[논문 리뷰] SimKGC : Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models (ACL, 2022)
논문 리뷰
key word : Knowledge graph completion, contrastive learning, bi-encoder, BERT
1. Introduction
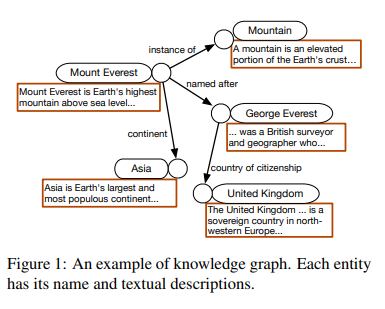
Knowledge graph completion 분야에서는 최근들어 Knowledge graph의 각 entity에 대한 text description 정보를 활용하여 prediction을 진행하는 방향으로 연구가 활발하게 진행되고 있다. BERT와 같은 Pre-trained large language model을 함께 사용하므로서 Knowledge graph completion에 풍부한 text정보를 추가적으로 사용할 수 있도록 하였다. 하지만 모델 퍼포먼스를 살펴보면 기존의 graph embedding based methods(RotateE, TransE)보다 훨씬 긴 inference time이 소요되고 심지어 성능은 더 뒤처지는 결과를 보였다. (ex. KG-BERT)
본 논문에서는 text based method의 성능 저하의 이유를 'inefficiency in contrastive learning' 때문이라고 보았다.
2. Problem
tail entity prediction :
head entity prediction :
How can we do efficient contrastive learning?
3.Method
1) Notations
For each triple , add an inverse triple . Therefore, we only need to deal with the tail entity prediciton problem.
- or
2) Model Architecture
본 논문에서는 Knowledge graph completion에 contrastive learning 방식을 사용한다.
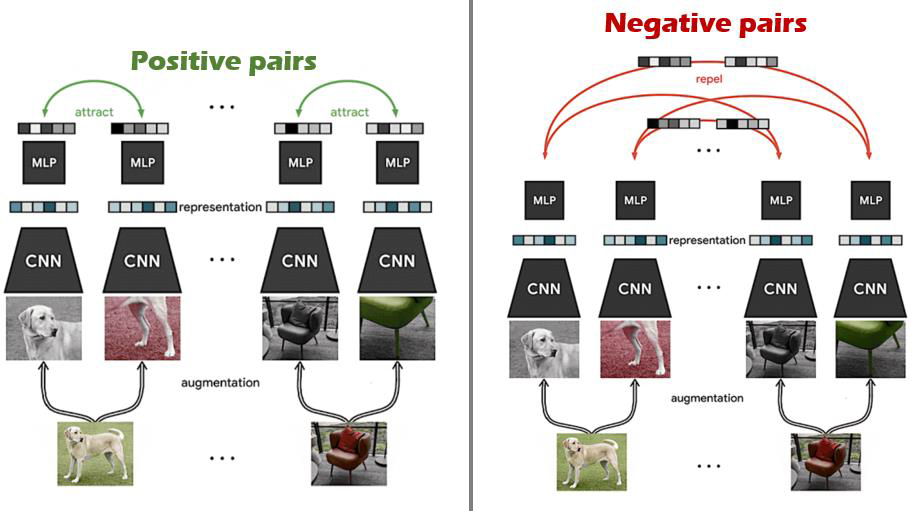
contrastive learning은 Representation learning의 한 방식이다. 이미지 분야에서는 위의 그림과 같이 이루어진다.이미지 데이터를 예로 들어 설명하면, 같은 이미지에서 나온 데이터를 Positive pair, 서로 다른 이미지 쌍 데이터를 Negative pair라 정의한다. 입력 데이터 쌍이 주어지면 두가지 입력에 대한 임베딩을 각각 구하고, 임베딩 간 유사도를 계산한다. Positive pair에 대해서는 유사도가 높게, Negative pair에 대해서는 낮게 측정하도록 학습된다. 대표적인 contrastive loss에는 InfoNCE가 있다.
이러한 학습 방식을 KGC에 적용하여 true triplet은 Positive로 false triplet은 Negative로 정의한 후 학습을 진행한다.
2-1. Bi-encoder Architecture
BERT를 사용하여 두 문장간의 유사도를 구하는 방식에는 cross-encoder 구조와 bi-encoder 구조가 존재한다.
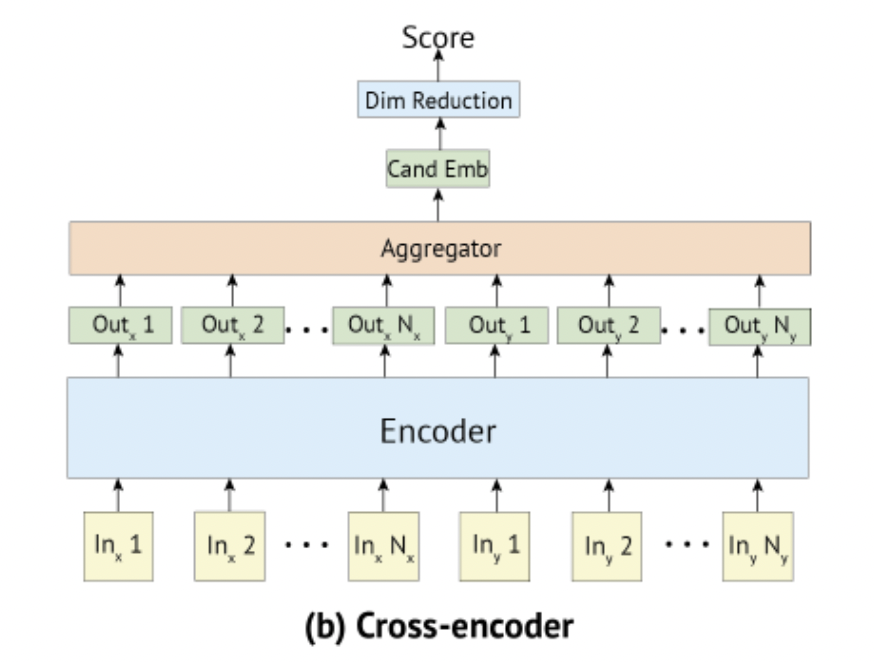
KG-BERT에서는 두 입력 문장 사이의 유사도를 구하기 위해 문장 사이에 [SEP]토큰을 두어 두 문장이 한번에 인코더의 입력으로 들어가는 Cross-encoder 방식을 사용했다. 이러한 방식의 문제점은 많은 연산량이 필요하다는 것이다. 그리고 각 문장의 임베딩을 인코더가 학습했다고 보기 어렵다.
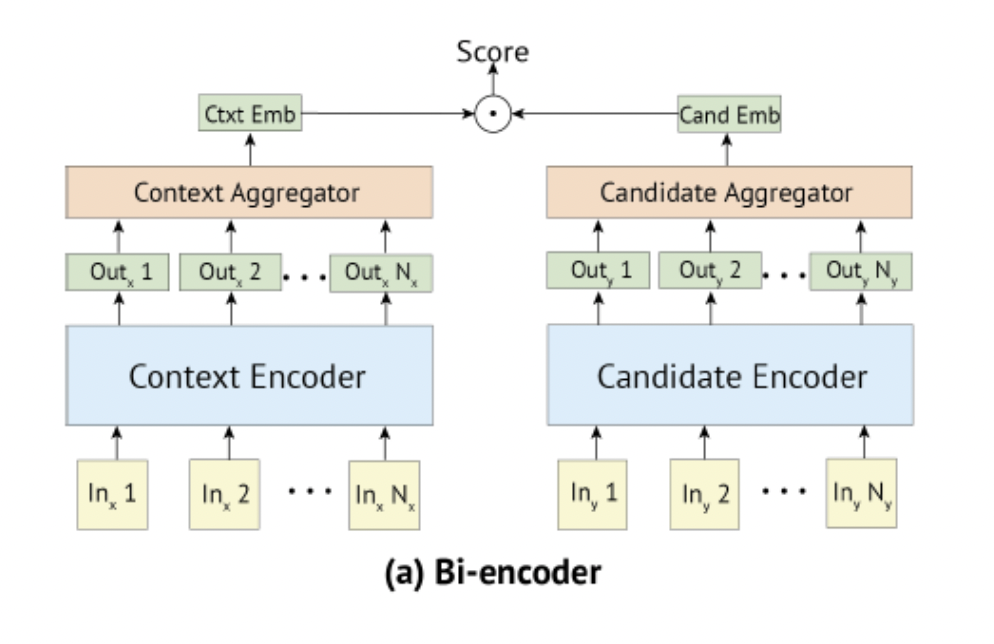
Bi-encoder 구조를 사용하면 위의 두가지 문제점을 보완할 수 있다. 두 개의 인코더를 사용해서 두 입력 문장의 임베딩을 각각 따로 학습한다. 이렇게 구한 두 임베딩의 유사도를 나중에 계산하는 방식으로, cross-encoder보다 훨씬 효율적으로 학습을 진행 할 수 있다.
본 논문에서는 Knowledge Graph Completion에 Bi-encoder 구조를 사용한다.
- get relation-aware embedding
- text descriptions of + [SEP] + text descriptions of
- instead of using the hidden state of the first token (ex.[cls]), use mean pooling followed by normalization
- get tail entity enbedding
- input only consists of the textual description for entity t
- use mean pooling
Similarity function
For tail entity prediction,
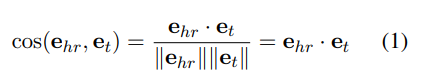
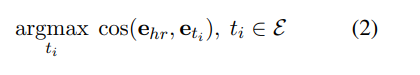
2-2. Negative sampling
contrastive learning을 하기 위해서는 하나의 positive triplet 에 대하여 하나 혹은 여러개의 negative triples이 필요하다. 보통 혹은 를 랜덤하게 선택하여 false negative entity로 대체하는 방식을 사용한다. 본 논문에서는 training efficiency를 개선하기 위하여 3가지 종류의 negatives를 함께 사용한다.
- In-batch Negatives (IB)
vision분야에서 널리 쓰이는 방법이다. 같은 배치에 있는 엔티티들을 negatives로 사용한다. 이 방식은 bi-encoder 구조에서 엔티티 임베딩을 재사용할 수 있기 때문에 효율적이다. - Pre-batch Negatives (PB)
in-batch 방식의 단점은 negatives의 수가 batch사이즈에 한정된다는 것이다. 보통 negatives의 수를 늘리는 것이 contrastive learning에 효과적이라고 알려져 있다. Pre-batch 방식은 이전 배치들에 있는 엔티티의 임베딩을 negatives로 사용한다. 보통 1-2개의 pre-batches가 사용된다. - Self-Negative (SN)
negative의 수를 늘리는 것 외에도 정답 entity와 가까이 있어 구분하기 힘든negative를 사용하여 모델의 분별력을 키우는 것도 contrastive learning에 있어서 중요하다. 이러한 negative를 hard negative라 한다.tail entity prediction의 경우 head entity 가 hard negative로 작용할 수 있다.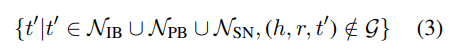
2-3. Graph-based Re-ranking
Knowledge graphs에서는 멀리있는 엔티티들보다 가까이 있는 엔티티들끼리 더 관련성이 있는 spatial locality inductive bias가 존재한다. Text-based KGC method는 이러한 inductive bias를 완벽하게 포착해내지 못한다.논문에서는 이 점을 보완하기 위해 head entity 의 k-hop 이웃 노드 에 존재하는 candidate tail entity 에 대하여 더 높은 점수를 부여하도록 한다.
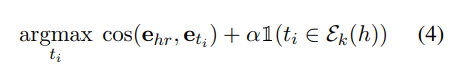
2-4. Training and Inference
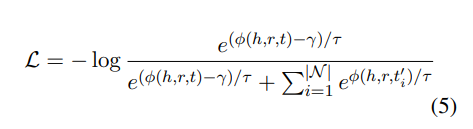
Loss function으로 contrastive learning에 많이 사용되는 InfoNCE loss에 additive margin 를 함께 사용하는 loss를 사용한다. >0 은 모델이 correct tiple에 대해서는 높은 점수를 부여할 수 있도록 유도하는 역할을 한다. 는 앞서 정의한 score function이다(equation 1).
는 negatives의 상대적인 중요도를 조정하는 역할을 한다. 가 작을수록hard negatives를 더 강조하게 된다.
( ?? : To avoid tuning as a hyper parameter, we re-parameterize as a learnable parameter.)
3. Experiments
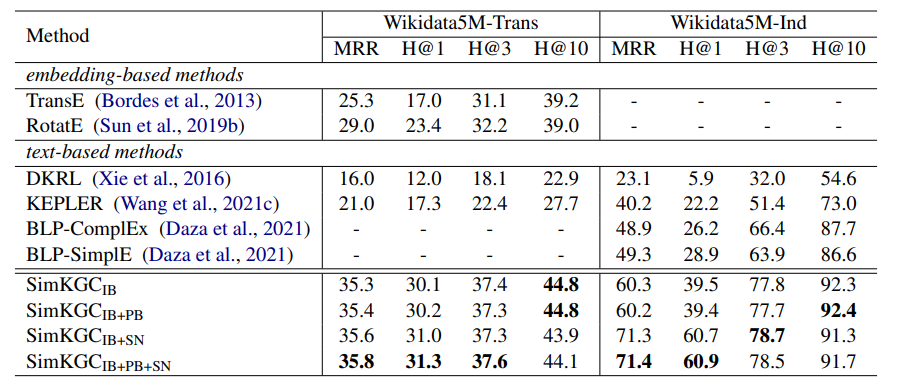
Transductive setting : all entities in the test set also appear in the training set
Inductive setting : no entity overap between train and test set
All metrics are computed by averaging over two directions: head entity prediction and tail entity prediction.
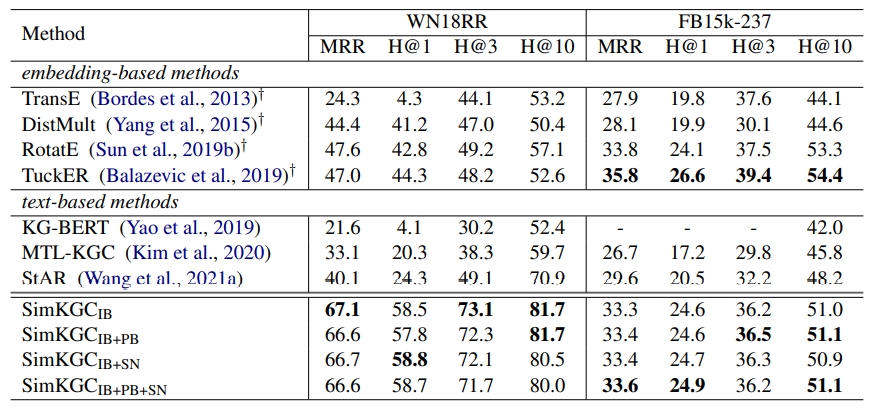
FB15k-237 dataset의 경우 embedding-based method가 더 좋은 성능을 보이고 있다. 이 데이터셋의 경우 훨씬 밀집된 그래프이기 때문에 의미적 연관성보다 일반화된 추론 능력이 모델에 더 필요하다고 설명하고 있다.
future work : ensemble embedding based method with text-based methods
Inference time의 경우 Wikidata5M-Trans dataset에서는 SimKGC가 ~4.6 million ebeddings을 계산하는데 ~40분이 걸렸다고 한다. KG-BERT가 같은 조건에서 3000시간이 걸렸던 것과 비교하면 훨씬 단축된 결과다. (추론 시간을 획기적으로 줄인 첫 논문은 아니지만 의의 있음. ex.ConvE,StAR)
-
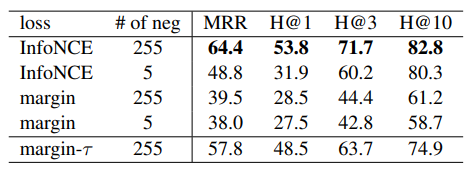
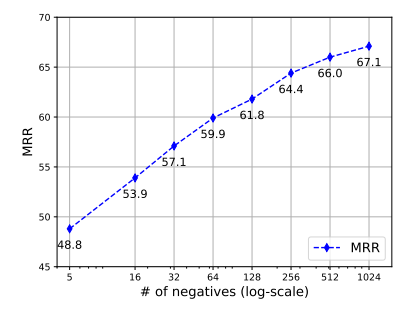
Analysis of loss fuction and the number of negatives on the WN18RR dataset.
-
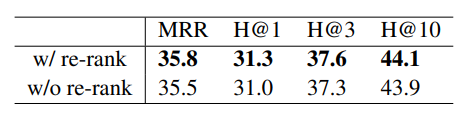
Ablation of re-ranking on the Wikidata5M-Trans dataset
-
MRR for different kinds of relations on the Wikidata5M with
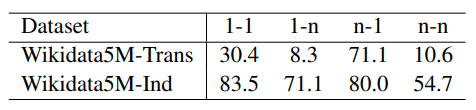

above table, the second example helps explain the low performance of "1-n" relations.
- Human evaluation
MRR같은 metric으로 평가를 진행할 시 위와 같은 이유로 성능이 낮게 측정되는 문제가 발생할 수 있다. 따라서 본 논문에서는 human evaluation을 추가로 실행하였다. 100개의 랜덤하게 선택된 잘못된 prediction에 대하여 사람이 평가를 진행한 결과다.
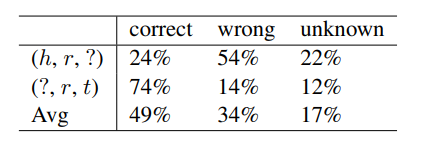
49%의 wrong prediction에 대해서 사람은 올바른 정답이라고 평가했음을 확인할 수 있다.
-> How to accurately measure the performance of KGC is also an interesting future research direction.
- Entity visualization
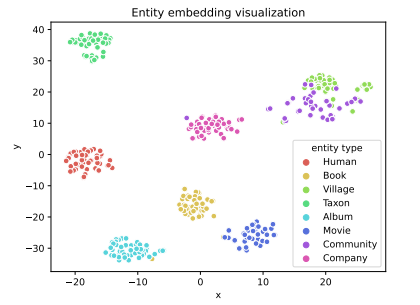
visualize the entity embedding from 9 largest categories with 50 randomly selected entities per category. different catetories are well separated. Surprisingly, two categoris "Community" and "Village" have some overlap.
4. Conclusion
- Knowledge graph completion에 Contrastive learning을 적용하였다.
- Bi-encoder 구조와 3 types of negatives를 사용하여 모델의 효율성을 향상시켰다.
- SOTA기록.
