ComputerVision
1.[Vision] 원근 투영(Perspective Projection)과 Lens Distortion Model
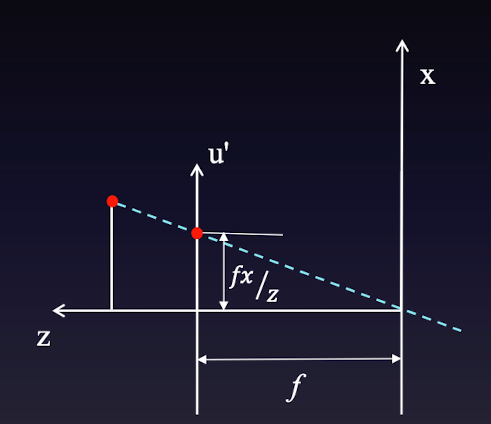
카메라 모델이 위와 같다고 할 때 image plane을 z축에 대해 원점 대칭이동시켜서 아래와 같이 생각할 수 있다.이때 원래 image plane의 좌표 상하좌우가 뒤집힌 상태이다.실제 세상의 좌표 (x,y,z)가 image plane에 (u', v')으로 투영된다
2.[Vision] Color Transform
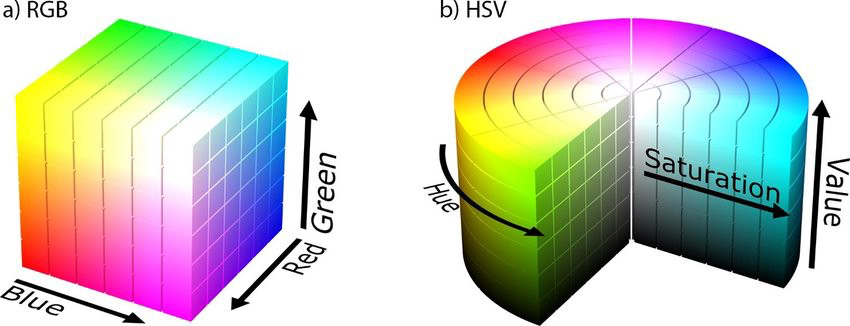
흰색은 모든 볼 수있는 주파수로 구성됨(400-700)사람이 볼 수 있는 빛은 400nm(blue) ~ 700nm(red)자외선과 x선은 매우 짧은 파장을 가짐적외선과 전파는 긴 파장을 가짐색공간에는 다양한 종류가 있다.RGBHVS(HIS)GRAYBINARYNRG밝기
3.[Vision] AdaBoost
Boostrapping 학습 샘플을 Z라고 할 때, Z로부터 중복을 허용하여 N개의 샘플을 반복적으로 뽑는다. 샘플의 각 세트에대해 통계적 파라미터를 추정. 각 분류기의 성능을 평가. Bagging For i=1~B: Z에서 중복 허용해 N개의 샘플을 뽑음.
4.[Vision] Viola-Jones Algorithm (1)

feature를 추출병렬 구조의 학습기scaling학습을 할때 24x24 서브 윈도우 이미지가 들어오면 haar-like feature로 feature를 생성하게 된다. Haar-like feature에는 4가지의 기본 커널이 있는데, kernel value(1x1),
5.[Vision] Viola-Jones Algorithm (2)
이전에 본 feature는 총 약 16만개 였다. 이렇게 많은 feature를 오버피팅 없이 몇 백개의 훈련 샘플만을 가지고 분류기를 학습할 수 있게하는 것이 AdaBoost이다. 그리고 Viola-Jones 알고리즘에서는 AdaBoost 분류기 여러개를 병렬 구
6.[Vision] Camera Calibration(Zhang's Method)
카메라 캘리브레이션은 카메라 변수로 부터 시작된다. 다시 식을 적어보자면, 이미지에 투영된 점의 동차좌표(Homogeneous coordinate)를 $\tilde U$라고 하고 현실의 동차 좌표를 $\tilde {x_w}$라고 하면 다음과 같은 수식을 적을 수 있다
7.[Vision] K-d Tree
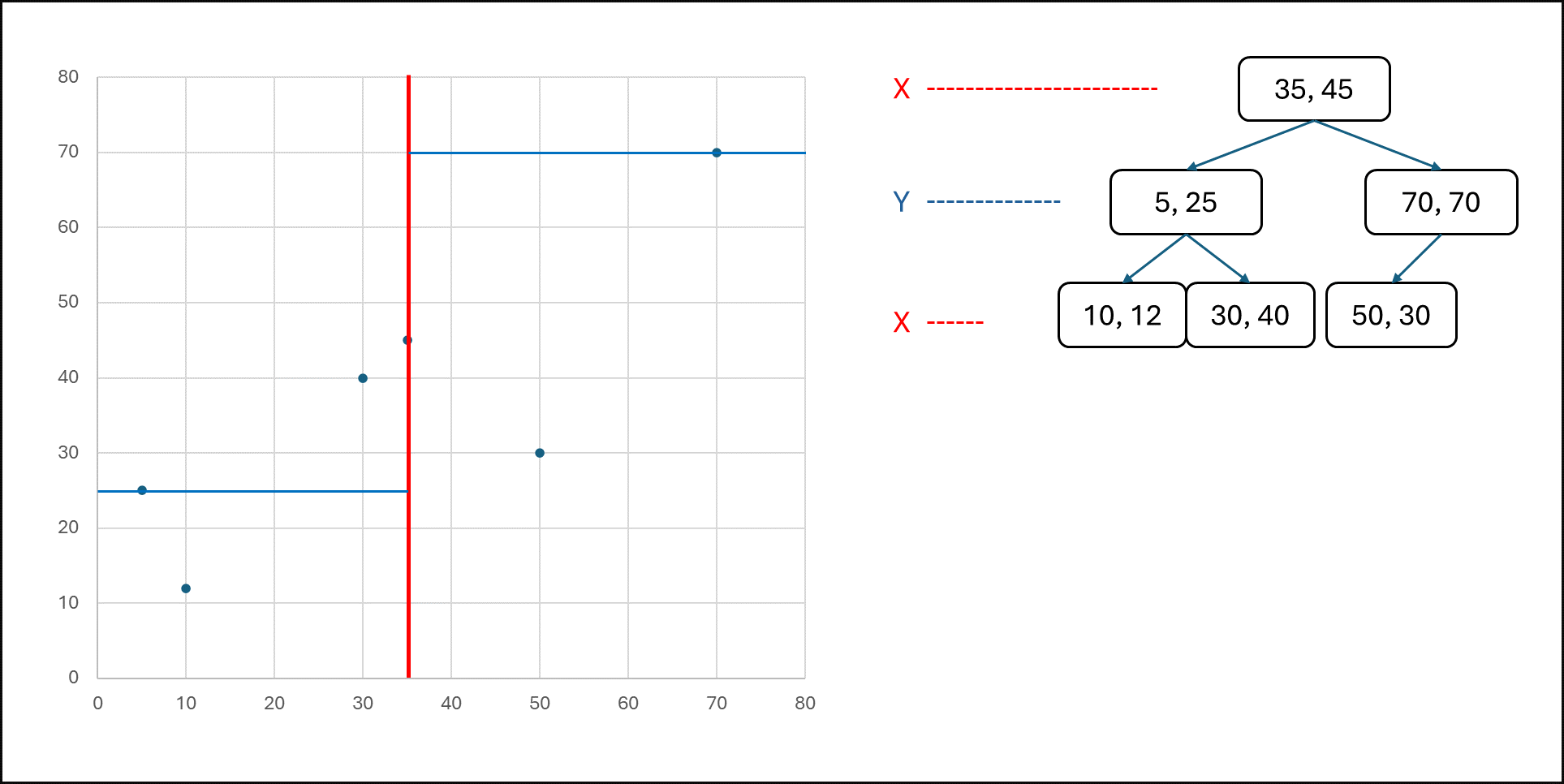
K-d 트리는 K-dimensional tree로 K 차원 공간에서 데이터를 partitioning 하는 기법. 모든 노드가 K차원 데이터를 가짐. non-leaf 노드는 공간을 반으로 나누는 hyperplane을 생성. 트리 아래로 내려가면서 차원을 순환. (ex.
8.[Vision] 3D Object Localization (1)
센서로부터 센싱한 포인트 클라우드 데이터가 있고, 원하는 물체의 모델 데이터가 있을 때, 포인트 클라우드 데이터로 부터 물체의 위치, 방향을 찾는 과정.입력: 포인트클라우드 쌍 (P, Q), (P: 모델, Q: 가진 데이터)출력: Q를 P로 정렬하는 transforma
9.[Vision] 3D Object Localization (2)
Algorithm > 입력: 포인트클라우드 쌍 (P, Q), (P: 모델, Q: 가진 데이터) > > 출력: Q를 P로 정렬하는 transformation T Gauss-Newton Method Least Square 최소 제곱법(Least Square)은 훈련