0. Abstract
Graph Neural Networks (GNNs)는 그래프의 representation 학습에 있어서 효과적인 프레임워크다. 많은 gnn 변형 모델들이 고안되었으며 노드와 그래프 분류 문제에 있어서 뛰어난 성과를 보였다. 그러나 GNN의 혁명적인 성과에도 불구하고, GNN의 representational properties와 한계점에 대한 이해는 아직 부족하다. 이 논문에서는 그래프들의 서로 다른 구조를 파악해내는 gnn의 능력에 대한 이론적인 틀을 제안한다.
GCN(Graph Convolution Network)이나 GraphSAGE와 같은 유명한 GNN의 변형 모델들의 뛰어난 능력을 설명하고, 이 모델들이 특정한 단순한 그래프 구조에 대해서는 구별을 하지 못하는 것을 보여준다. 그리고 더 나아가 새로운 단순한 모델 아키텍쳐를 제안한다. 새로운 모델은 Weisfeiler Lehman graph isomorphism test 만큼 강력하다.
1. Introduction
그래프 데이터를 학습하기 위해서는 그래프의 구조를 효과적으로 표현(representation)해내야 한다. GNN은 반복적인 aggregation 과정을 거친다. k번의 aggregation 과정을 거친 후 노드는 변형된 feature vector로 표현되며 이는 노드의 k-hop 이웃 안에서의 구조적인 정보를 담고 있다. 전체 그래프에 대한 representation은 pooling과정(예를 들어, 그래프에 존재하는 모든 노드 벡터들의 합)을 통해 얻을 수 있다. 이러한 GNN은 뛰어난 성과를 거뒀음에도 불구하고, 그 이론적인 틀은 부족하다. 따라서 이 논문에서는 GNN의 representational power에 대한 이론적 틀을 제안한다.
> insight
논문은 GNN과 Weisfeiler-Lehman(WL) graph isomorphism test의 유사성에서 아이디어를 얻었다고 한다. WL test는 GNN과 유사하게 이웃 노드들의 정보를 aggregate하는 과정을 통해서 노드의 feature vector를 업데이트 한다. WL테스트가 강력한 이유는 injective aggregation update 즉, 다른 이웃 노드들을 가졌다면 서로 다른 feature vector로 맵핑하기 때문이다. gnn또한 WLtest 처럼 injective function(단사 함수)로 모델링 한다면 매우 뛰어난 성능을 보일 것이다.
> multiset
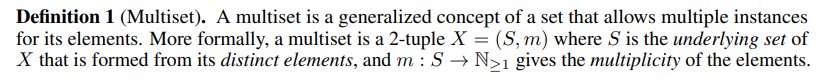
위의 인사이트를 수학적으로 공식화하기 위해서 주어진 노드의 이웃 노드들의 feature vector들의 집합을 multiset이라 표현할 것이다. 즉 하나의 집합에 동일 원소가 중복적으로 등장할 수 있다. 그렇다면 GNN에서의 이웃 노드 정보들의 aggregation과정은 multiset에 대한 aggregation function으로 생각할 수 있다. GNN 모델이 강력한 representational power를 갖기 위해서는 다른 multiset들을 서로 다른 representation으로 aggregate 해야한다.
> 논문 요약
1) 논문은 GNNs이 그래프의 구조를 구별하는데에 있어서 at most(기껏해봐야..?) WLtest만큼의 성능을 가졌음을 보여준다.
2) GNN이 WLtest만큼 강력하기 위한 neighbor aggregation과 graph readout functions의 조건을 설립하였다.
3) GCN과 GraphSAGE와 같은 GNN변형 모델들이 구별해내지 못하는 그래프 구조를 알아냈다. 그리고 GNN에 기반한 모델들이 구별해낼 수 있는 그래프 구조의 종류를 특성화 하였다.
4) 새로운 간단한 뉴럴 아키텍쳐, Graph Isomorphism Network (GIN)을 고안하였다. 그리고 이 모델이 WL테스트만큼의 power를 가졌음을 보여준다.
2. Preliminaries
논문에 제시된 사전 지식 설명 이외에 추가로 이해가 필요한 부분은 CS224W 강의를 참고하여 학습하였다.
1) Aggregate, Combine, Readout
현대의 많은 GNN 모델들은 이웃 노드들의 정보를 합하여 노드의 representation 을 update하는 과정을 반복하는 방식을 취한다. k번의 aggregation 후에는 노드의 representation은 k-hope network neighborhood의 구조적 정보를 갖는다.
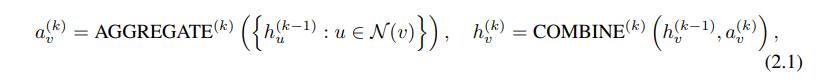
두 과정을 합쳐서 정리해보면, 다음과 같이 나타낼 수 있다.
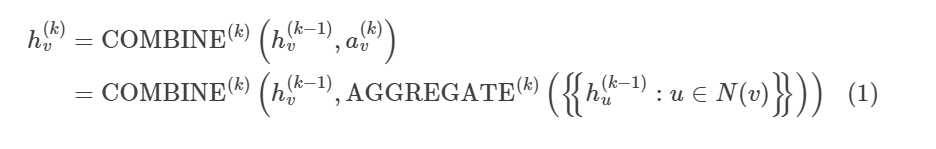
는 k번째 iteration/layer에서의 노드의 feature vector다. aggregate와 combine함수를 무엇으로 정하느냐는 gnn에서 매우 중요한 문제다.
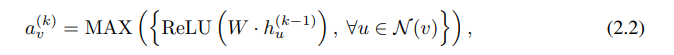
예를 들어, GraphSAGE는 위와 같이 aggregation함수로 max-pooling을 사용한다.
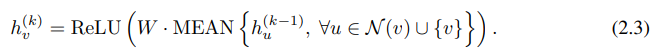
GCN은 AGGREGATE 함수로 MEAN POOLING을 사용한다. 위의 식은 GCN에서 AGGREGATE 와 COMBINE 과저을 합쳐서 한번에 표현한 것이다.
Node classification을 하는 경우, gnn의 마지막 레이어에서 얻은 feature vector 들로 prediction을 한다. READOUT 함수를 통해서 마지막 레이어에서 얻은 feature vector들을 모아 를 표현한다. 함수는 단순한 summation함수일 수도 있고 더 정교한 graph-level pooling function가 될 수도 있다.
2) Aggregation function이 왜 injective function이어야 하는가?
GNN은 그래프에 대해서 노드가 갖고 있는 변수에 대해서 접근하거나, 그래프의 구조를 이용한다. 만약 동일한 변수를 가진 노드로 구성된 그래프라면, 그래프의 구조를 이용하여 노드를 구분해야 한다.
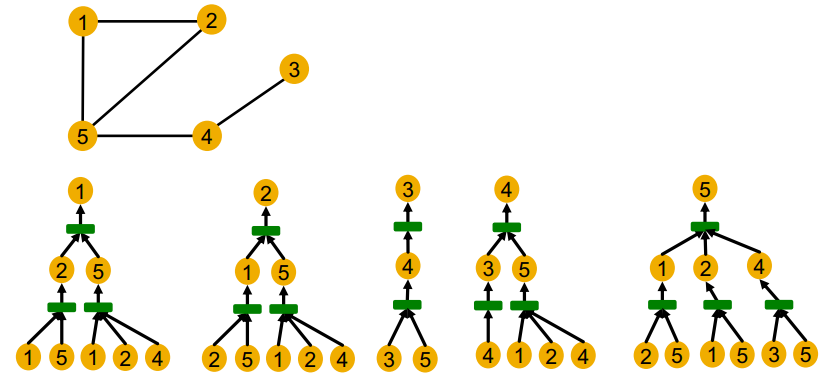
위의 그래프의 모든 노드에 대한 계산 그래프를 그려보면 다음과 같다. 1번 노드와 2번 노드는 같은 그래프 구조를 갖고 있고 3, 4, 5는 각기 다른 구조를 갖고 있다. GNN은 각 root node에 대한 작은 트리 구조에서 노드 임베딩을 구성한다. 표현력이 좋은 gnn이라면 각기 다른 트리 구조에 대해서 항상 다르게 임베딩 할 것이다. (그림에서는 임의로 각 노드에 대해서 id를 부여하고 있지만, 실제 gnn 모델에서는 주어지지 않는 정보다.)
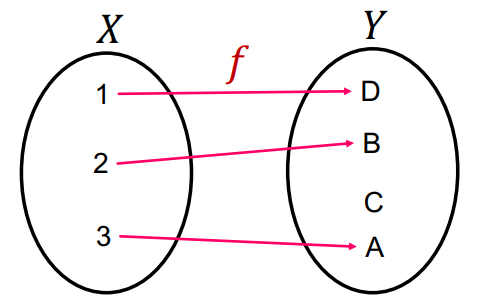
injective function(단사 함수)는 각기 다른 정의역 원소는 각기 다른 치역 원소로 mapping되는 함수이다.
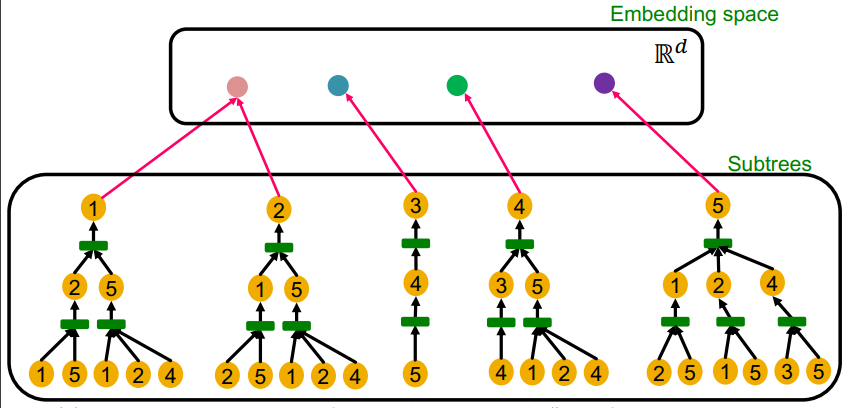
표현력이 좋은 GNN은 계산 그래프를 입력으로 하고 임베딩 벡터를 출력으로 하는 단사함수 즉, 각기 다른 구조의 계산 그래프에 대해서 각기 다른 임베딩 벡터를 출력하는 함수다.
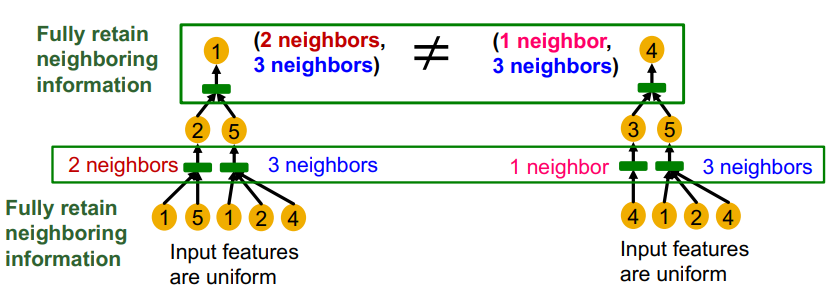
계산 그래프에서는 가장 아랫단 부터 aggregation function을 통해 정보가 처리된다. 이 aggregation function이 단사함수라면 표현력이 좋은 gnn이 될 수 있다.
3) WL test, WL Grpah Kernel
WL test에 대해서는 이 글을 참고하여 공부하였다 : https://process-mining.tistory.com/170
> Kernel Methods
- : 데이터(그래프)간의 유사도 계산
- : 임의의 함수 는 feature vector를 생성하는 함수이다.
- 함수 를 어떻게 정의하느냐에 따라 다양한 방법론이 존재한다.
> Weisfeiker-Lehman Kernel
3. Theoretical Framework : Overview
node input features는 countable universe로 부터 온다고 가정.
a maximally powerful GNN maps two nodes to the same location only if they have identical structures with identical features on the corresponding nodes
we abstract a GNN's aggregation scheme as a class of functions over multisets that their neural networks can represent, and analyze whether they are able to represent injective multiset functions.
4. Building Powerful Graph Neural Networks
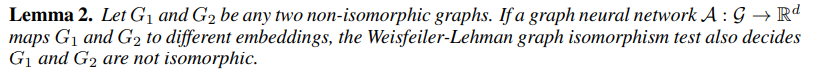
Lemma2 에 따르면, GNN은 서로 다른 그래프들을 구별해내는 능력이 WLtest보다 더 뛰어날 수 없다. WLtest가 구분하지 못하는 그래프들은 GNN 또한 구분할 수 없다. 그렇다면, GNN이 WLtest만큼의 power를 가질 수 있는가? aggregate과 readout functions이 injective하다면, 가능하다!

Theorem 3에서 와 는 각각 AGGREGATE와 COMBINE 함수를 의미한다. AGGREGATE, COMBINE, READOUT이 모두 multiset에 대하여 injective 하면, GNN은 WLtest와 같은 power를 가질 수 있다.
그렇다면, WLtest를 사용하면 되지 왜 GNN을 사용해야 하는가? GNN은 그래프 간의 유사성을 포착할 수 있다. 그러나 WLtest는 그래프 사이의 유사성을 알아낼 수 있는 능력이 없다. GNN은 그래프를 구분할 수 있는 것 뿐만 아니라,비슷한 그래프는 비슷하게 embedding 하도록 학습할 수 있어서 그래프 구조 사이의 유사성을 알아낼 수 있다.
5. Graph Isomorphism Network(GIN)
Theorem3를 만족하는 GNN 모델을 만들어보자.

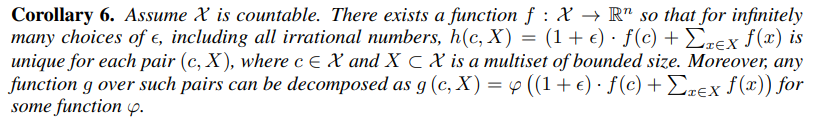
sum aggregators can represent injective.
mean aggregator같은 함수는 not injective하다. lemma5를 universal multiset function으로 사용하면 theorem3를 만족할 수 있다.

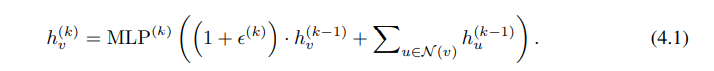
node classification과 linkprediction에는 위의 결과물인 노드 임베딩을 사용하면 되지만, graph classification을 하기 위해서는 readout function이 필요하다. readout function은 node의 feature vector들에 대한 함수다. iteration 수가 증가할 수록 node의 representation은 더 개선되고 global해진다. 그러나 때때로 반복횟수가 적을 때 더 잘 일반화 되는 경우도 있다. 따라서 적당한 수의 레이어를 거쳐야 한다.
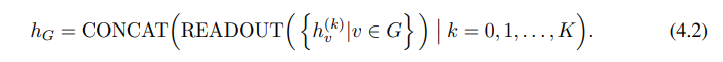
따라서 GIN은 READOUT의 OUTPUT을 모두 합쳐주어 최종 결과가 각 레이어의 그래프의 구조적 정보를 모두 포함하도록 한다.
6. Less Powerful But Interesting GNNs
(4.1) 식의 MLP, feature vector summation에 대한 ablation study.
- MLP 대신 1-Layer perceptron
- Summation 대신 mean/max - pooling
이 두 가지의 변화를 주면, 모델의 성능이 떨어진다는 것을 논문에서 보여준다.
6. Experiments & Result
논문에서는 GIN의 성능을 확인하기 위해 GIN과 다른 GNN 모델들의 graph classification 성능을 비교하였다. 4개의 bioinformatics datasets와 5개의 social network datasets에 대한 실험 결과를 보여준다. GIN 모델은 를 학습하는 GIN-과, 을 0으로 고정하는 GIN-0 모델을 사용하였다. 비교 모델로는 (4.1)의 summation을 mean-pooling 또는 max-pooling으로 바꾼 모델과, MLP를 1-layer perceptron으로 바꾼 모델들을 사용하였다.
Baseline 모델로는 graph classification의 state-of-art 성능을 보여주는 WL subtree kernel, C-SVM, Diffusion-convolutional neural network, PATCHY-SAN, Deep Graph CNN, Anonymous walk Embeddings을 사용하였다.
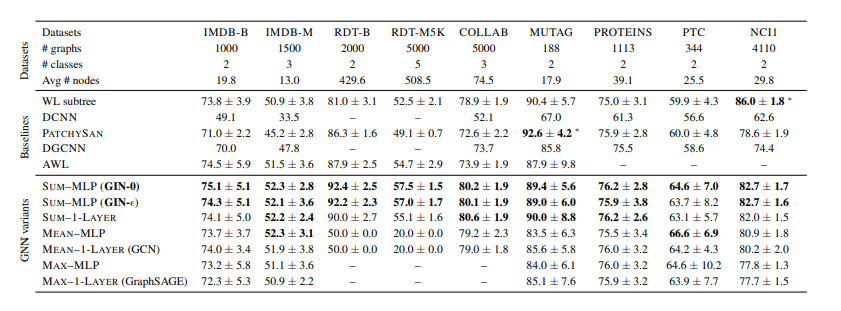
위의 테이블은 test set에 대한 classification accuracies를 보여준다. 가장 좋은 성능을 보이는 모델에 대하여 볼드처리를 해놨다. GIN모델들이 좋은 성능을 보이고 있는 것을 확인할 수 있다.
