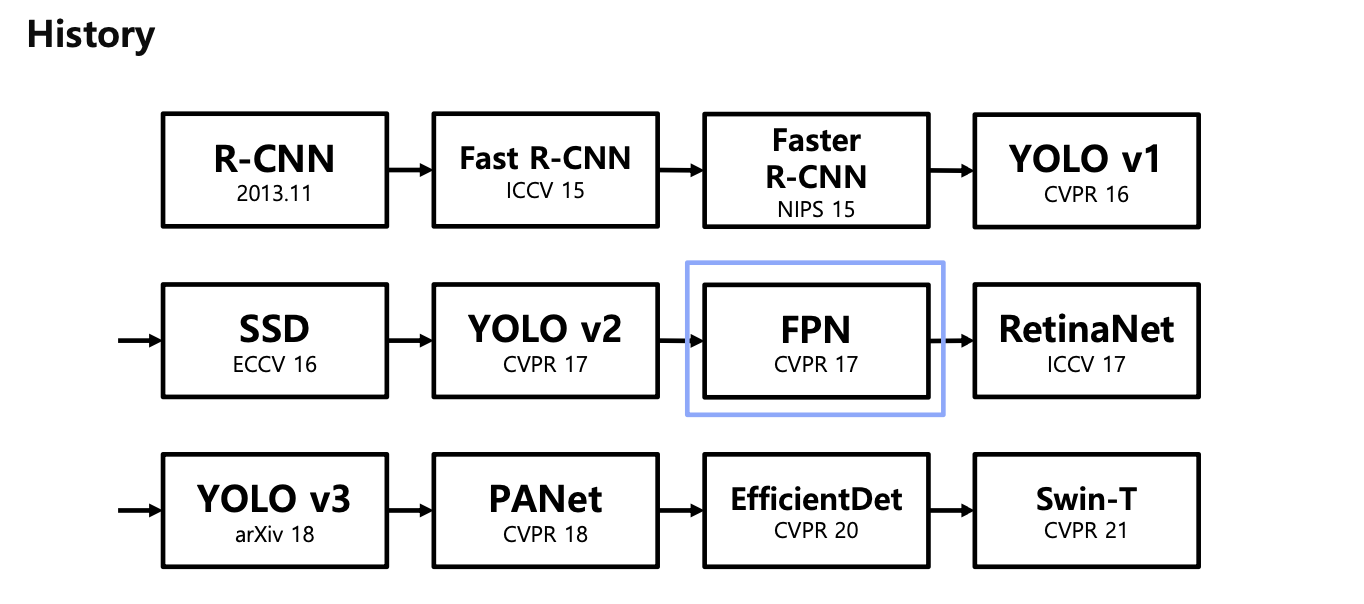
이번 강의에서는 이미지에서 Feature를 추출하는 Backbone과 Region Proposal Network(RPN)을 연결하는 Neck에 대해 알아봅니다. Neck은 왜 필요한지, Neck의 종류에는 어떤 것들이 있는지(FPN, PANet, DetectorRS,
16.[Data Centric] Software 1.0 VS Software 2.0
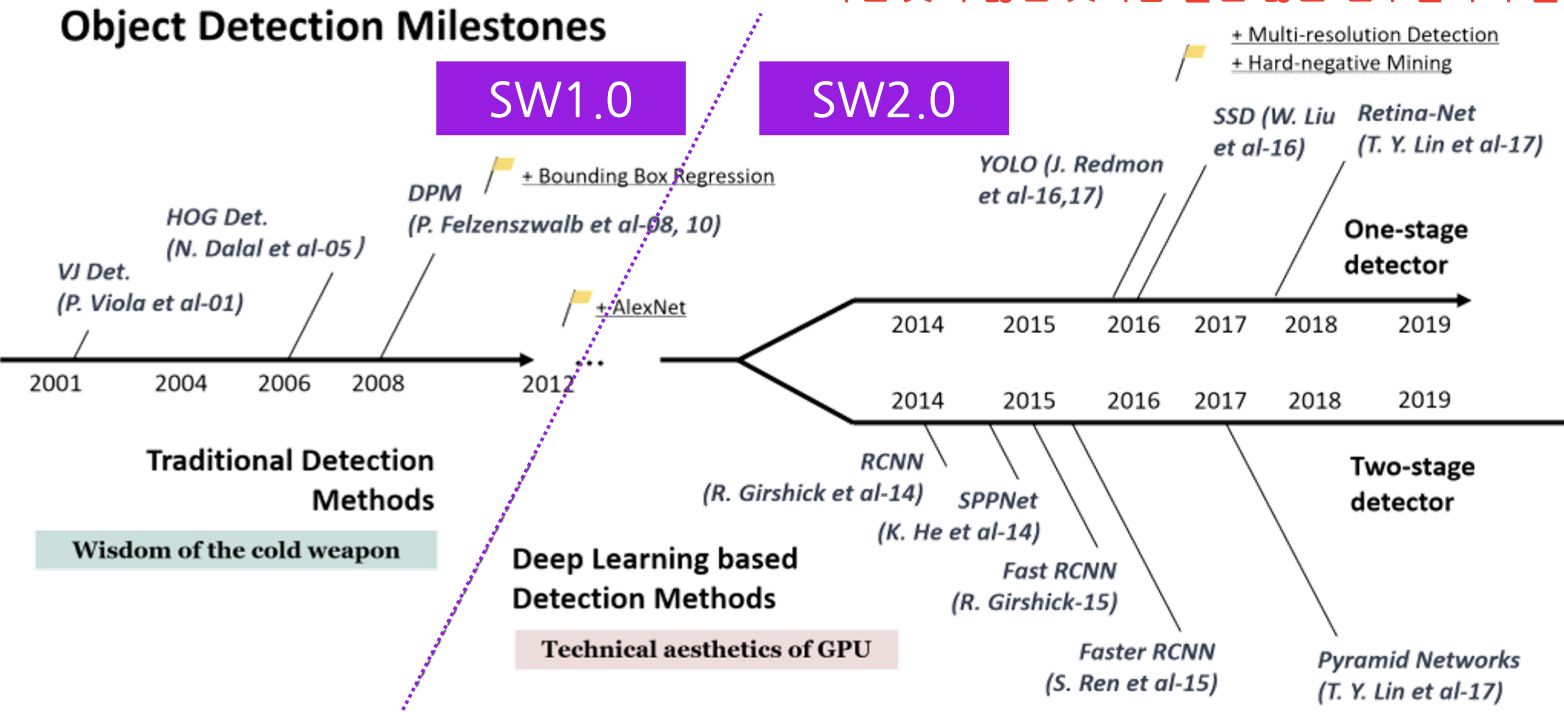
실제 딥러닝 기반 프로덕트를 배포 시 중요시 되는 것 중 하나는 데이터셋 제작이다. 소프트웨어 개발 방식인 Software 1.0, Software 2.0을 알아보고, 데이터셋 제작 측면에서 Software 1.0와 Software 2.0 차이점을 알아보자