[논문리뷰] One-Minute Video Generation with Test-Time Training (TTT)

저자들의 문제제기
- text-2-video(T2V) 도 Diffusion으로 많이 풀림
- 하지만 짧은 동영상만 가능. (그것도 single scene story의 simple context의 동영상만 생성가능함.)
Sora (OpenAI): 20초, MovieGen (Meta): 16초,Ray2 (Luma): 10초, Veo2 (Google): 8초
- 긴 동영상에서 안되는 이유?
- 시간적 일관성(temporal consistency) 유지 어려움 (외모, 배경, 카메라 시점이 갑자기 변하는 현상)
- 생성 중 오차가 누적되어 뒤 프레임으로 갈수록 품질이 더 저하됨.
- Auto-regressive 방식이라 더 그럼 (이전 output → 현재 Input)
- 학습 셋이 대부분 5-10초 이하 비디오 임.
- Transformer 계산 복잡도.
- self-attention 비용이 컨텍스트 길이에 따라 제곱 증가 (동적 모션 영상 비디오에서 더 심함.)
- ex. 1분 길이비디오는 표준 토크나이저만 써도 300k개 이상의 토큰 필요
- self attention 쓰면 3초 비디오 20개 생성보다 11배 더 오래 걸리고, 훈련은 12배 더 긴 시간 소요
- 이에 본 연구에서는 1분 이상 길이의 동영상도 하이 퀄리티로 잘 생성하도록 만들고자 함.
Auto Regressive 모델의 근본적 문제를 어떻게 해결하나?
- 선행연구인 [43] Learning to (Learn at Test Time): RNNs with Expressive Hidden States 에서 힌트를 얻음
- RNN이 long context를 잘 수용하지 못하는 문제를 해결한 연구
- 기존의 RNN은 hiddenstate를 그냥 쌓아둠
- [43]에선 이걸 웨이트로 취급하여 매 순간의 입력과 이전의 입력들을 이용해 학습시킴.
- How: 모델을 인풋에 따라 2가지로 사용함
- Pure Input 넣는 경우: Output Token 예측
- Noise 씌운 Input 넣는 경우: Reconstruction 예측
- Hidden State를 (W) 학습?
- W를 Optimize 해야 함 → 즉 ∇ℓ을 한 번 더 미분함. (메타러닝에서 많이 사용되는 방법)
- 전체 RNN 구조를 Optimize 하는 것을 outer loop, W를 Optimize 하는 것을 inner loop라 부름.
- 테스트할때도 W는 Optimize 되어야 한다. (Concept 상. 그래서 Test-Time Train)
- 여기 다시 읽어야 함.
Model Architecture
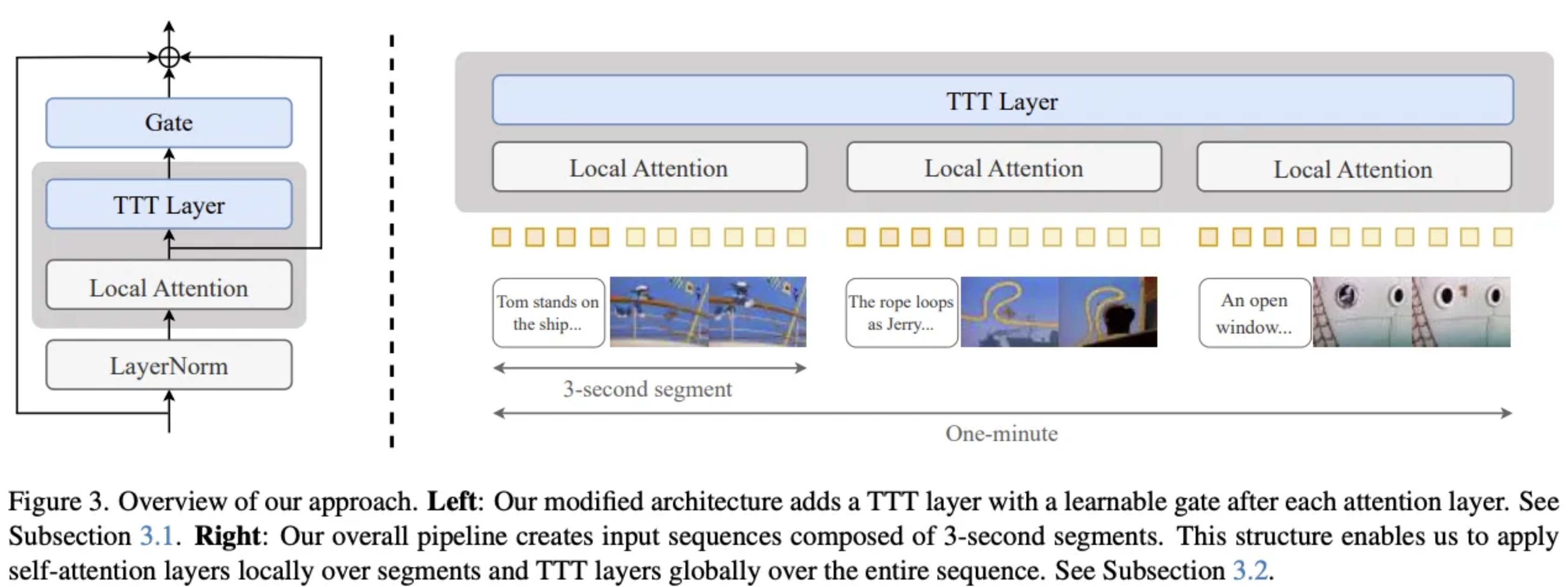
- Motivation 에서 설명된 TTT 레이어를 DiT 모델에 첨가해서 사용. (DiT 참고)
- inner loop 모델 구조: 2개 MLP
- hidden dimension은 입력 차원의 4배, Activation은 GELU
- LayerNorm, residual connection 사용 f(x)=x+LN(fMLP(x))
Gating
- input sequence token: X=(x1,...,xT)
- output sequence token: Z=(z1,...,zT)=TTT(X)
- 다만 걍 TTT 박아버리는 걸로는 오히려 나빠지므로 아래와 같은 폼으로 TTT 사용. gate(TTT,X;α)=tanh(α)⊗TTT(X)+X
- α는 learnable로, 0.1로 초기화하여 초기 학습에 TTT가 거의 영향을 주지 않도록 함.
Bi-direction
- Diffusion 모델은 non-causal 함
- → zt를 만들 때 전체 input sequence token을 condition으로 사용할 수 있음.
- TTT는 causal이지만 non-causal로 만들기 위해 bi-direction trick을 사용함.
- rev(X)=(xT,...,x1) 라 할 때 TTT’을 아래와 같이 정의함
- TTT′(X)=rev(TTT(rev(X)))
Modified architecture
- 기존 Transformer Diffusion 모델 구조
- X′=selfattn(LN(X))
- Y=X′+X
- TTT 결합된 모습
- Z=gate(TTT,X′;α)
- Z′=gate(TTT′,Z;β)
- Y=Z′+X
모델 Inference Pipeline
- fine-tuning, inference에 모두 적용되는 pipeline임
Scenes and Segments
- 원본 비디오를 “Scene” 단위로 쪼갬.
- Scene: 하나의 어떤 의미있는 동작의 시작과 끝을 의미함
- segment → 모델이 학습 혹은 추론 시 한번에 다룰 수 있는 단위로 3초로 잡음.
- pretrained인 CogVideo-X가 한번에 3초까지 밖에 생성 못해서 그럼.
- 그러므로 1개 scene은 1개 이상의 segment를 가지게 됨
Formats of text prompts
- 최종 format: segment 마다 3~5줄 길이의 문단을 prompt로 사용
- prompt엔 background colors and camera movements가 주로 묘사됨
- 처음엔 Format 1로 만들어진 것을 Format2 → 최종 format으로 변환함
- Format 1: 5~8문장으로 요약된 짧은 줄거리
- Format 2: 20문장 내외로, 각 문장이 3초 세그먼트에 대응
- 변환에는 claude3.7을 사용하여 변환함.
- Format1 → 최종으로 바로 가버리면 성능 떨어진다함.
- N초 길이 동영상 → 3*N개 {text prompt, video segment} 를 토크나이징
- 그후 각각 대응되는 애들이 반복되게끔 입력 시퀀스 생성
Local attention, global TTT
- Diffusion의 self-attention은 1개 segment에만 적용 (전체 입력 시퀀스에 대해서는 적용 x)
- TTT 레이어는 전체 입력시퀀스에 대해 적용됨
Finetuning Recipe
Multi-stage context extension
- 처음엔 segment 1개 단위로만 fine-tuning
- 이때에 TTT와 gate 같이 기존 CogVideoX에 없던 레이어에만 큰 LR이 적용됨
- 그 후 4단계에 걸쳐 fine-tuning
- 각 단계마다 9초,18초, 30초, 63초까지 늘리며 연결된 Segment를 사용하도록 데이터를 구성함.
- 이 4단계에선 TTT, gate, self-attention 만 작은 lr로만 학습.
- 톰과 제리 데이터가 너무 화질 구지여서 Real-esrgan으로 super-resolution함.
Parallelization for Non-Causal Sequences
- 위에서 제안한 loss 구조는 단순하게 병렬처리 할 수 없음
- 이는 Auto-Regressive 구조의 필연적 문제.
- inner-loop mini batch 로 병렬처리가 가능하도록 함.
- b 크기의 미니 배치를 만들어 그 구간의 W들 그래디언트를 평균내버림.
- W가 non-causal이므로, 미니배치끼리 평균을 내어 업데이트 해도 정보손실이 크지 않음. Wib=W(i−1)b−b/η∑t=(i−1)b+1ib∇ℓ(W(i−1)b;xt)
- 이 미니배치의 output token들은 이제 Wib 만으로 계산가능함.
- zt=f(Wib;xt)
On-Chip Tensor Parallel
- TTT-MLP가 SMEM에 올리기 너무 큼
- Streaming Multiprocessor에 분산 시킴 (gpu 여러 개면 또 거기다 분산)
- HBM은 최종 결과만 SM은 중간 연산만 담게 함.
