📃 paper : https://arxiv.org/pdf/2009.14794.pdf
Introduction
Original transformer model은 뛰어난 성능을 자랑하지만 quadratic한 space and time complexity를 수반하여 long-sequence의 경우 그 연산량이 매우 방대하다는 단점이 존재했다. 이러한 문제점에 대하여 많은 연구들이 진행되어왔다. ex) sparse attention. 그러나 기존의 방법론은 이론적인 보장이 제공되지 않았다는 문제점이 존재했다.
✨ 본 논문에서는 기존의 full-rank attention 방식을 완벽하게 대체할 수 있는 linear time and space complexity가 소요되는 획기적으로 효율적이면서 이론적으로도 증명이 가능한 새로운 Fast Attention via positive Orthogonal Random feature approach (FAVOR+)를 제안한다.
Method
Generalized Kernelizable Attention
what is kernel? : https://medium.com/@zxr.nju/what-is-the-kernel-trick-why-is-it-important-98a98db0961d
트랜스포머에서는 query-key product 결과물이 nonlinear한 softmax operation을 통과하는 과정을 거쳐 토큰 간 similarity를 계산한다. softmax를 통과하고 나면 원래의 query, key 요소들로 다시 분해하는 것은 불가능하다. 그러나 attention matrix를 original queries, keys에 대한 random nonlinear functions의 product로 분해하는 것은 가능하다. 이를 'random feature'라 하고 이 방식을 통해 similarity를 좀 더 효율적으로 인코딩할 수 있다.
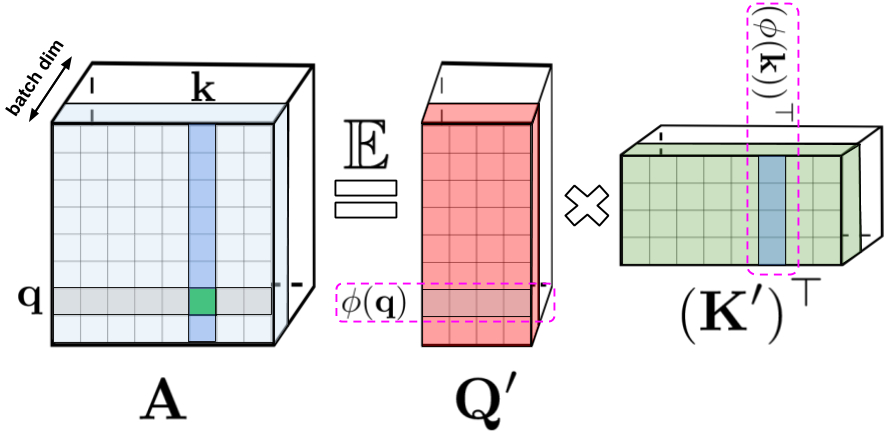
은 input sequence의 토큰 사이즈라 정의하면 기존의 트랜스포머에서는 Q,K,V 이고, 쿼리와 키의 dot product attention을 통해 얻은 attention matrix A는 A 이다. 그러나 이 과정을 kernel method를 사용하면 Q',K' 에 대한 dot-product로 attention matrix 계산이 가능하다.

random feature map : 를 통하여 각각 query와 key의 row vector를 d->r차원으로 mapping한다. 그리고 mapping된 와 를 inner product하여 attention계산을 수행한다. 저자들은 이러한 어텐션 계산을 'Generalized attention'이라고 이름 붙였다.
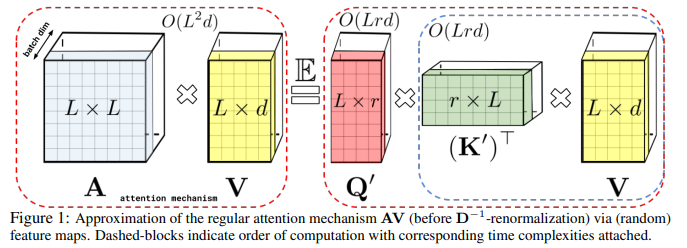
위에서 설명한 decomposition 방식을 사용하면, 기존의 matrix연산 과정을 재배열 하여 계산할 수 있다. key와 value를 먼저 곱한 후 query를 곱하는 것이다. 이경우 기존에 attention matrix가 quadratic한 memory complexity가 필요했던 것과 비교했을 때 훨씬 효율적인 linear memory complexity가 든다.
(위의 그림의 경우는 bidirectional attention에 대한 경우이다. (past와 futre를 구분하지 않는) )

논문에서는 random feature map으로 trigonometric function (sin, cos)을 사용하는 것은 negative dimension values를 가질 수 있고 unstable한 방식이라고 설명하고 있다. 따라서 Positive random features를 사용하는 것이 좋다고 설명하며, 이론적으로 증명이 가능한 Positive random features (i.e. positive-valued nonlinear functions of the original queries and keys)를 제시한다. 이 방식을 통해 훈련 과정에서의 불안정성을 피할 수 있고 기존의 softmax attention 방식에 더 정확하게 근사할 수 있다고 한다.
덧붙여, Orthogonal random features를 사용하는 것이 좋다고 논문에서는 이야기 하고 있다. 서로 다른 random sample 은 orthogonal되어야 variance를 더 줄일 수 있다고 설명하고 있다. (<-> iid)
(증명 과정 생략..)
Experiments
본 논문에서 제시한 모델인 Performer는 attention 방식만 본 논문에서 제안한 방식으로 대체하고 이외의 다른 부분들은 regular transformer 방식을 따랐다고 한다. 그리고 두 가지 setting상황을 구분하였는데 하나는 undirectional/causal modelling (U) 이고 다른 하나는 bidirectional/masked language modelling (B) 이다.
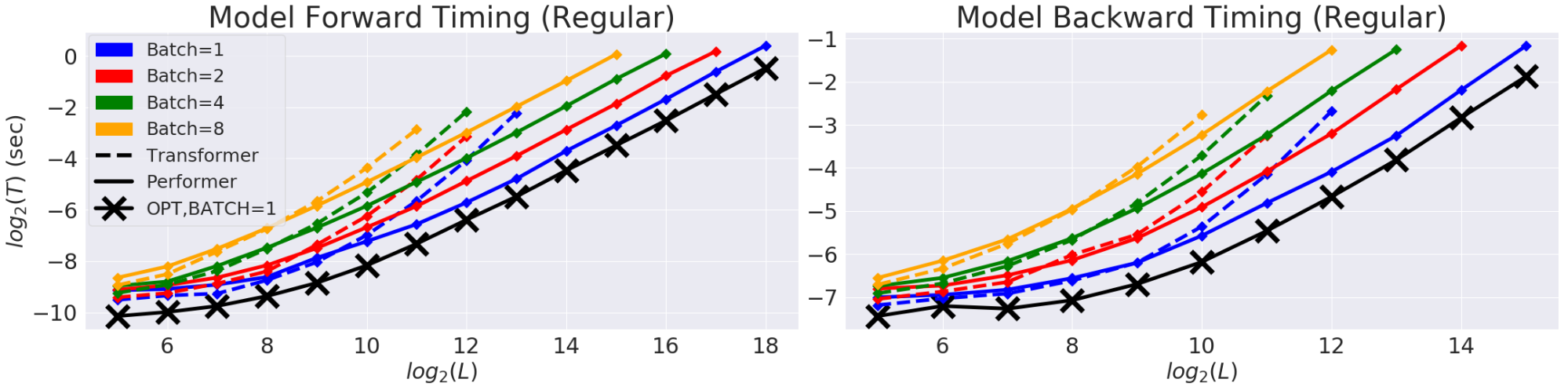
먼저 B setting에서 transformer와 performer의 forward와 backward pass speed 를 비교한 실험 결과다.
검은색 (x) 선은 모델의 maximum possible efficiency를 계산한 결과다. performer는 거의 이 optimal performance에 도달하고 있음을 확인할 수 있다.
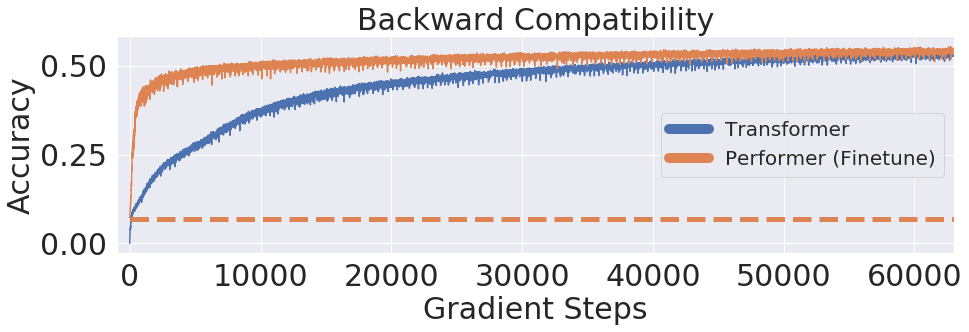
그 다음으로 performer가 약간의 finetuning을 거친 사전 학습된 트랜스포머와 하휘호환이 가능한지 그 여부를 실험해보았다. 기존 사전 학습된 트랜스포머의 weight을 performer에 전이하여 학습을 수행하였고, 높은 accuracy를 보이며 하휘호환이 가능하다는 사실을 알 수 있다.
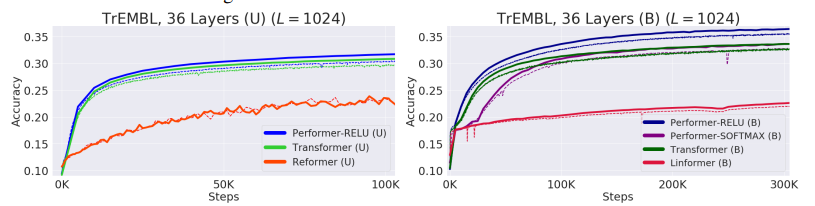
다음으로는 protein dataset에 대한 다른 모델과의 비교 실험 결과다. large ublabeled corpora of protein sequences에 대하여 prediction accuracy를 측정한 실험이다. 두 가지 setting 상황 모두에서 performer가 가장 높은 accuracy를 보이고 있음을 확인할 수 있다.
Contribution
- sparsify나 low-rankness같은 성질에 의존하지 않고 time, space complexity를 획기적으로 줄일 수 있는 방법을 제안하였다.
- 이론적으로 증명이 가능한 방식을 제안하였다.
