
Elasticsearch는 RDBMS나 Beats와 같은 다양한 저장소로부터 데이터를 입력 받은 Logstash를 통해 알맞게 가공된 Data를 제공받아 검색, 집계, 분석 등을 수행합니다. Elasticsearch는 검색을 위해 Data를 어떻게 처리하고, 또 Data 색인 중 어떤 과정이 이루어지는걸까요?
지난 블로그에서는 Logstash를 활용하여 Mysql에 존재하는 Data를 Elasticsearch로 전송하는 과정을 살펴봤습니다. Data를 연동하여 Elasticsearch로 Search가 가능하도록 하는 것도 물론 중요하지만, 우리가 원하는 Full-Text Search는 단순히 Database와 Elasticsearch를 동기화하는 것만으로는 부족합니다.
Elasticsearch는 Data를 검색에 맞게 가공하는 작업을 필요로 하고, 이는 Data를 저장하는 과정에서 이루어집니다. 이번 블로그에서는 Elasticsearch의 역색인(Inverted Index) 구조와 데이터 처리기능인 Analyzer에 대해 알아보겠습니다.
이 블로그는 Elastic 가이드북을 참고하여 작성하였습니다.
Inverted Index

보통 Mysql같은 관계형 Database에서는 위와 같이 Table을 작성하여 Data를 저장합니다. 위와 같은 Database에서 fow로 검색을 하고자 한다면 Table의 Row를 하나씩 살피면서 fow가 포함되면 Data를 가져오고 아니라면 넘어갈 것입니다.
SQL의 LIKE 검색은 위와 같은 방식의 검색을 하기 때문에 Data가 늘어날수록 모든 Row를 확인해 읽어야 하여 검색 속도가 기본적으로 느릴 수 밖에 없습니다.
Elasticsearch는 Data를 저장할 때 역색인(Inverted Index) 구조로 만들어 저장하여 빠른 속도로 검색이 가능하도록 합니다!
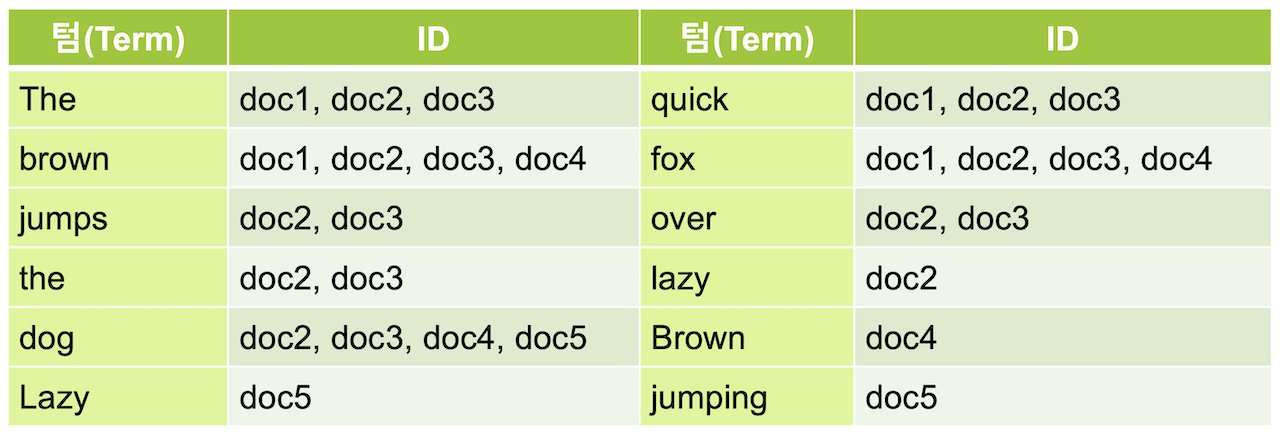
Elasticsearch는 위와 같이 Data로부터 Term이라는 Keyword를 추출하여, Term이라는 Inverted Index가 가리키는 Id를 저장합니다. 따라서 Mysql과 동일하게 fox로 검색을 하여도 모든 Row를 방문할 필요 없이 저장된 Id의 배열을 바로 얻을 수 있습니다.
이러한 Inverted Index는 Data가 저장되는 과정에서 만들어지기에 Elasticsearcch에서는 Data를 저장이 아닌 색인한다고 표현합니다.
Text Anaylsis
앞에서 Elasticsearch가 검색을 할 때 Inverted Index를 활용하고, Data를 색인할 때 Term이라는 키워드로 추출한다고 했습니다. 그렇다면 Elasticsearch는 어떤 방식으로 문자열 Field를 Term으로 처리할까요?
Elasticsearch는 검색어 Term을 저장하기 위해 Text Analysis라는 과정을 거치고, 이러한 과정을 처리하는 기능을 Analyzer라고 합니다. Analyzer는 0~3개의 Character Filter, 1개의 Tokenizer, 그리고 0~n개의 Token Filter로 이루어집니다.
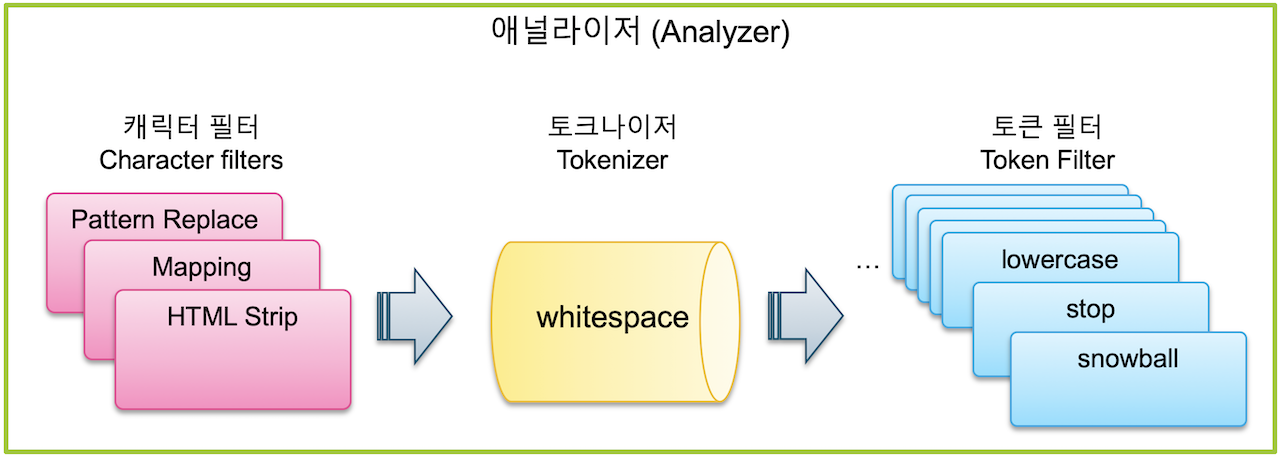
Character Filter
캐릭터 필터는 텍스트 분석 중 가장 먼저 처리되는 과정으로, Tokenizer에 의해 색인된 Text가 Term으로 분리되기 전에 전체 Text에 대해 적용되는 전처리 도구입니다. Elasticsearch 7.0 기준으로 HTML_Strip, Mapping, Pattern Replace 총 3개가 존재합니다.
HTML Strip
입력된 텍스트가 HTML 인 경우 HTML 태그들을 제거하여 일반 텍스트로 만듭니다. <>로 된 태그를 제거할 뿐 아니라 같은 HTML 문법 용어들도 해석합니다.
Mapping
Mapping 캐릭터 필터를 이용하면 지정한 단어를 다른 단어로 치환이 가능합니다. 특수문자 등을 포함하는 검색 기능을 구현하려는 경우 반드시 적용해야 해서 실제로 캐릭터 필터 중에는 가장 많이 쓰입니다.
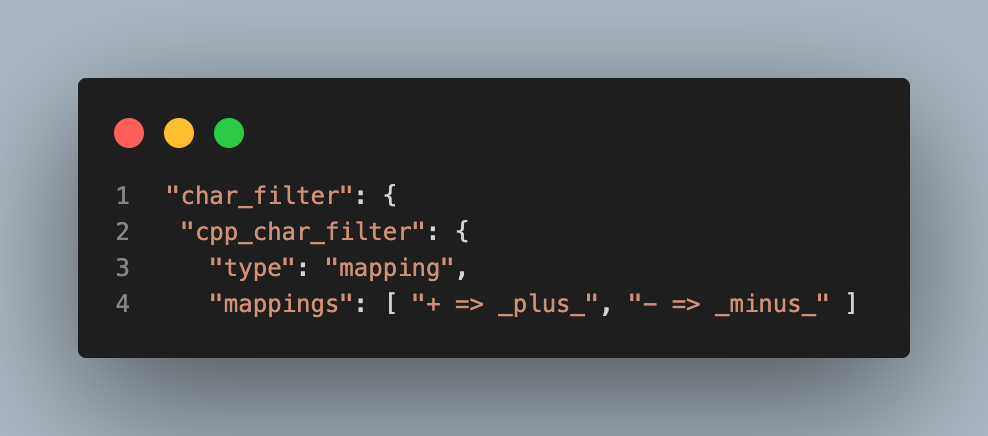
보통 Standard Analyzer는 +, -같은 특수문자를 불용어로 간주하고 제거하기 때문에 특수문자가 포함된 검색을 하기위해서는 먼저 특수문자를 다른 문자로 치환하여 저장해야 합니다. 예를 들어 "c++"을 검색하기 위해서 +를 _plus_로 치환하는 Character Filter를 아래와 같이 만들어줍니다.

Pattern Replace
Pattern Replace 캐릭터 필터는 정규식(Regular Expression)을 이용해서 좀더 복잡한 패턴들을 치환할 수 있는 캐릭터 필터입니다. 아래는 camelCase로 된 단어를 대문자가 시작하는 단위마다 공백을 삽입해 세부단어로 Token이 생성될 수 있도록 하는 Character Filter입니다.

이제 camel 인덱스에서 "FooBazBar" 라는 단어를 분석 해 보면 "foo", "baz", "Bar"와 같이 대문자 시작 단위로 Term이 쪼개어 색인되는 것을 확인할 수 있습니다.
Tokenizer
Data Indexing에서 가장 중요하고 큰 영향을 미치는 것이 바로 Tokenizer입니다. Tokenizer는 Character Filter로 전처리된 Text에 속한 단어를 Term 단위로 하나씩 분리해 처리하는 과정을 담당합니다. Data 분석 과정에서 Tokenizer는 반드시 한 개만 사용이 가능하며, 대표적인 3개의 Tokenizer를 살펴보겠습니다.
Standard Tokenizer
Standard Tokenizer는 공백으로 Term을 구분하면서 "@"과 같은 일부 특수문자를 제거합니다. "jumped!"의 느낌표, "meters."의 마침표 처럼 단어 끝에 있는 특수문자는 제거되지만 "quick.brown_FOx" 또는 "3.5" 처럼 중간에 있는 마침표나 밑줄 등은 제거되거나 분리되지 않습니다.
Letter Tokenizer
Letter Tokenizer는 알파벳을 제외한 모든 공백, 숫자, 기호들을 기준으로 Term을 분리합니다. "quick.brown_FOx" 같은 단어도 "quick", "brown", "FOx" 처럼 모두 분리됩니다.
White Tokenizer
Whitespace Tokenizer는 스페이스, 탭, 그리고 줄바꿈 같은 공백만을 기준으로 텀을 분리합니다. 특수문자 "@" 그리고 "meters." 의 마지막에 있는 마침표도 사라지지 않고 그대로 남아있습니다.
3개의 토크나이저 중에 Letter Tokenizer의 경우 검색 범위가 넓어져서 원하지 않는 결과가 많이 나올 수 있고, 반대로 Whitespace의 경우 특수문자를 거르지 않기 때문에 정확하게 검색을 하지 않으면 검색 결과가 나오지 않을 수 있습니다. 따라서 보통은 Standard Tokenizer를 많이 사용합니다.
Token Filter
Tokenizer로 Term을 분리해준 이후, 분리된 각각의 Term을 지정한 규칙에 따라 처리해줍니다. filter 항목에 배열 형태로 나열해서 지정해야 하며, 나열한 순서대로 적용되기 때문에 순서를 잘 고려해야합니다.
Lowercase, Uppercase
영어같은 경우 검색을 할때 대소문자를 구분하지 않고 검색할 수 있도록 처리해주어야 합니다. 보통은 Term을 모두 소문자로 변경하여 저장하는데, 이를 처리하는 Token Filter가 Lowercase 입니다.
Stop
Blog Post, News와 같은 글은 검색에서 큰 의미가 없는 조사나 전치사를 많이 포함하고 있습니다. 이렇게 검색할 때 쓰이지 않는 단어를 불용어(stopword)라 하여 Stop Token Filter를 적용해 불용어에 해당되는 Term을 제거할 수 있습니다.

위와 같이 in, the, days를 불용어로 처리하는 Custom Filter를 생성하여 적용할 수 있습니다.
TIL
이번엔 Elasticsearch가 가지는 큰 특징인 역색인 구조와 Analyzer에 대해 알아봤습니다. Data를 동기화하여 Elasticsearch에 색인할 경우 Analyzer를 사용하지 않는다면 일반적인 RBDMS에서의 like 검색과 다를 것이 없기 때문에 Analyzer를 잘 지정하여 사용하는 것은 매우 중요합니다. 그리고 이전 블로그에서는 Analyzer가 적용되지 않아 전체 Text 그대로 Term으로 색인되었습니다.
따라서 다음 블로그에서는 Full Text Search를 하기 위해 Custom Analyzer를 작성하고, Logstash에서 Elasticsearch로 데이터를 전송하는 과정에서 Index의 Setting과 Mapping을 어떻게 작성해서 적용하는지 알아보겠습니다.
