[논문 리뷰] From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer (WWW, 2022)
논문 리뷰
1. Overview
- mainly target Link Prediction
- Propose new model named GenKGC
- Convert link prediction to sequence to sequence generation.
- Use pretrained lanuage model (BART) to generate target entity.
- Propose relation guided demonstration and entity-aware hierarchical decoding.
- Release new large scale chinese KG dataset, OpenBG500.
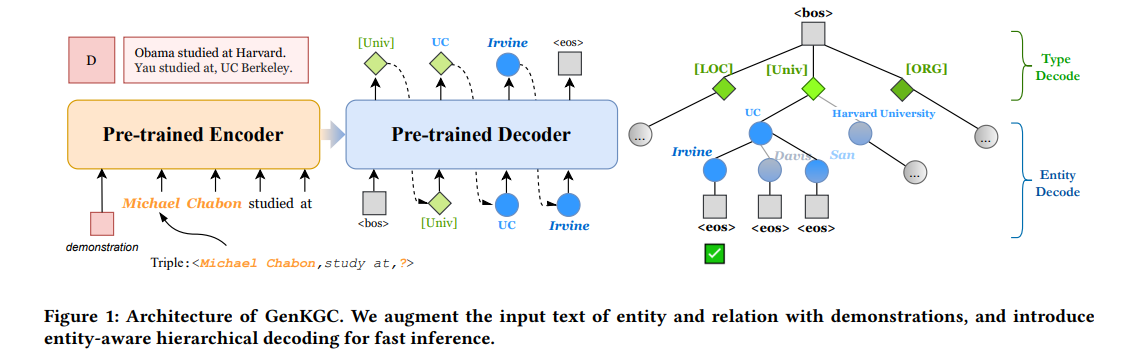
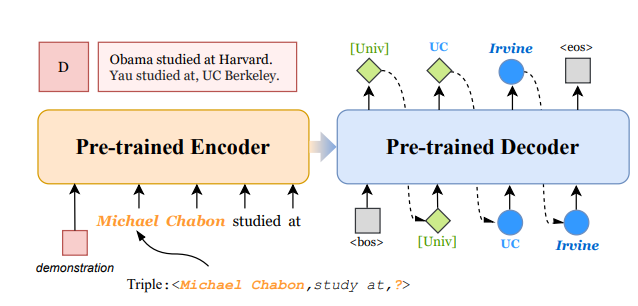
2. Method
1) Link Prediction as Seq2Seq Generation
)
: A set of entity
: Relation types
: A set of triples
: Entity categories
: Entity descriptions
Link prediction :
모델의 input을 Triple에서 sequence로 바꾸는 방식은 KG-BERT의 방식을 따른다. entity, relation 각각에 대한 description 을 concatenate하여 모델의 input으로 넣어준다.
GenKGC 는 PLM으로 BART를 사용하며, 모델의 기본 구조 또한 BART를 그대로 따른다.
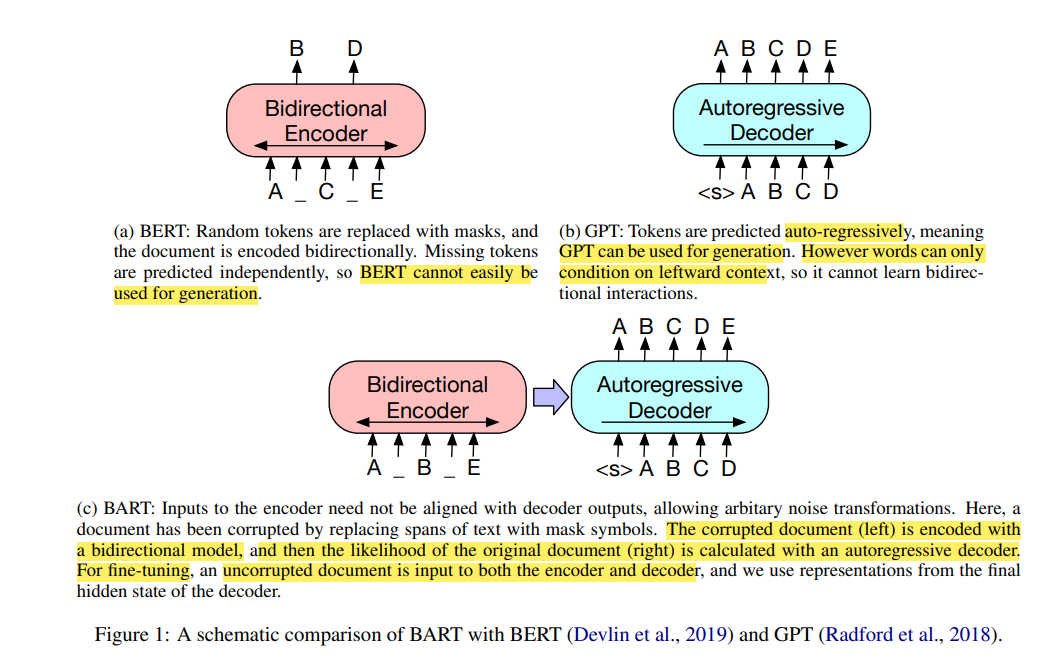
왜 BART를 PLM으로 채택했을까?
BART는 손상된 text를 input으로 받아서 노이즈를 없애는 작업을 진행한 후 손상되기 전 원래의 정답을 생성한다. BERT의 Bidirectional encoder 구조와 GPT의 Autoregressive decoder 구조를 함께 갖고 있고, noising flexibility를 갖는다. 그리고 특히 text generation task에 fine-tuning할 때 효과적이라고 한다.
2) Relation-guided Demonstration
KG는 long-tailed distribution을 갖는 경우가 존재한다. 예를들어 FB15k-237 dataset에서 relation 'film/type_of_appearance'는 37개의 instancess만 존재한다.
이전 연구에서는 랜덤하게 샘플링된 인스턴스들을 demonstrations로 취급하여 input에 함께 넣어주는 것이 더 좋은 few-shot performance를 낼 수 있다는 것을 밝혀내었다.
본 논문에서도 이러한 방식을 따라 input relation 와 같은 relation을 갖는 몇 개의 triples을 training set에서 sampling하여 concatenate 한 후 모델의 input으로 함께 넣어준다.
최종적인 모델의 Input은 아래와 같다.
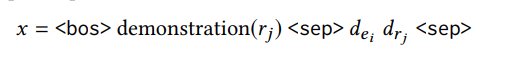
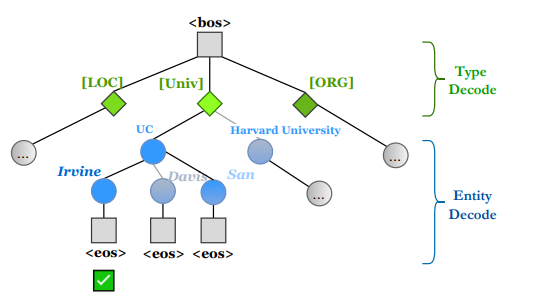
3) Entity-aware Hierarchical Decoding
top-k개의 후보 entities를 얻기 위해 Beam Search를 사용한다.
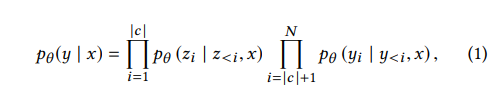
위 식을 통해 entity에 대한 score를 계산하여 entity의 rank를 결정한다. 위 식에서 는 카테고리 에 있는 토큰들의 집합이다. 는 의 textual representation에 있는 N토큰들의 집합이다.
추가로, 논문에서는 낮은 빈도를 갖는 Entities들을 구별해내는 것은 어려운 일이기 때문에 이러한 엔티티들에 대하여 decoding을 강요한다고 한다(constrain the entity decoding). 즉, 낮은 발생빈도를 갖는 entity type category를 sampling하여 이 type에 대한 token을 PLM의 vocabulary에 추가한다고 한다.
그리고 생성된 entity가 후보 entity candidate set에 있는지 확실하게 알기 위하여 prefix tree를 구성한다고 한다.
그리고 아래의 standard seq2seq objective function을 사용하여 최적화를 진행한다.
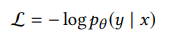
3. Experiments
3가지 dataset (FB15k-237, WN18RR, OpenBG500)에 대한 Link prediction 실험을 진행하였다. OpenBG500은 본 논문에서 새롭게 만든 dataset으로 e-commerce description page에서 추출한 중국어 entity와 relation으로 이루어져있다.
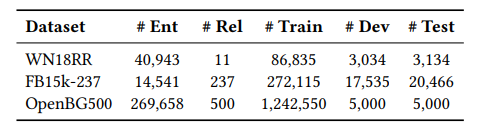
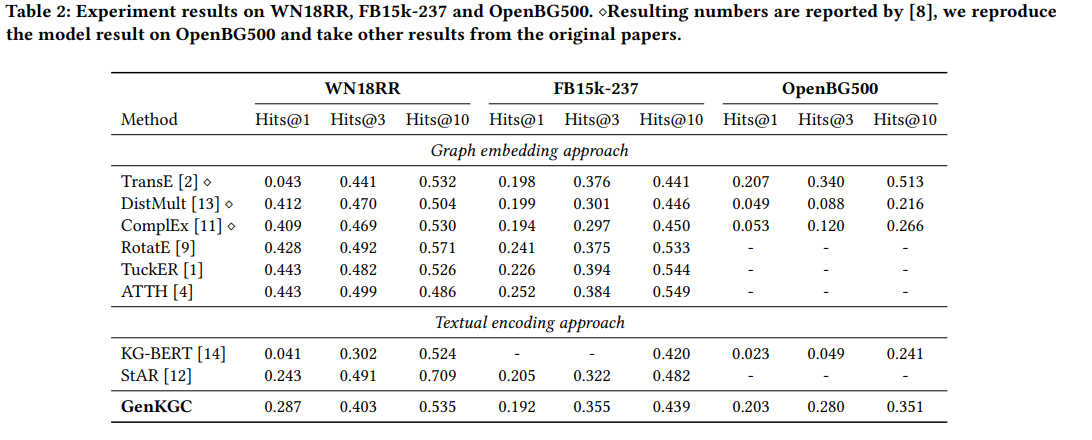
실험 결과를 확인해보면 KG-BERT보다는 좋은 성능을 보이고 있지만 기존의 Graph embedding 방식보다는 좋은 성능을 보이지 않으며 stAR보다도 뒤떨어지는 부분이 존재한다. 하지만 TransE가 260M 파라미터가 필요한것에 비해 (OpenBG500 dataset에 대하여) plm 모델은 (bert or bart) 110M 파라미터가 필요하기 때문에 memory측면에서는 훨씬 효율적이라고 한다.

위 실험 결과는 Hierarchical decoding 방식의 성능에 대한 ablation study결과다. Hierarchical decoding방식을 사용하지 않을 경우 normal beamsearch방식을 사용하였다고 한다. 실험 결과를 보면 without model의 경우 충분하게 정확하지 않은 답변에서 조기에 멈출 수 있다. 논문에서는 이러한 이유를 plm의 bias때문이라고 말한다. 높은 빈도를 갖는 토큰들이 plm이 특정한 답변에 대한 bias를 갖게 한다고 말한다.
hierarchical decoding방식을 사용한 모델의 경우 bias effect를 조금 완화시켰다는 것을 위 실험결과로부터 알 수 있다.
4. Contributions & Limitations
- SOTA를 달성하지 못했다!
