

개요
- Drag-based image editing을 해결하고 싶음.
- 선행연구로 DragGAN이 있음.
- DragGAN의 한계: GAN 의 Capacity에 의해 성능이 제한됨
- LDM 적용은? → GAN 만큼 정밀한 spatial control을 보여준 사례가 없음
- 대부분의 연구가 text-embedding으로 high level의 content, style을 edit 하려 하기때문
- 그러나 GAN과 달리 다양한 도메인에 대한 generation 성능을 입증함
- 기존의 연구들과는 다른 방법으로 img editing을 연구한 DragDiffusion을 제안
Motivation
- Diffusion model 기반 Image editing 시 가정:
- diffusion latent가 생성된 이미지의 spatial layout을 정확하게 결정할 수 있다.
- 기존 Diffusion 기반 editing 연구에서는 위의 가정하에 여러 step의 latent에 대해 Gradient Descent를 사용.
- 본 연구 저자들은 그럴 필요성이 없다고 판단하여 아래와 같은 실험을 진행함.
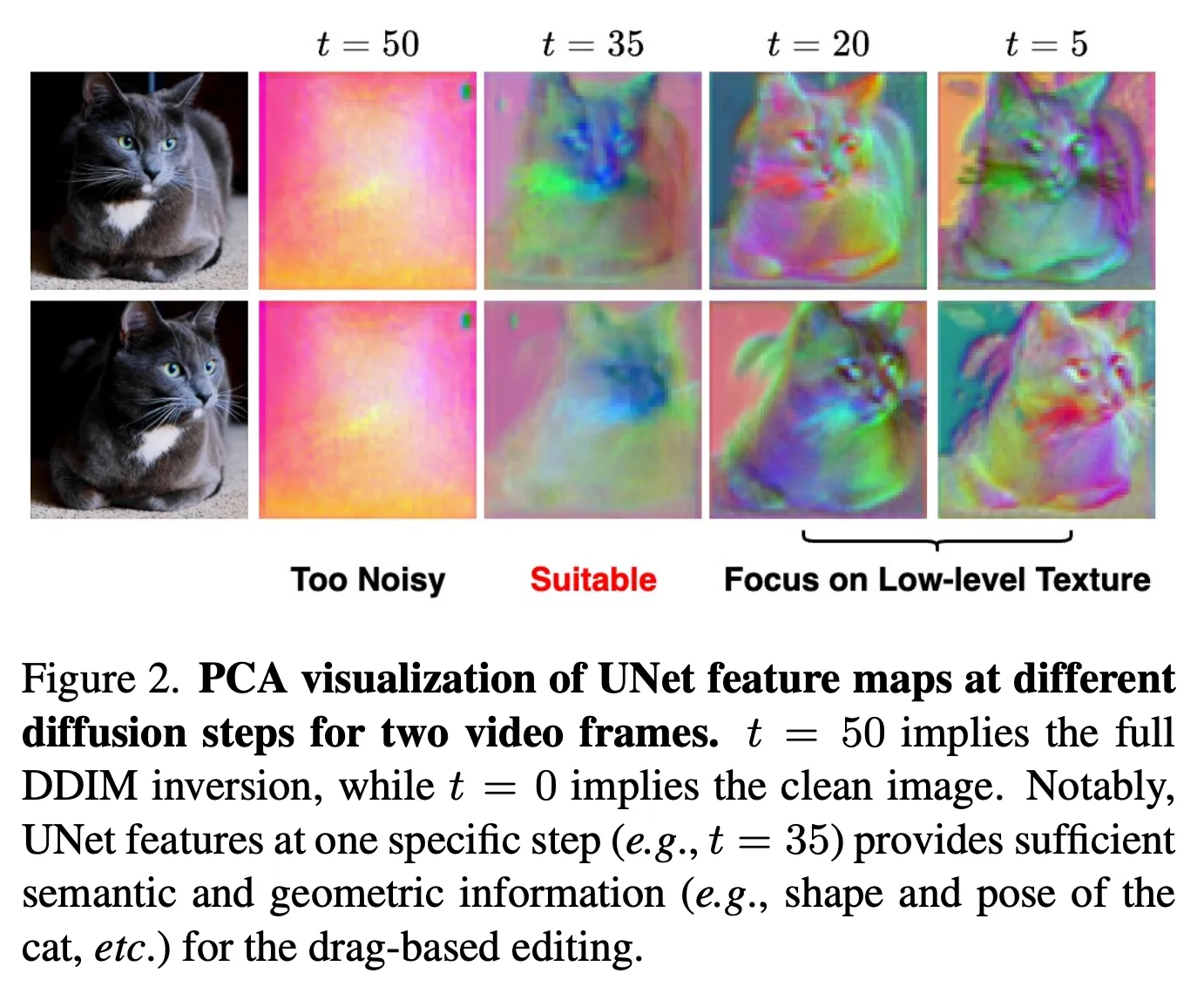
- 실험 방법
- 원본, “dragged” frame을 비디오에서 추출,
- 각 diffusion step 별 UNet feature map을 뽑아 PCA 로 시각화 함
- 단 하나의 step 만으로도
structure-oriented spatial control에 충분할 만큼 semantic, geometric information이 추출됨을 확인
Method
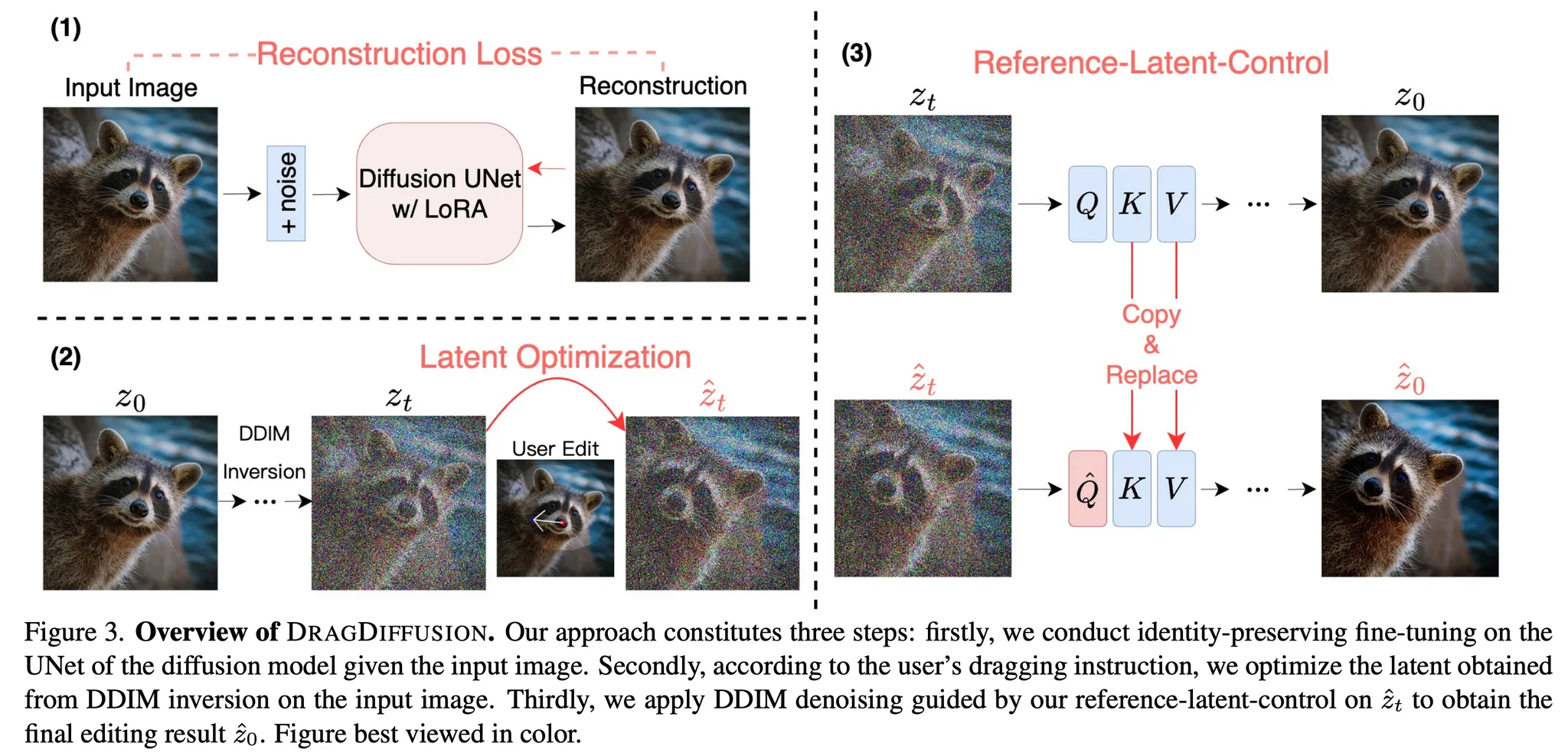
1. Identity-preserving Fine-tuning
- diffusion model의 UNet에 대해 identity-preserving fine-tuning 함.
- Input의 feature를 인코딩을 강화하는 부분.
- 이후의 img edit 과정에서 이미지의 identity가 유지되게 하는 역할.
- fine-tuning은 LoRA 로 진행함.
- notation
- : 각각 UNet과 LoRA 파라미터
- : 실제 이미지
- : 랜덤 노이즈 맵
- : LoRA가 적용된 UNet이 예측한 노이즈 맵
- : diffusion noise schedule의 파라미터 (step t)
- 에 대해 gradient descent로 최적화되면서 fine tune 됨.
- notation
- fine-tune 80 step 만에 충분히 image reconstruction을 잘 학습됨 을 확인함. (A100 기준 25초 컷.)
2. Diffusion Latent Optimization
- user point에 따라 diffusion latent를 최적화하는 파트.
- 필수: handle points와 target points, 최적화를 수행할 diffusion step k.
- 선택: 수정할 영역을 지정하는 mask를 넣어줄 수 있음. (지정된 영역만 edit.)
- Steps
- 우선 주어진 input img x에 대해 k 시점까지 inversion 수행.
- 최적화 (지정한 handle pt가 target pt에 가까워지거나 / 미리 정한 최대 반복 횟수에 도달할 때까지 반복)
- Motion Supervision
- target 근처의 local patch 안에서의 차이를 최소화하도록 latent를 opimize.
- notation:
- points: handle, target pair로 N개 쌍.
handle points:target points:
k-번째 step의 latent:UNet feature maps:- feature vector는 와 같은 식으로 표기. direction vector가 됨
- points: handle, target pair로 N개 쌍.
- Motion supervision loss:
- notations:
- : handle point 근처의 patch
- : handle → target 방향을 나타내는 normalized vector
- : 사용자가 지정한 binary mask
- : regularization을 위해 unmasked region을 유지하는 latent
- gradient descent.
- Point Tracking
-
Motion Supervision에 의해 변한 handle points의 위치를 tracking 하는 부분.
-
각 handle point 가 주변 patch 내에서 가장 가까운 feature vector를 찾도록 업데이트.
-
이때 nearest-neighbor search를 수행한다:
-
- Motion Supervision
3. Reference-latent-control
- 앞선 Latent optimize 후 바로 ddim denoise 해버리면, identity shift 발생
- 원본 이미지와 달라지거나 품질저하 발생하는 것.
- 저자들은 denoising 과정에서 원본 이미지를 활용한 충분한 guidance가 없어 발생한 것으로 원인 지목.
- 이를 해결하기 위해 UNet self-attention block을 활용하여 denoising 과정을 조정.
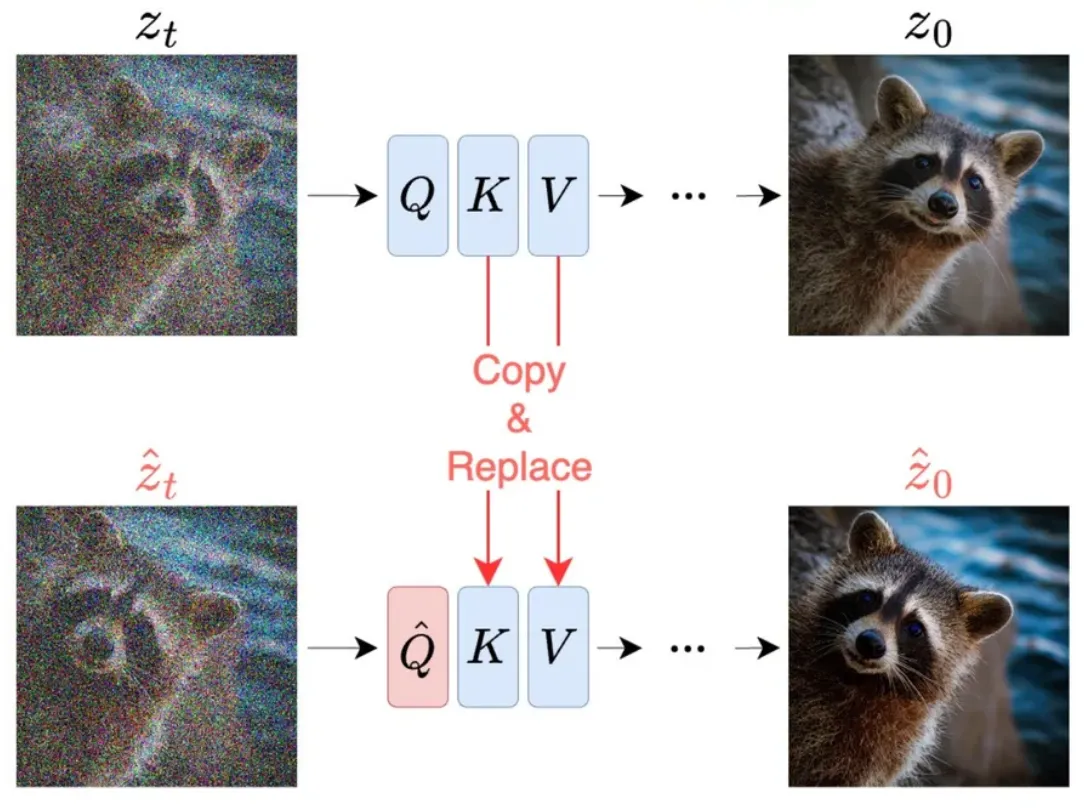
원본 latent:최적화된 latent:- 두 latent에 대해 denoising을 동시에 진행함.
- 이때 의 self-attention key/value를 의 key/value로 교체.
- edit latent의 query가 원본 latent의 content와 texture를 참조하도록 만든 것.
etc. Implementation Detail
- Stable Diffusion v1.5 사용
- LoRA 세팅
- UNet의 attention module의 projection matrix에 LoRA 주입하여 사용.
- rank = 16.
- Optimizer: AdamW
- Learning rate = 5e-4
- Batch size = 4.
- Training steps = 80.
- UNet의 attention module의 projection matrix에 LoRA 주입하여 사용.
- Latent optimization:
- DDIM sampling steps = 50.
- Edit latent 최적화는 step 35에서 시작.
- Classifier-free guidance (CFG) 는 사용 X → numerical error 방지 목적.
- Adam, learning rate = 1e-2
