[논문 리뷰] Relphormer : Relational Graph Transformer for Knowledge Graph Representation (arXiv, 2022)
논문 리뷰
1. Introduction
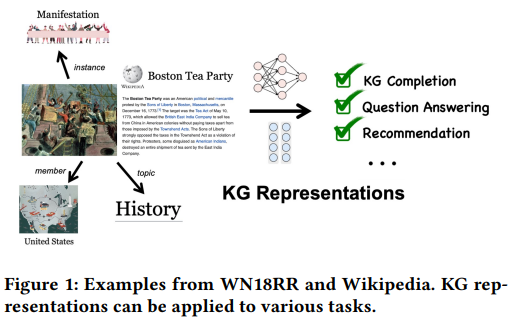
pure graph 와 다르게 knowledge graph(KG)는 여러개의 노드 타입으로 구성된 Heterogeneous graph 이다. 따라서 Transformer architecture가 KG modeling에 적합한지 여부는 아직 풀리지 않은 문제다. 구체적으로, Transformer architecture를 그대로 KG에 적용하는 것에는 두 가지의 nontrivial challenges가 존재한다.
1. Heterogeneity for edges and nodes
KG는 여러 타입의 edge와 node가 존재한다. 그리고 각각의 노드는 서로 다른 topological strucre와 textual descriptions을 갖는다. 그러나 vanilla KG Transformer architecture는 모든 entity와 relation을 plain token으로 간주하기 때문에 노드의 구조적 정보는 놓치게 된다.
2. Task Optimization Universality
knowledge embedding을 학습시키기 위해 사전에 정의된 scoring function을 사용하는 기존의 방식은 entity/relation prediction에 서로 다른 optimizing object를 사용해야 했다. 또한 기존의 KG representation learning methods들은 다양한 KG-based tasks에 대하여 통일된 representations을 제시하지 못하였다.
2. Problem
- How to treat the heterogeneity for edges and nodes?
- How can we provide unified knowledge graph representation learning?
저자들은 이 두가지 문제에 대한 해답으로 Relational Graph Transformer (Relphormer)를 제안한다.
3. Method
0. Preliminaries
-relational graph
-node set
-the goal of knowledge graph completion : are the label sets of the trple
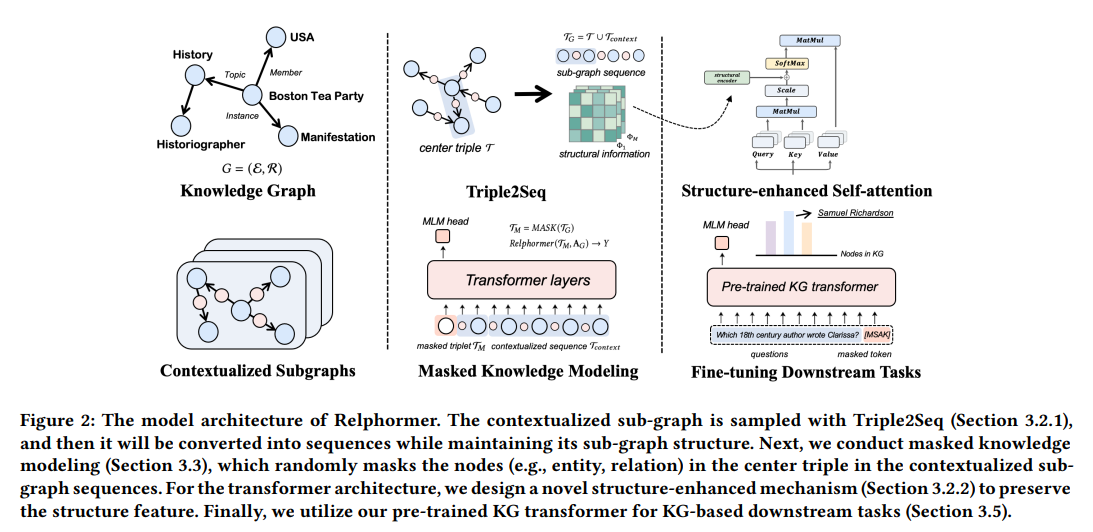
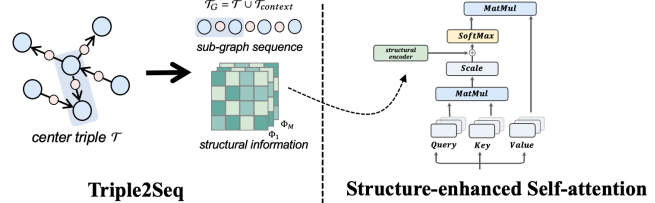
1. Triple2Seq
To solve heterogeneity of edges: use Triple2Seq
모델의 input sequence로 'contextualized sub-graphs'를 사용하는 방식이다. contextualized sub graphs 는 다음과 같이 정의된다.

center triplet 와 의 이웃 노드 집합 로 이루어져 있다. 는 다음과 같이 정의된다.
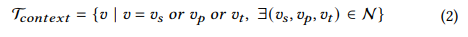
: fixed-size neighborhood triple set of the triple
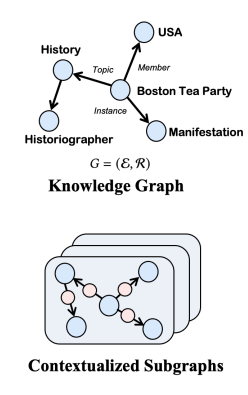
Triple2Seq에서는 edges(relations)를 일반적인 노드처럼 여기며, 이렇게 형성된 local structural information을 갖는 contextualized sub graphs를 모델의 input으로 넣어준다.
추가로, local structural feature를 더 잘 포착하기 위하여 모델 훈련 동안 dynamic sampling strategy를 사용한다. 각 에폭마다 동일한 center triple에 대하여 여러개의 contextualized sub graphs를 랜덤하게 선택하여 사용한다.
2. Structure-enhanced Self-attention
2.1) global node
선행 연구인 HittER을 통해서 entity-relation 쌍의 정보가 KG에 있어서 중요하다는 것을 알 수 있었다. Triple2Seq를 통해서는 entity-realtion 쌍의 정보를 얻을 수 있고, 뿐만 아니라 entity-entity, relation-relation쌍의 정보를 얻을 수 있다. KG에서 realtion은 entity보다 그 수가 훨씬 작기 때문에 relation을 통하여 contextualized subgraphs 사이의 globally semantic information을 유지할 수 있다.
추가로 논문에서는 global information을 보존하기 위해 [CLS] token과 비슷한 역할을 하는 global node를 input sequence에 추가하여 사용하였다. 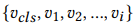
2.2) structure enhabced self attention
다음으로 attention에 대한 부분이다. fully-connected attention을 진행하면 sequenntial input의 구조적 정보가 손실될 수 있기 때문에, 논문에서는 attention bias를 추가로 사용하는 방식을 제안하였다. attention bias를 통해 노드쌍 사이의 구조적 정보를 포착할 수 있다고 한다.
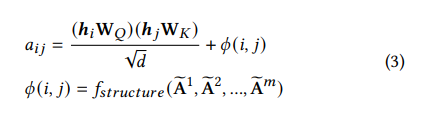
: attention bias between node and node
: normalized adjacency matrix
: linear layer
: hyperparameter
: reachable relevance by taking m steps from one node to the other node
2.3) contrastive learning strategy
모델 훈련동안 하나의 center triple에 대하여 너무 많은 sub-graphs를 사용하면 inconsistency(비일관성, 모순성)을 일으킬 수 있다. 따라서 불안정성 문제를 해결하기 위해 논문에서는 dynamic sampling을 하는 동안 contextual contrastive strategy를 사용하였다.

contextual loss 를 사용하는 것이다.
input sequence를 인코딩하고난 후 hidden vector 를 current epoch t에서의 contextual representation 로 취한다. 이 loss term의 목표는 서로 다른 sub-graphs들 사이의 차이를 최소화 하는 것이다.
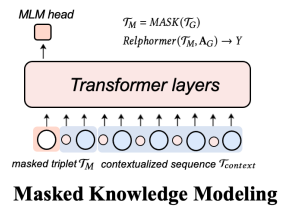
3. Maked Knowledge Modeling
score function을 대체할 수 있는, 통일된 KG representation learning 방식으로 논문에서는 Masked Knowledge Modeling을 제안한다.
input 에서, Center triple을 랜덤하게 마스킹한다. link prediction 문제에서는 혹은 로, relation prediction task에서는 으로 마스킹된다.
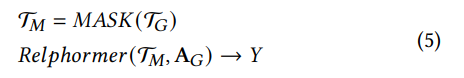
sequence에서 오직 하나의 토큰만 랜덤하게 마스킹된다. 마스킹을 한 후 head와 tail entity의 이웃노드들을 동시에 sampling하면 label leakgage 문제가 발생할 수 있다. 따라서 훈련동안, 예측하고자 하는 entity의 context nodes를 제거한다.
추가로, 각각의 downstream tasks에 대하여 masking을 다르게 진행한다고 한다. 예를들어 QA의 경우 정답 entity를 예측하기 위하여 [question tokens; [MASK]] 의 방식으로 masking을 진행하였다고 한다.
4. Optimization and Inference
모델 훈련 기간에는 masked knowledge loss와 contrastive learning objects를 같이 사용한다.
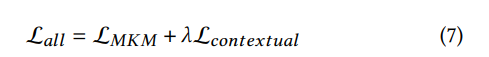
추론 기간 동안에는 multi-sampling strategy를 사용한다.

: predicted result of one contextualized sub-graph
: the number of sampled sub-graphs
structure enhanced mechanism, and heterogeneity for nodes : novel extension of self attention mechanism
for unified kg representation learning : use masked knowledge modeling
and introduce a unified optimization object for predicting masked entities as well as relation tokens
4. Experiments
1. Entity prediction
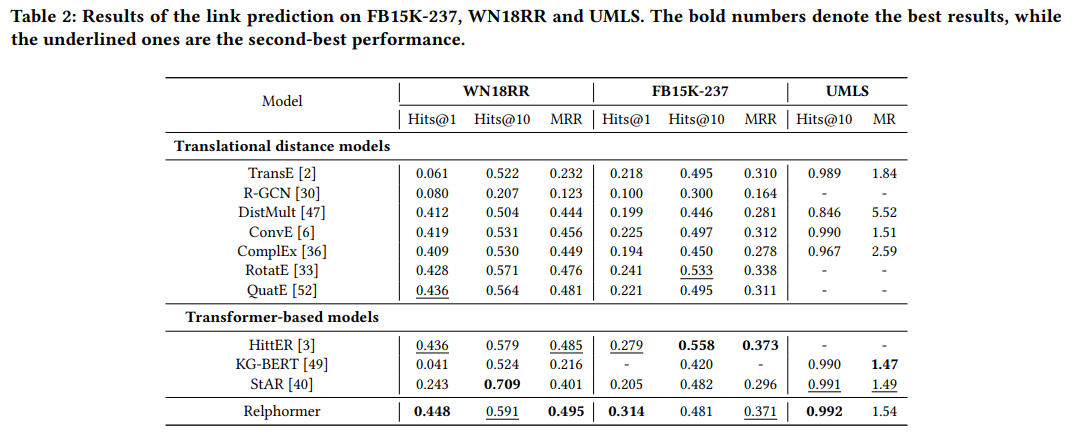
WN18RR dataset에서는 Relphormer가 다른 transformer-based models보다 앞서는 성능을 보이고 있다. 그러나 FB15K-237에서는 HittER가 더 앞서는 결과를 보이고 있다.
2. Relation Prediction
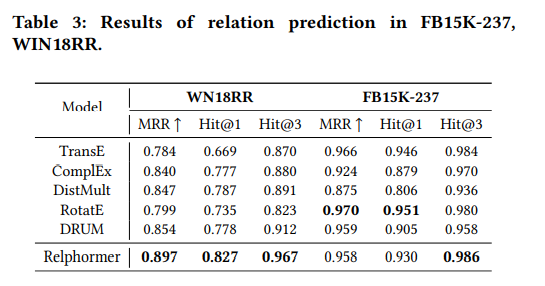
마찬가지로 Relation Presiction에서도 WN18RR에서는 Relphormer가 가장 좋은 성능을 보이고 있다. 그러나 FB15K-237에서의 결과는 Hit@3의 경우에는 Relphormer가 좋은 성능을 보이고 있지만 MRR, Hit@1에서는 RotatE가 더 좋은 성능을 보이고 있다.
3. Question Answering
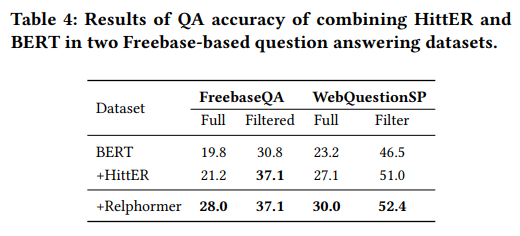
4. Recommendation
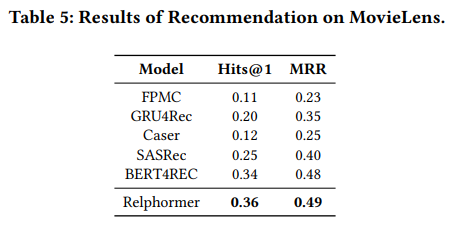
5. Ablation study : The number of sampled contextualized sub-graph triple
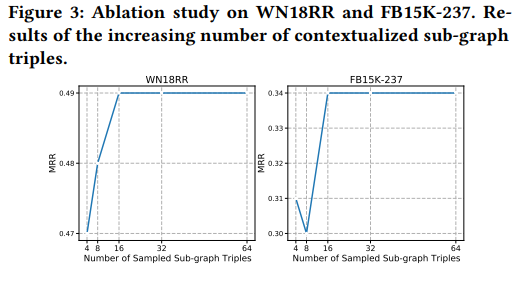
triples의 수를 4부터 64까지 늘려가며 entity prediction에 대한 실험을 진행한 결과다. 두 데이터셋 모두에서 subgraph의 크기를 키울 수록 성능이 급격하게 좋아지고 있음을 확인할 수 있다. 그러나 수가 너무 커지면, 더이상 성능이 증가하지 않는 것을 확인할 수 있다.
6. Ablation study : structure-enhanced self attention, optimization object, Global node
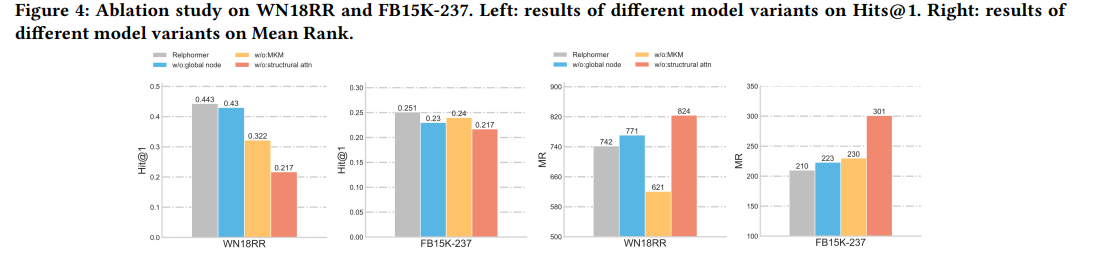
7. Inference speed comparison