Improving Diffusion Models for Authentic Virtual Try-on in the Wild
개요
- Image-based virtual try on 문제를 diffusion 모델로 해결하고자 함.
- 사람과 의류 영상이 주어지면 사람에게 의류를 입히는 문제.
- 기존 method [4, 9, 23, 28, 31, 35] 들의 한계점
- 두 가지로 분류되며 공통적인 문제점은 의류의 identity 등 원본의 identity가 distortion 되는 부분.
- GAN-base methods:
- garment를 human body에 맞게 변형하기 위한 별도의 warping module을 사용
- generator를 통해 target person과 합성
- exemplar-based inpainting diffusion models:
- pretrained T2I diffusion models [34, 40, 43]:
- rich generative prior를 활용, 자연스러움을 향상
- pseudo-words [31]로 garment semantics를 인코딩
- explicit warping network [9]를 사용
- 본 연구는 Garment fidelity를 더 올리기위한 method IDM-VTON을 제안
- Garment image semantics 유지를 하기 위한 모듈을 LDM에 적용
- Image Prompt Adapter, GarmentNet
- T2I Diffusion을 사용함.
- 이때 detail한 garment caption이 LDM의 prior knowledge 보존에 중요함을 밝힘.
Customizing diffusion models.
- 적은 수의 image로도 diffusion models 을 customization 할 수 있음이 증명됨 [5, 11, 25, 42, 45].
- unseen example에 적응시키기 (catastrophic forgetting 없이 adaptation 시키기)
- parameter efficient fine-tuning methods [16, 17]
- regularized fine-tuning objective [26]
- inpainting, image restoration task에 diffusion model 적용된 사례
- masked image completion [48], image restoration [2]
Classifier-free guidance (CFG)
- CFG DM의 개념을 차용하여, Text conditioning 을 수행한다.
- text prompt의 controllability 를 강화효과가 있음.
- Training: text condition c 를 확률적으로 drop, null text 가 사용되거나 실제 text가 사용됨
- Inference: text condition O/X prediction의 사이를 interpolation하여 text 조건의 강도를 조절. ϵ^θ(xt;c,t)=s⋅(ϵθ(xt;c,t)−ϵθ(xt;∅,t))+ϵθ(xt;∅,t)
Image prompt adapter [57]
- T2I diffusion model 을 reference image 로 condition 하기 위한 모듈 [57]
- image encoder (예: CLIP image encoder) 로부터 추출한 feature 를 활용,
- Q∈RN×d: UNet 의 intermediate representation 에서 나온 query matrix
- text conditioning 에 추가적인 cross-attention layer 를 붙인다.
- Kc∈RN×d,Vc∈RN×d: text embedding c 로부터 얻은 key, value matrix
- N: sample 의 개수
Method
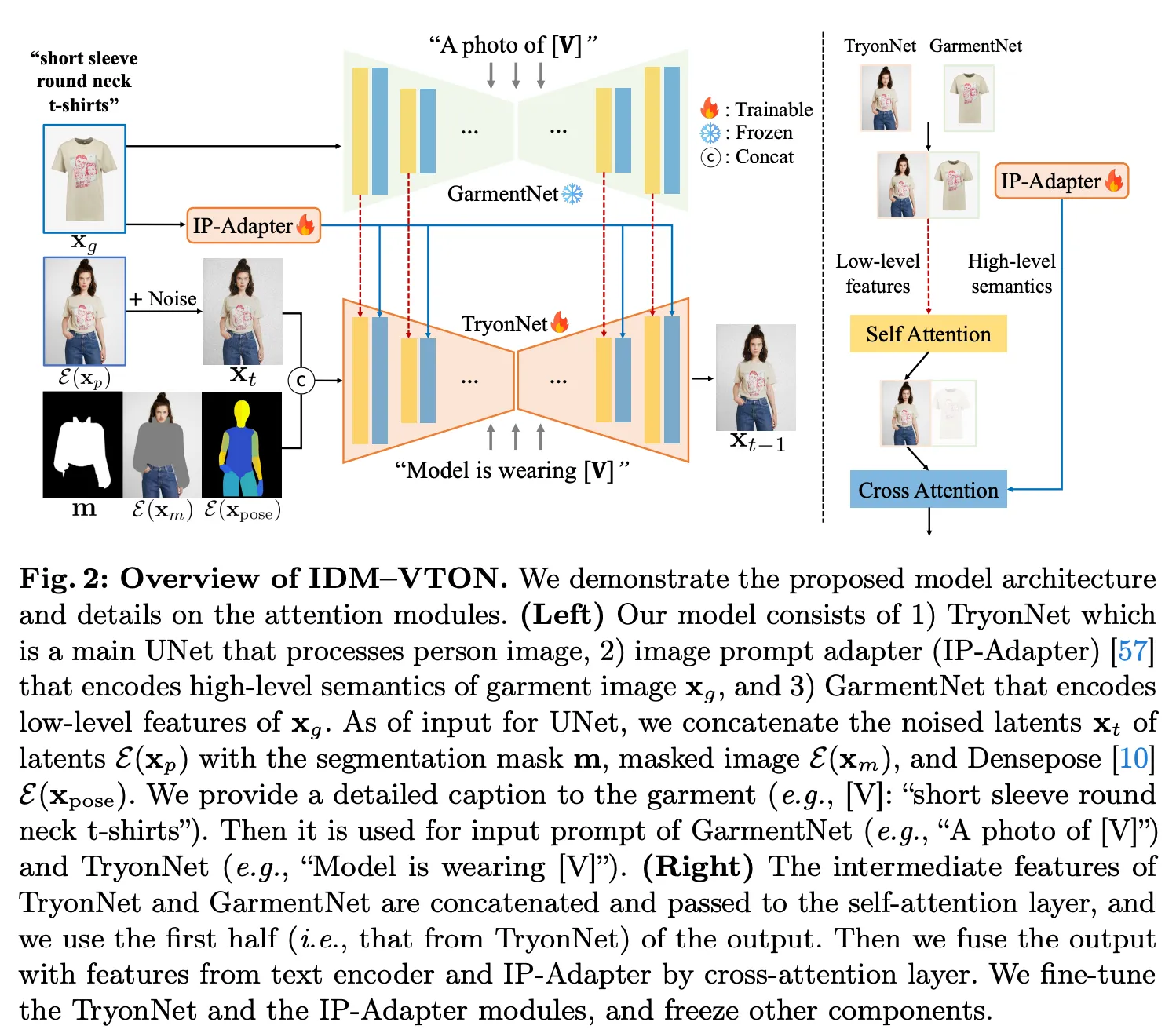
- 입력: xp,xpmask,pose,xg
- 목표: x_p에 의류 이미지 x_g 안의 garment를 inpainting (exemplar-based image inpainting [56])
- 즉, reference image를 활용하여 masked image를 채우는 것 (의류에 대해서만)
- 구조
- Base UNet (TryonNet): pose 정보와 함께 masked person image를 처리
- Image Prompt Adapter (IP-Adapter): 의류의 high-level semantics를 추출
- Garment UNet feature encoder (GarmentNet): 의류의 low-level feature 추출
- GarmentNet feature → TryonNet의 self-attention layer
- IP-Adapter feature → TryonNet의 cross-attention layer에 추가된다.
TryonNet
- Architecture: LDM
- Input: latent들은 channel axis를 따라 align하여 concat.
- U-Net이 총 13channel을 처리하도록 바뀜
- 사람 이미지의 latent E(xp),
- resize된 mask m, 즉 사람 이미지에서 의류 영역을 제거한 mask,
- masked-out person image xm=(1−m)⊙xp의 latent E(xm) [3],
- DensePose [10]로부터 얻은 사람의 pose image latent E(xpose).
- Weight init: zero weight로 초기화,
- Stable Diffusion XL (SDXL) [36] inpainting model [49]을 base로 사용
Image Prompt Adapter
- Garment의 high-level semantics를 condition 추출용.
- Ye et al. [57], Image Prompt Adapter (IP-Adapter) 사용.
- projection layer와 cross-attention layer만 fine-tuning 됨.
- cross-attention fine-tune 시에는 text prompt가 사용된:
- Attention(Q,Kc,Vc)+Attention(Q,Ki,Vi)
Garment Net
- IP-Adapter만으론 garment의 모든 detail 보존이 불가.
- 이를 위해 추가 UNet 으로 garment를 인코딩함.
- input: Garment image E(xg)의 latent.
- model: (frozen) pretrained UNet encoder (Stable Diffusion U-Net 복사 후 freeze.)
- 이를 통해 intermediate representation 획득.
- 이후 TryonNet의 intermediate representation과 concatenate.
Detailed captioning of garments.
- 대부분의 diffusion vton 모델들은 text prompts 를 단순한 수준으로만 사용하거나 사용하지 않음
- 본 연구에선 comprehensive caption을 사용하여 성능을 더 높임.
- 구체적으로, garment image에 대해 comprehensive caption을 사용
- 이를 GarmentNet, TryonNet 모두에 전달.
Customization of IDM–VTON.
- 본 연구에선 In-the-wild Dataset adaptation을 위해 finetune 방법론도 제공함
- garment - human pair 영상을 통해, Try-on net 을 fine-tuning 하는 방식.
- pair가 없다면, garment seg 모델을 제공하여 pair 세팅을 강제로 만듬.
- 구체적으론, attention layers of the up-block들만 fine-tune 됨.
