이전에 본 feature는 총 약 16만개 였다. 이렇게 많은 feature를 오버피팅 없이 몇 백개의 훈련 샘플만을 가지고 분류기를 학습할 수 있게하는 것이 AdaBoost이다.
그리고 Viola-Jones 알고리즘에서는 AdaBoost 분류기 여러개를 병렬 구조로 배치하여 얼굴을 분류한다.
AdaBoost of Viola-Jones Algorithm
입력: N개의 라벨링된 샘플
초기화: weight 초기화 ()
(i번째 데이터, t번째 약한 분류기)
for t=1 to T do
1. weight 정규화.
3. error 계산.
2. h_t 선택.
4. alpha, beta 계산.
5. update weight.
endfor
Output Classifier1. weight 정규화
2. error 계산
모든 피처 데이터에 대해서 에러를 계산한다.
3. 선택
가 가장 작은 를 선택한다.
4. alpha, beta 계산
가 증가하면 는 감소하고, 는 증가한다.
가 감소하면 는 증가하고, 는 감소한다.
5. update weight
인 만을 취한다고 하면 의 범위가 0~1로 한정되고, 의 값은 약한 분류기가 맞춘 데이터에 대해서는 이 되고, 틀린 데이터에 대해서는 이 되므로, 틀린 데이터에 대한 가중치를 높게 주는것이 된다.
6. Output classifier
위 식에 의해 최종 분류기의 출력을 결정한다.
Cascade Classifier
Viola-Jones Algorithm에서는 위와 같은 AdaBoost 분류기를 여러개 사용했다.
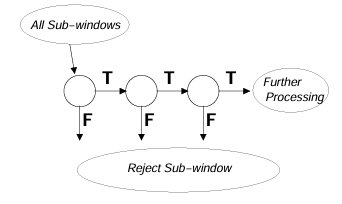
접근은 다음과 같다.
- 6 Stages
- Stage 1: 2개의 약한 분류기
- Stage 2: 10개의 약한 분류기
- Stage 3: 25개의 약한 분류기
- 나머지 Stage: 50개의 약한 분류기
weak classifier의 수 결정
각 단계의 분류기안의 weak classifier의 수 (위의 pseudocode에서의 T)는 FPR(False Positive Ratio)에 의해 결정된다. 즉 분류기가 얼굴이라고 분류했지만 틀린 데이터의 비율을 통해 결정한 것이다.
각 stage에서의 FPR의 상한을 결정한다. Viola, Jones는 논문에서 Stage1의 최대 FPR을 0.4로 설정했고, 목표 FPR을 정한 뒤, 일정 비율만큼씩 줄어들게 설계했다.
Stage의 수를 , 목표 FPR을 라고 했을 때,
로 설정하고, 로 설정하면 최종 출력의 가 원하는 값이 나오는 것이다.
각 단계에서 설정한 FPR을 만족할때 까지 weak classifier를 추가했더니
stage1에서 2개, stage2에서 10개, stage3에서 25개, 나머지 stage에서 50개가 나왔다는 것이다.
FNR
단계별로 FPR을 통해 약한 분류기의 수를 결정했는데, 전체 FN(False Negative, 얼굴인데 얼굴이 아니라고 분류한 데이터)의 수를 줄이기 위해, 단계별로 FN 또한 특정되어야한다.
Stage1에서는 FNR(False Negative Ratio)가 0이어야만 한다. 이후 단계에선 FNR을 특정한다.(ex. 0.01)
Normalize Image
조명 차이에 의한 효과를 최소화 하고, 성능을 높이기 위해 이미지 정규화를 한다.
- 입력 이미지 전체에 대한 정규화
- 훈련 샘플 이미지에 대한 정규화
위 두가지 상황에서의 이미지 정규화를 생각해볼 수 있다.
입력 이미지 전체에 대한 정규화
-
Gray-after-Gamma
-
Histogram Equalization
RGB Image -> Gray-Scale -> Histogram Equalization
Gray-after-Gamma는 지수계산이 있어 계산이 더 빠르고 비슷한 효과를 가진 히스토그램 평활화를 사용하기도 한다.
훈련 샘플 이미지에 대한 정규화
정규 분포로 정규화 한다. (평균은 0, 분산은 1이 되도록)
