1. Problem
Pretrained language Models을 기반으로 하는 Knowledge graph completion Models에 대한 많은 연구가 이어져 오고 있다. 하지만 기존 연구에는 다음과 같은 문제점들이 존재한다.
1) Inaccurage evaluation setting
2) Inappropriage utilization of PLMs.
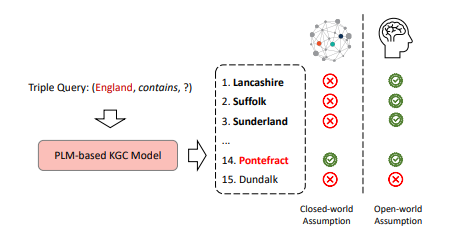
The evaluation setting unser the closed world assumption (CWA) may underestimate the PLM-based KGCmodels since they introduce more external knowledge.
Most PLM-based KGC models simply splice the labels of entities and relations as inputs, leading to incoherent sentences that do not take full adventage of the implicit knowledge in PLMs.
2. Preliminary
Closed word assumption (CWA)
주어진 kg에 등장하지 않는 triple들은 틀린 것이라고 가정하는 것이다. 즉, 모델 테스트 시 전체 데이터셋에 존재하는 트리플에 대해서만 정답이라고 판단하는 것이다.
Open word assumption (OWA)
OWA에서는 kg에 없는 triple이어도 정답이 될 수 있다. 실제 현실세계의 시나리오에 더 근접하며 보다 더 정확한 평가를 내릴 수 있으나, 완성된 triple이 kg에 없을 시 이것이 정답인지 아닌지 판단하기 위해 추가적인 작업이 필요하다.
Prompt-based learning
NLP 분야에서 거대 언어 모델이 등장한 이후로 (ex. BERT, GPT) 모델을 사전학습 한 후 각 task에 맞게 fine-tuning하는 방식이 많이 사용되어 왔다. 그러나 몇몇 연구에서는 이 방식에 큰 문제점이 존재한다고 지적했다. pre-training 할때와 fine-tuning 할때의 objective forms에 큰 gap이 존재한다는 것이다. 이는 PLM의 지식을 완전히 사용하지 못한다는 제약이 생긴다.
이러한 문제를 해결하기 위해 Prompt tuning이 제시되었다.
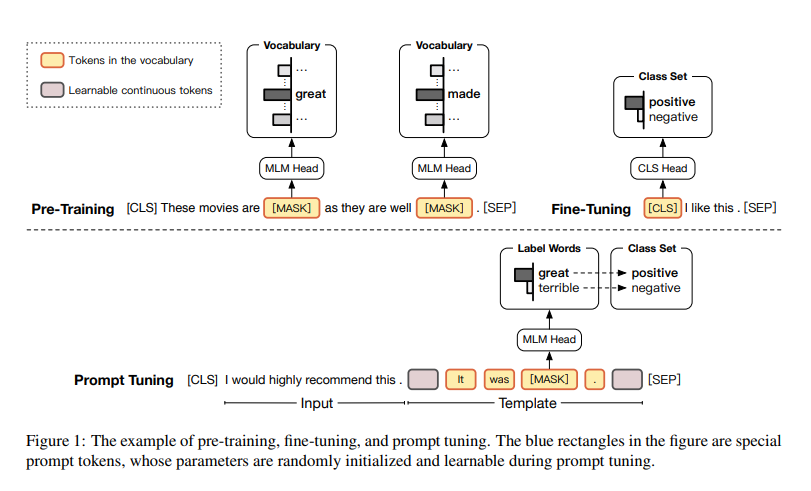
위의 그림과 같이 prompt는 templtate과 label words set으로 이루어져 있다. 원래의 input과 [MASK]토큰을 예측하기 위한 Prompt template을 합치고, 예측된 단어에 상응하는 label을 맵핑함으로서 prompt tuning은 binary classification task (fine tuning task)를 cloze-style task로 바꿀 수 있다.
그러나 많은 클래스를 분류해야하는 태스크라면 수동으로 적절한 탬플릿과 서로 다른 클래스들을 구분하기 위한 적절한 라벨 단어를 찾아내는 것은 매우 어려워진다. 이문제를 해결하기 위해 자동으로 prompt를 생성하는 방식의 연구가 이어져 왔으나 이 방식 또한 많은 노동을 피할 수 없다.
3. Method
Models aims to do knowledge graph completion tasks : (h,r,?) or (?,r,t) and Triple Classification task.
3.1 Framework for PKGC (PLM-based KGC)
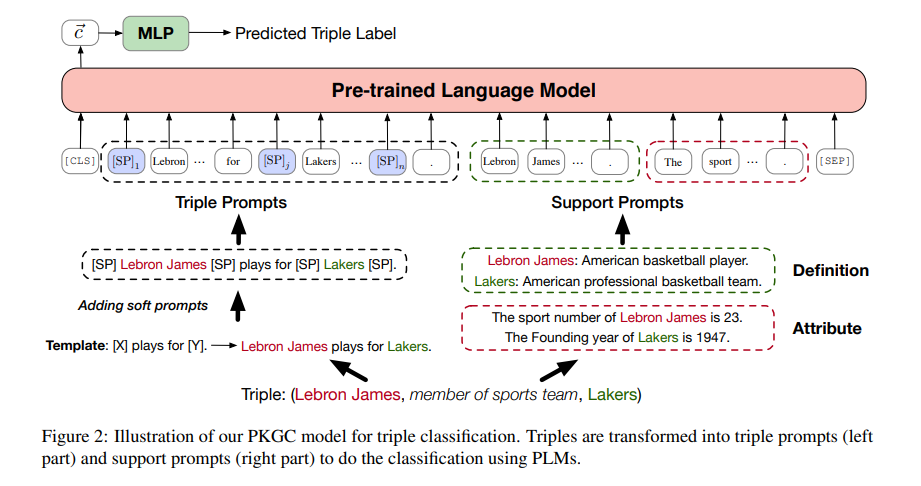
전체적인 큰 틀 부터 살펴보면, input triple이 주어지면 모델은 input을 Triple prompts 와 support prompt 로 변형한다. 그리고 이 두 prompt가 함께 PLM에 들어간다. 즉, 최종적인 모델의 Input text는 T= [CLS][SEP]로 정의된다. [CLS]의 OUTPUT은 주어진 Tripe의 label을 예측하는데에 사용된다. 추가로, 본 모델에서는 triple classification task를 위해 positive/negative triples 을 모델에 학습시켰고(contrastive learnning) cross-entropy loss를 사용했다고 한다.
3.2 Triple Prompts ,
우선 모든 realtion 에 대하여 데이터셋마다 수동으로 hard template을 디자인하였다.
Ex)
relation : member of sports team
hard template : [x] plays for [y]
위의 예에서 [x], [y]에는 각각 head entity, tail entity가 들어가게 된다. 이렇게 형성된 template에 soft prompts 를 더하여 최종적인 Triple prompts를 완성한다.

soft prompt는 tiple prompts를 좀 더 expressive(표현력있게)만들기 위해 사용했다고 한다. soft prompt를 위한 vector lookup table 을 둔다.
n: total number of soft prompts,
d: dimension of the word vector
k번째 soft prompt 가 input으로 들어오면 에서 이에 상응하는 word vector를 찾아 그 값으로 대체된다. 모델 훈련기간 동안 는 update된다.
3.3 Support prompts,

모델에 추가적인 정보를 주어 kgc에 도움을 주기 위해 definition이나 attribute같은 input을 주었다고 한다. 위의 테이블과 같은 template의 형식으로 모델에 들어가게 된다. 하나의 트리플에 상응하는 attribute는 많을 수 있기 때문에 이 경우 random하게 몇가지 attributes를 선택했다고 한다.
그러나 data에 추가적인 support information이 존재하지 않으면, 모델 input에 추가하지 않았다고 한다.
3.4 Training

4. Experiments
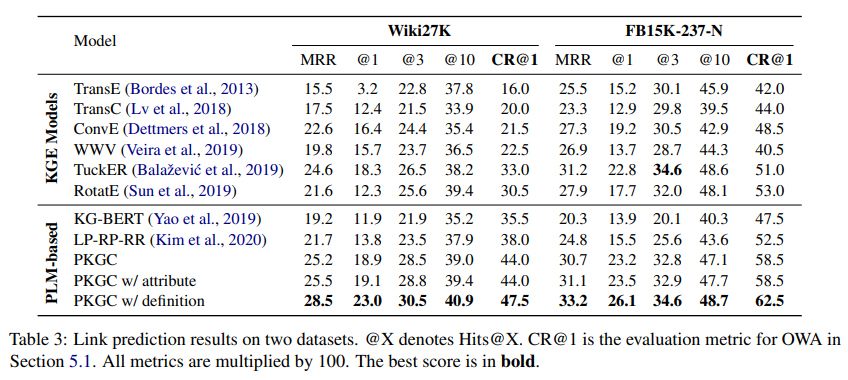
for link prediction, use CR@1
CR@1 : sample triples from test set and fill the missing entity with top-1 predicted entity. then mannually annotate the correct ratio of these triples.
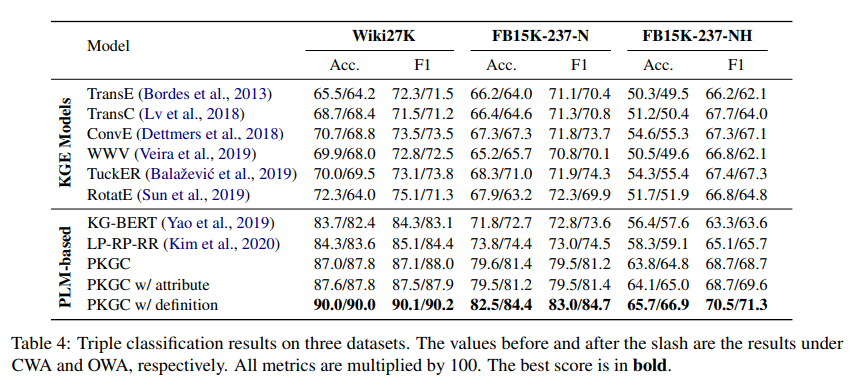
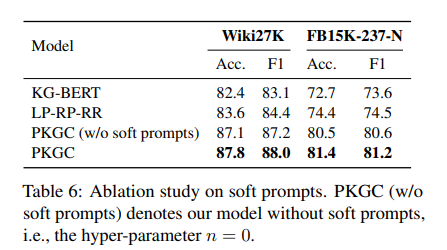
for triple classification, use Accuracy and F1.