K-Nearest Neighbor
-
k: 최근접 이웃 (가장 가까운 k개)학습용 데이터에서 k개의 최근접 이웃의 값을 찾아 그 값들로 새로운 값을 예측하는 알고리즘
-
k-NN for Regression : K개 값의 평균을 계산하여 값을 예측
-
k-NN for Classificaion : 가장 많이 포함된 유형으로 분류
k 값
- k 값에 따라 예측값이 달라지므로 적절한 k 값을 찾는 것이 중요 (기본값 = 5)
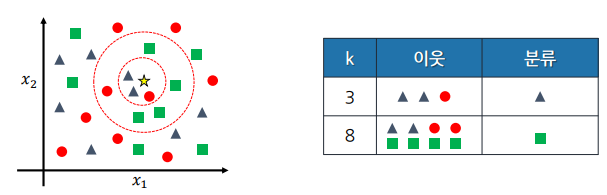
- 검증데이터로 가장 정확도가 높은 k를 찾기 → 튜닝
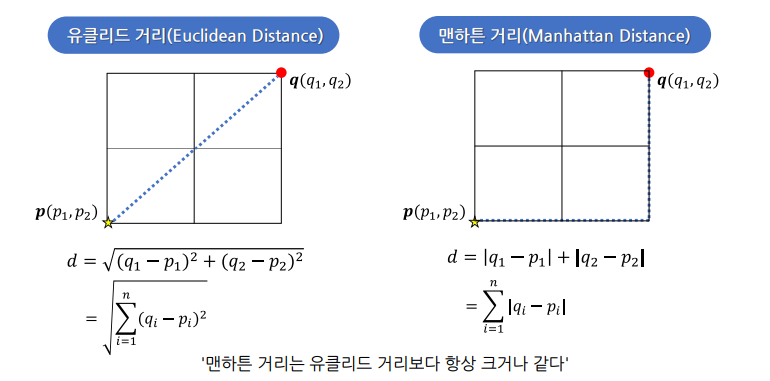
유클리드 거리(Euclidean Distance)
- 거리 기반 분류 분석 모델이며 상대적으로 거리가 더 짧은 이웃이 더 가까운 이웃으로 취급됨
Scaling
💡필요성
- 모델 성능을 높이기 위해
- 같은 범위의 데이터를 가짐
- 독립변수들의 거리의 차이를 같게 만듬
1. 정규화 (Normalization)
- 각 변수의 값이 0과 1사이 값이 됨
2. 표준화 (Standardization)
- 각 변수의 평균이 0, 표준편차가 1이 됨
3. 최소-최대 정규화 공식
# 함수 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)회귀 모델 구현
• 알고리즘 함수: sklearn.neighbors.KNeighborsRegressor
• 성능평가 함수: sklearn.metrics.mean_absolute_error, sklearn.metrics.r2_score 등
# 불러오기
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = KNeighborsRegressor(n_neighbors=5)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))분류 모델 구현
• 알고리즘 함수: sklearn.neighbors.KNeighborsClassifier
• 성능평가 함수: sklearn.metrics.confusion_matrix, sklearn.metrics.classification_report 등
# 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = KNeighborsClassifier(n_neighbors=5)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
난 성미다.