[논문리뷰] You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
논문리뷰
목록 보기
7/11
개요
- Transformer가 순수한 sequence-to-sequence만으로 2D Detection을 수행할 수 있을까?
- 이에 YOLOS를 고안하여 실험.
- vanilla Vision Transformer 기반으로 구성한 object detection 모델.
- target task에 대한 region prior / inductive biases가 최소화되어 있음.
- YOLOS-Base 의 경우 COCO val에서 42.0 box AP를 달성.
- ViT의 pre-train scheme과 model scaling 전략에 대해서도 다룸.
Background
- Transformer는 본디 NLP에서 knowledge-transfer를 위해 태어난 아키텍쳐임.
- general한 feature를 뽑을 수 있는 Pretrain을 만드는 모델.
- big general corpus로 pre-train → 특정 target task에 adapt하는 방식으로 사용
- 또한 task 간의 transfer 하는 방식으로도 사용됨.
- ex. sentence-level [7, 19]와 token-level [48, 52] task 간의 transfer
- Vision Transformer (ViT): 위와 같은 일반적Transformer encoder 아키텍처를 거의 그대로 사용함.
- 그러면서도, Image recognition에서 좋은 성능을 보인 성공 사례 중 하나임.
- 그럼 ViT도 cls에서 det 같은 object-/region-level task로 transfer 가능한가?
Proposal
-
ViT classificaton → Detection으로 Transfer 가능하려면 무엇을 해결해야 하는가?
- ViT 장점: long-range dependency와 global context를 잘 모델링함
- 단점: CNN처럼 hierarchical 구조가 없음 → scale variation 처리 한계.
-
YOLOS: 일반 ViT 에 최소한의 수정만 적용한 object detection 모델
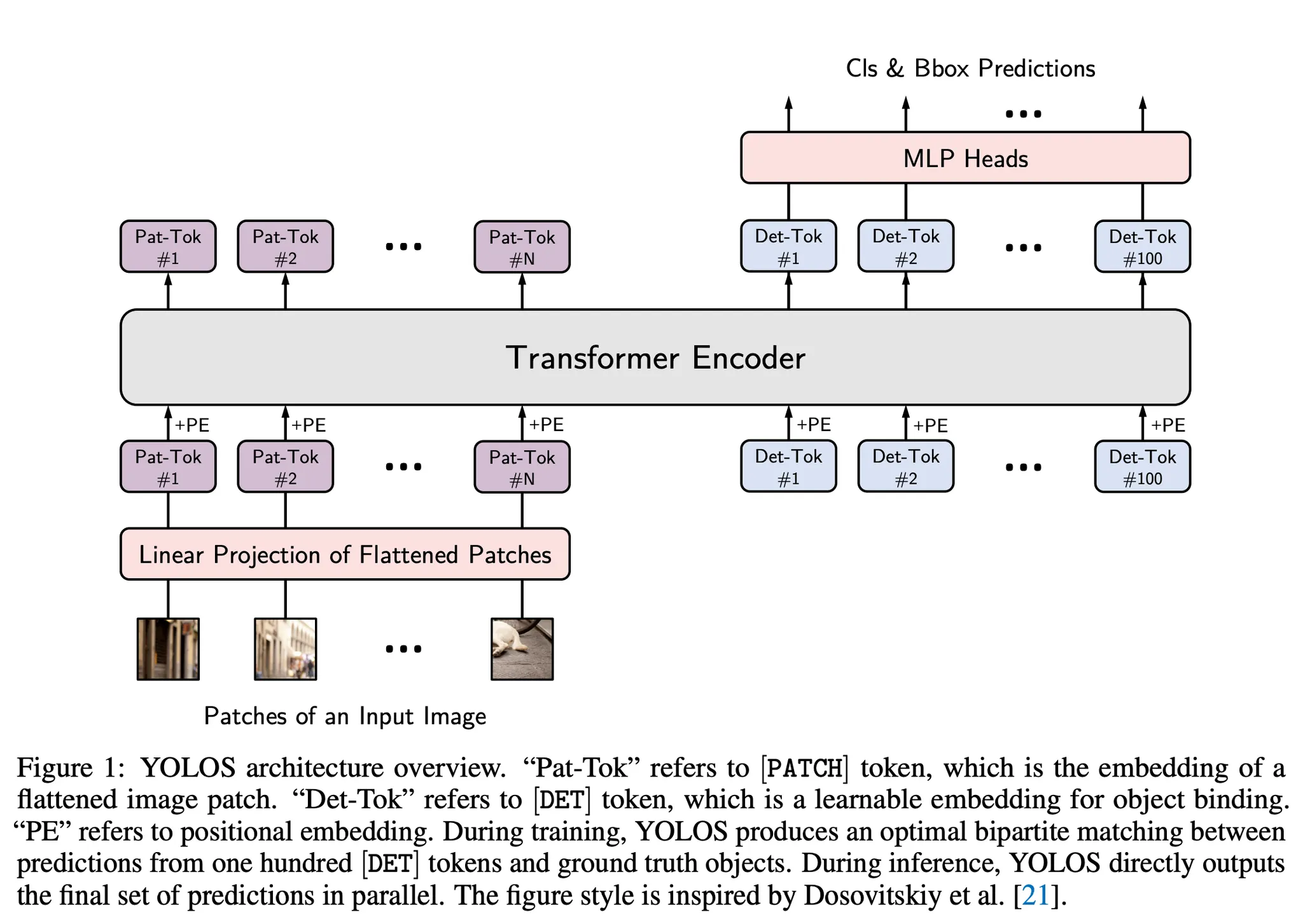
- ViT의 [CLS] token을 100개의 [DET] token으로 교체.
- classification loss 대신 bipartite matching loss (Carion et al. [10]) 사용.
- 2D feature map 재해석 불필요.
- 2D spatial prior/heuristic 제거.
- Prediction head는 MLP 레이어로 구성.
- scale variation은 Positional Encoding에 interpolation 추가하여 해결.
Architecture Detail
1. Stem (입력 구조)
- 이미지를 패치 단위로 분리 → linear projection하여 [PATCH] 토큰으로 변환
- 여기에 100개의 learnable param인 [DET] 토큰을 추가하여 입력으로 사용.
- [PATCH] + [DET] + Pos-Encoding을 Transformer 인코더의 input으로 사용
- input:
2. Body (Transformer 인코더)
- ViT와 동일한 구조의 Transformer stack 구조.
- [PATCH]와 [DET] 토큰을 구분하지 않고 동일하게 global attention.
- 각 인코더 레이어는 다음과 같이 구성됨:
-
LayerNorm → Multi-Head Self-Attention → Residual → MLP → Residual (ViT와 완전히 동일.)
-
3. Detector Heads
- ViT의 classification head와 같이 MLP로 구성
- Classification과 Bounding box regression을 각각 하나의 MLP로 처리.
- 각 MLP는 Linear Layer / ReLU / Linear Layer 로 구성.
4. Detection Token
- [DET] 토큰은 객체 표현을 위한 proxy 역할을 함.
- DETR과 동일
- 토큰 당 “이미지 안에 자동차가 있을 확률 x%, (x, y) 위치에 width 0.2, height 0.1”로 예측
- 랜덤 초기화되며, 2D 구조나 prior 없이 학습됨.
- DETR은 ResNet으로 추출한 feature를 통해 [DET] 토큰을 만듦.
- 본 연구는 생짜 Learnable param 사용. (No inductive bias)
- COCO fine-tuning 시 각 [DET] 토큰과 GT 객체 간 bipartite matching을 수행 (DETR과 동일).
- 모델이 예측한 100개의 박스 중 어떤 게 실제 객체(GT)랑 매칭되는지 찾기 위한 알고리즘.
- GT 객체들이 m개 있을 때, 모델은 100개 예측을 냈다 가정하면,
- 모든 “예측–GT” 조합에 대해 matching cost (예측 box와 GT box의 차이 + class 차이)를 계산함.
- 그후 총 cost가 최소가 되는 1:1 매칭을 찾음 (by hungarian algorithm).
- min-cost perfect matching 문제를 polynomial time (O(N³))에 푸는 최적화 알고리즘.**
- 모든 매칭 조합을 시도하지 않고, 수학적으로 행렬의 최적 matching을 찾음
- 매칭 후엔 loss (L1 + GIoU + class cross-entropy)를 계산
- 매칭되지 않은 예측들은 “no object” 클래스로 학습.
- 이 방식은 YOLOS가 2D spatial structure를 명시적으로 알지 못해도 detection을 수행할 수 있게 함.
- 모델이 예측한 100개의 박스 중 어떤 게 실제 객체(GT)랑 매칭되는지 찾기 위한 알고리즘.
- 즉, YOLOS는 순수한 sequence-to-sequence 관점에서 객체 탐지를 수행.
5. Fine-tuning at Higher Resolution
- 입력 해상도가 pretraining보다 커지면, positional embedding은 interpolation을 통해 조정.
- MLP head와 [DET] 토큰은 새로 초기화하여 사용하며, 나머진 finetune.
- Patch 크기 P=16은 그대로 유지, 따라서 더 많은 토큰이 입력됨.
6. Inductive Bias
-
YOLOS는 최소한의 inductive bias를 갖도록 설계됨.
-
ViT로부터 오는 bias는 오직 patch 추출과 positional embedding에서만 발생.
-
2D convolution, region pooling, pyramid feature 등은 전혀 사용하지 않음.
-
DETR 과의 차이점
- DETR은 Transformer 인코더-디코더 아키텍처. YOLOS는 Transformer 인코더만 사용.
- DETR은 CNN Backbone에만 pre-train 후 Transformer는 random init후 학습.
- 반면 YOLOS는 pretrained ViT로부터 자연스럽게 finetuning.
- DETR은 featuremap과 [DET] 쿼리 간의 cross-attention을 매 decoder 레이어마다 decoder loss를 써서 학습.
- 반면, YOLOS는 각 인코더 레이어마다 항상 하나의 시퀀스만 봄.
- 연산 측면에서 [PATCH] 토큰과 [DET] 토큰을 구별 X.
Result 중 주목할 것
- ImageNet-1k만으로 pre-train한 vanilla ViT만으로, 경쟁력 있는 성능 확보가능.
- 최소한 ViT 수정만으로 COCO benchmark에서 경쟁력 있는 성능 달성함.
- 최초의 순수 sequence-to-sequence 방식의 object detection.
- Vanilla ViT 기반 YOLOS의 detection 성능은 pre-train scheme에 민감, 성능이 아직 포화되지 않음.
- 따라서 YOLOS는 다양한 pre-training 전략(label-supervised / self-supervised) 평가용 benchmark로 활용 가능.

- YOLOS의 상위 10개 [DET] 토큰 visualization.
- 모든 이미지들에 대해 각 토큰들이 prediction한 위치를 point로 시각화
- 각 토큰들마다 위치 / 사이즈 별로 역할을 분배함을 볼 수 있다고,…? 함?
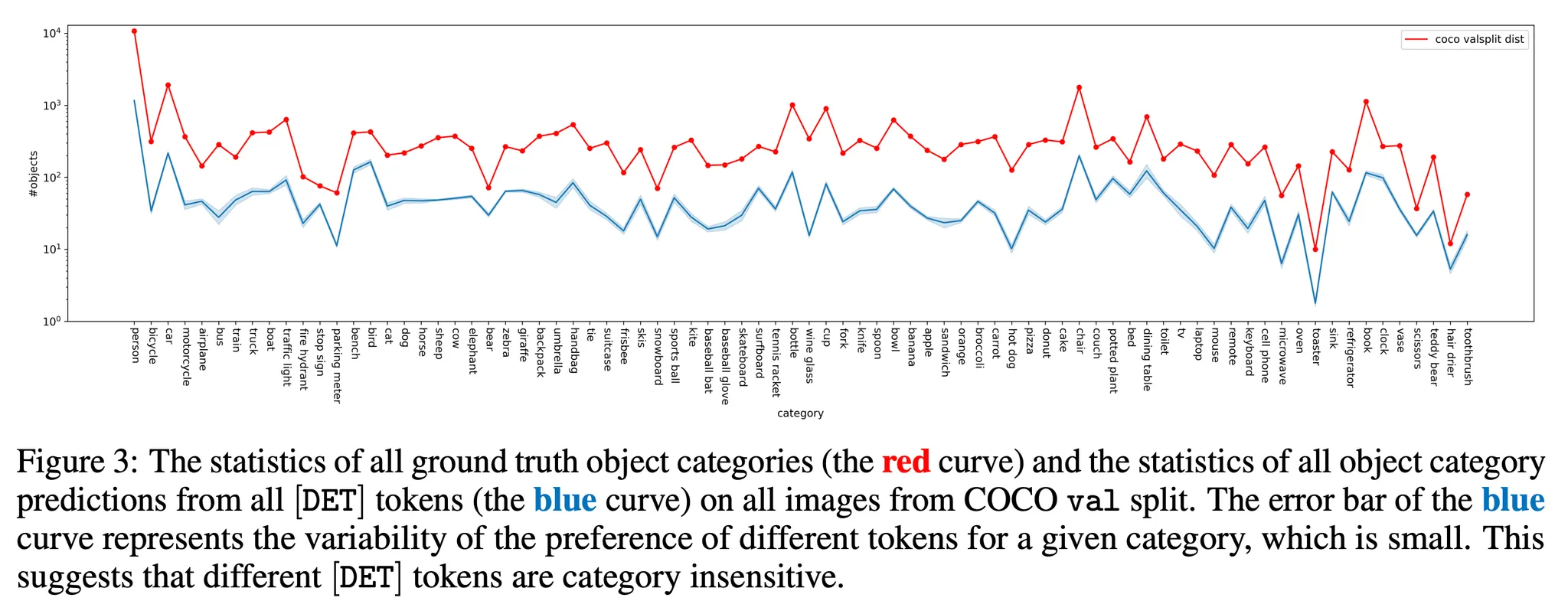
- 실제 데이터 레이블 분포와 토큰들이 예측한 클래스들의 분포가 비슷했음.
Discussion
- Computre Vision은 최근 Transformer에 의해 극적으로 변화하였음.
- Transformer에 inductive bias / prior를 추가하는 성능 지향적 아키텍처 설계가 잘못된 것이 아님.
- dense recognition 작업에서 성능을 향상시키는데 도움이 됨.
- 하지만 task-agnostic 하게 만들어서 general visual representation을 학습시키는 것도 중요함.
- NLP transformer는 매우 적은 fine-tuning만으로, downstream에서 훌륭한 성능을 냄 (LLM)
- 또는 zero-shot, few-shot도 가능함. (새로운 시나리오에 대한 가변성.)
- 그러나 ViT에 inductive bias 등을 주입하기 위해 사용하는 구조 변형은…
- 여전히 downstream task 학습을 위해 많은 학습이 필요함.
- 궁극적으로는 pretrained 모델을 downstream
Visiontask에 적용할 수 있어야 한다 주장.- 이를 위해선 pretrained representation의 여전히 개선이 필요하다고 주장.
- 즉, ViT 학습 방법론이 general한 feature space를 만들지 못한다는 것.
- 이를 위해선 pretrained representation의 여전히 개선이 필요하다고 주장.
- 결론:
- ViT를 변형할 때 task-oriented 아키텍처 설계에 빠지지 말 것을 권장.
- task-agnostic vanilla Transformer를 위한 general visual representation learning에 집중할 것
- 언젠가는 이것이 최소한의 비용으로 scene understanding을 하게 해줄 것이므로.
- 더 발전하여 generation task도 최소한의 비용으로 adaptation되기를..
