[논문 리뷰] HittER: Hierarchical Transformers for Knowledge Graph Embeddings (EMNLP, 2021)
논문 리뷰
1. Introduction
Knowledge Graph
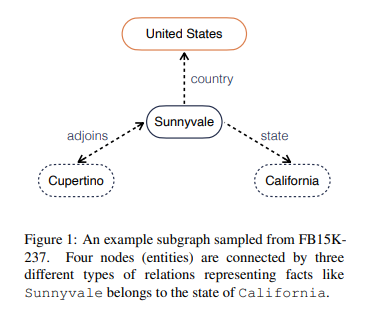
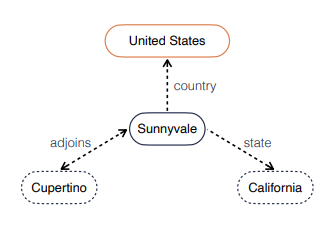
Knowledge Graph(지식 그래프)에서는 위의 그림과 같이 Entity(ex.Sunnyvale)와 Relation(ex.country)로 이루어져 있다. 지식 그래프는 subject entity(=head entity), predicate(=relation), object entity(=tail entity)의 관계로 표현할 수 있다.
= {()}
보통 지식그래프는 subject entity 혹은 object entity가 무엇인지 모르는 불완전한 형태이며 이것을 예측하는 작업을 Link prediction이라 한다.
Link Prediction
Link prediction은 본질적으로 Knowledge Graph completion이다. link prediction을 통해 그래프의 representations을 얼마나 잘 학습했는지 평가할 수 있다.
기존의 Link prediction 의 방식은 크게 두 분류로 나눌 수 있다. 하나는 entity와 relation을 vector space로 맵핑하여 벡터공간의 기하학적 성질을 이용하여 예측을 진행하는 Translational based 방식이다(ex. TransE,TransR,...).
그러나 이 방식은 몇가지 단점이 존재한다. 위의 지식 그래프를 예로 들어보면, incomplete triplet <Sunnyvale, county, ?>에서 missing object를 추론해야 한다고 생각해보자. 위의 방식은 오직 Sunnyvale과 county라는 정보만 사용해서 missing object를 추론하지만 이웃 노드들의 정보를 활용하면 훨씬 수월하고 정확한 추론이 가능할 것이다. (i.e.,<Sunnyvale, state, California>)
따라서 entity의 관계적 맥락 정보를 사용할 수 있는 또 다른 link prediction 방식이 제안되었다. Graph Neural Network 혹은 attention-based 접근법을 사용하는 것이다. 그러나 이 방식을 사용한 기존의 연구들은 Oversmoothing problem으로 인한 모델의 Depth가 제한된다는 문제점이 존재했다.
2. Problem & Task
어떻게 하면 그래프의 이웃 노드들의 정보를 사용할 수 있는 깊이있는 모델을 만들 수 있을까?
Task : link prediction
Input : () or (), , ,
approximates pointwise scoring function :
source entity(entity in the incomplete triplet) :
target entity(what we want to predict. it can be or ) :
3. Method
✨ HittER, a deep hierarchical Transformer model to representations of entities and relations in a knowledge graph jointly by aggregating information from graph neighborhoods.
HittER은 두 단계의 Transformer block으로 구성되어 있다.
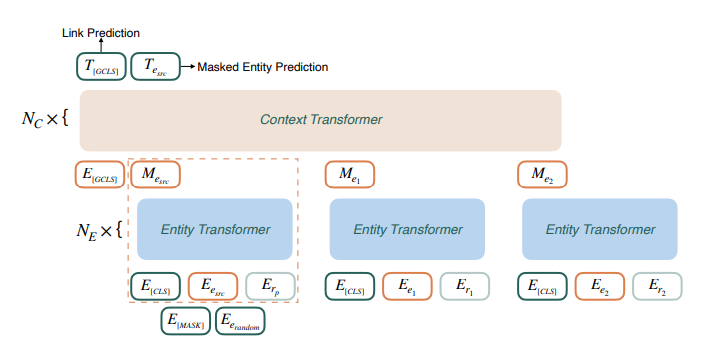
simple context-independent Transformer
위 그림에서 점선으로 된 박스 부분부터 살펴보자.
이 부분만 사용하여 link prediction을 진행할 수 있다. 모델에서는 Link prediction에 필요한 scoring function으로 Transformer의 encoder방식을 사용한다(multilayer and bidirectional encoder). , 그리고 스페셜 토큰인 [CLS] 토큰 임베딩을 각각 랜덤하게 초기화 한 후 3개의 임베딩을 직접 더한 것을 모델의 input으로 사용한다 (BERT와 유사한 방식). 그리고 [CLS] 토큰에 상응하는 Output embedding인 를 target entity를 predict하는데에 사용한다. 모델의 훈련 과정은 다음과 같다.
- true triplet(정답)의 target entity와 의 dot-product score를 구한다.
- 같은 방식으로 다른 모든 후보 entity들의 score를 계산하고 softmax function을 거쳐 normalize한다.
- 을 사용하여 모델을 훈련한다.
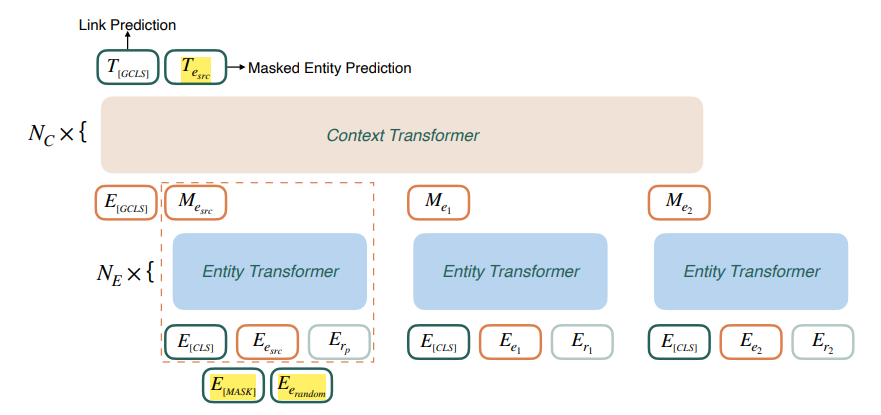
Bottom Block : entity Transformer
위의 단순한 link prediction에서는 그래프의 context 정보를 활용하지 않았다. 하나의 triplet만 사용하여 그래프의 임베딩을 학습하는 것은 그래프의 충분한 구조적 정보를 활용하지 않은 것이다. 이제 source entity의 neighborhood 정보를 활용해 보자.
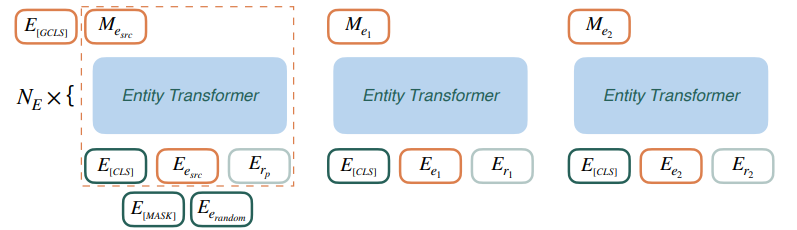
= {}
- incomplete triplet의 source entity 와 predicate 쌍을 모델의 첫번째 input으로 넣는다.
- 다음으로, source entity의 이웃 entity들과 둘을 잇는 edge를 relation으로 하여 모델의 input으로 넣는다.
✨ bottom block은 가능한 entity-relation쌍에서 모든 유용한 features들을 추출하여 vector로 representation하는 역할을 한다. entity-relation쌍을 직접 top block으로 전파시키지 않고 이 과정을 거치는 이유는 두개의 input을 하나로 변환함으로써 running time을 줄일 수 있기 때문이라고 한다.
Top Block : context Transformer
Top block에서는 bottom block에서의 output과 special [GCLS] embedding 의 정보를 aggregate한다.
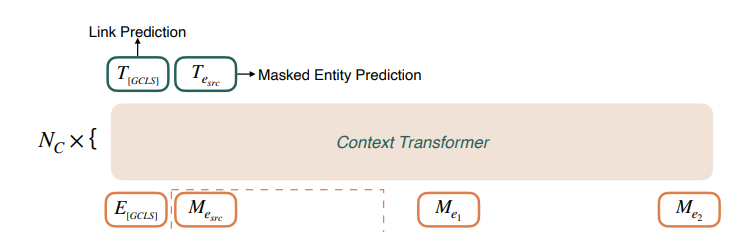
Input : 위의 과정과 유사하게 3가지 type의 embedding이 Top block의 input으로 들어가게 되는 것이다. [GCLS] token embeddings, intermediate source entity embedding(=), other intermediate neighbor entity embeddings(=, ).
loss :
Balanced Contextualization : Masked entity prediction
때때로, context information을 model에 주는 것은 다음과 같은 문제를 발생시키기도 한다.
- source entity가 link prediction을 하기에 충분한 정보를 갖고 있어서 추가적인 context 정보가 noise로 작용하는 경우.
- 많은 context 정보가 source entity로부터 온 정보를 downgrade시키거나 쓸데없는 상관관계 정보를 포함하여 overfitting이 발생하는 경우.
따라서 contextual information 과 source entity information 이 균형을 이루어야 한다. 이를 위한 해결책으로 논문에서는 BERT의 Maked language modeling에서 영감을 받아 두 단계의 Masked entity prediction task(MEP)를 제안하고 있다.
First step
첫 번째 문제를 해결하기 위해 모델을 훈련하는 동안 certain probability로 input source entity를 [MASK] token으로 바꾸거나, 랜덤하게 선택된 entity로 바꾸거나, 바꾸지 않고 그대로 둔다. 'certain probability'는 dataset 마다 특화된 hyperparameter이다. 이 과정을 통하여 모델이 contextual representations을 학습할 수 있다.
Second step
두 번째 문제를 해결하기 위해서는 모델이 혼동을 일으키는 entity를 발견하도록 훈련시켜야 한다. 이를 위해 source entity에 상응하는 output embedding, 에 하나의 classification layer를 두어 correct source entity인지 predict하도록 한다.
라는 추가적인 Cross-entropy classification loss term을 에 더하여 사용한다.
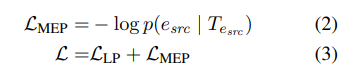
first step은 항상 beneficial하다. 그러나 second step은 source entity의 정보를 강조해야할 때는 필요하지만, 높은 질의 contextual information이 있을 때에는 불필요하다. 따라서 dataset 마다 다른 전략을 취해야 한다.
MEP task와 더불어 논문에서는 두 가지 추가적인 전략을 제안한다.
- uniform neighborhood sampling strategy
- remove the ground truth target entity from the source entity's neighborhood during training.
4. Experiments
Link prediction experiments
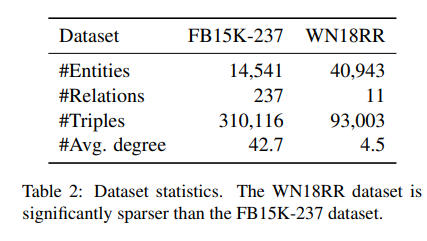
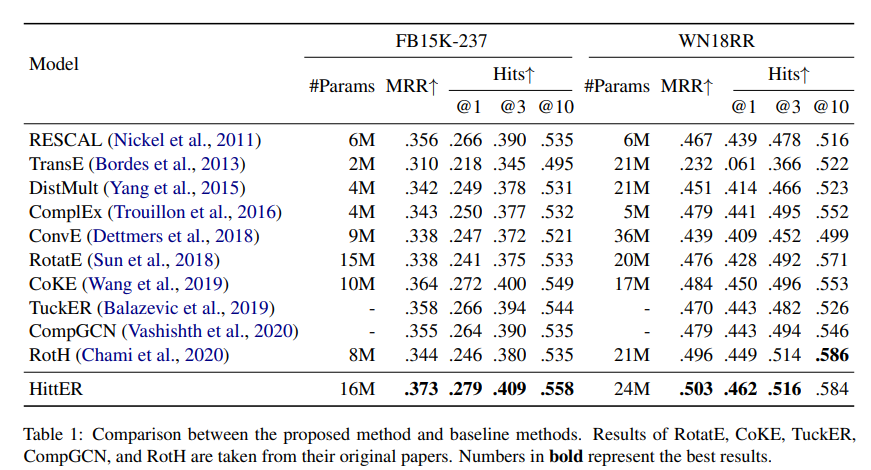
FB15K-237과 WN18RR의 두 가지 dataset에 대한 link prediction 실험 결과이다. 실험에 사용한 HittER은 3 layers entity transformer 와 6 layers context transformer 로 구성되어 있다. 균등하게 샘플링된 neighbor entities의 maximum number는 dataset 각각 50개, 12개이다. 평가 지표로 MRR과 Hits@k를 사용하였다. 실험 결과는 HittER이 가장 좋은 성능을 보이고 있다.
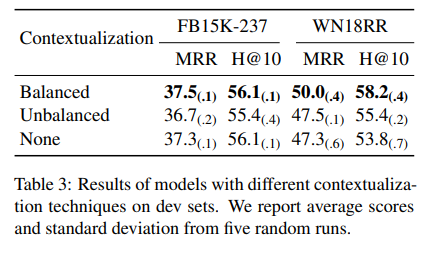
Ablation study로 contextual information과 Balancing techniques 모두 사용하지 않은 경우와(None), contextual information은 사용하였으나 Balancing technique은 사용하지 않은 경우(Unbalanced) 그리고 두가지 다 사용한 경우(Balanced)를 비교한 실험을 진행하였고, 실험 결과 두가지 모두 사용한 경우의 결과가 가장 좋았다.
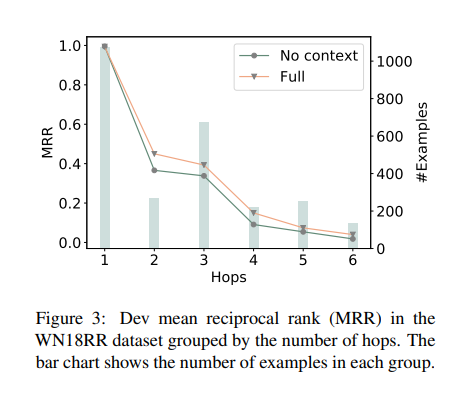
다음으로, WN18RR dataset에 대하여 hop 수에 따른 group을 분류하여 모델을 훈련시킨 후 link prediction에 대한 MRR을 측정한 결과이다. 실험 결과, 더 긴 Graph Path를 가질 수록 정보를 aggregate하는 것은 어려우며 MRR이 HOP수가 증가함에 따라 감소하는 것으로 보아 path가 길다고 해서 더 의미있는 정보를 갖는것은 아닌 것으로 보인다.
Factoid QA Experiments
논문에서는 Factoid Question Answering (QA) Task에서 BERT와 같은 사전 학습된 트랜스포머 기반 언어 모델에 HittER을 더하여 사용했을 때의 모델의 성능을 실험하였다.
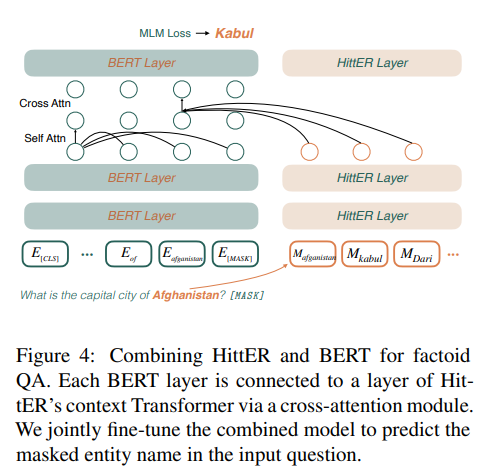
BERT의 각 레이에서 기존의 Self-attention module 이후에 'cross attention module'을 추가하였다. cross attention에서 Query는 BERT의 이전 레이어에서 온 값을 사용하고, KEY와 VALUE는 HittER layer의 output을 사용한다.
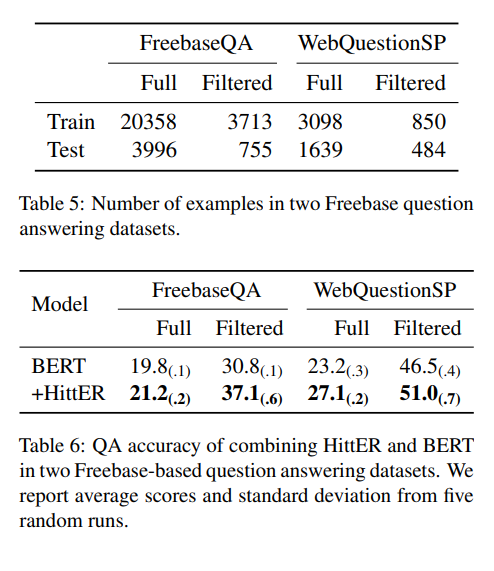
두 가지 QA datasets에 대하여 실험을 진행하였다. HittER의 INPUT으로 사용하기 위해 두 데이터셋에 있는 각각의 질문은 context entity와 inferred relation(between context entity and answer entity)으로 라벨링되었다.
FB15K-237 DATASET을 사전 학습한 HittER모델을 사용하였는데, QA datasets에 있는 대부분의 질문들이 FB15K-237의 knowledge와 관련이 없다. 따라서 논문에서는 context 와 answer entity가 FB15K-237과 QA datasets 모두에 존재하는 filtered setting 에서의 실험을 추가로 진행하였다.
실험 결과는 BERT만 사용했을 때 보다 HittER을 함께 사용했을 때 QA accuracy가 더 좋게 나오고 있다.
5. Contribution
- multi-relational knowledge graph에 Transformer를 적용한 모델을 제안하였다.
- QA task에서 BERT에 knowledge representation을 사용하는 새로운 방식을 제안하였다.
