📃 paper: https://arxiv.org/pdf/1810.05270.pdf
(✨ 기존의 network pruning 방식에 의문을 제기하면서 다양한 pruning기법들을 소개하고 비교하기 때문에, 어떠한 network pruning 방식들이 연구되어왔는지 개괄적으로 살펴보기에 좋은 논문인 것 같다.)
1. Introduction
over-parameterization은 딥 뉴럴 네트워크의 널리 알려진 특성이다. 이러한 특성은 많은 연산량과 메모리를 필요로 한다. 따라서 한정된 컴퓨터 자원에서 딥 뉴럴 네트워크를 사용하기 위해 'nework pruning'기법이 널리 연구되어 왔다. network pruning의 절차는 보통 다음의 3 단계를 따른다.
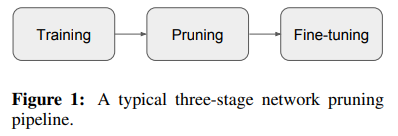
- Train a large, over-parameterized model
- Prune the trained large model according to a certain criterion
- fine-tune the pruned model to regain the lost performance
이러한 pruning 절차에는 두 가지 가정이 숨어있다.
첫째, 거대하고 과대 파라미터화 된 네트워크를 훈련시키는 것은 중요하다.
둘째, 최종적인 효율적인 모델을 얻는데에 있어서 pruned된 아키텍처와 이와 관련된 weight 모두 중요하다.
2. Problem
본 논문은 지금까지 널리 믿어져왔던 이 두가지 믿음에 대해 의문을 제기한다. 그리고 다음과 같은 주장을 한다. (experiments chapter에서 설명하겠지만 정확히 말하면, structured pruning 방법론에 해당하는 주장이다.)
- 효율적인 final model을 얻기 위해서 거대하고 과대 파라미터화 된 네트워크가 필수적인 것은 아니다.
- 거대한 모델로부터 중요한 weight를 학습하는 것은 대체적으로 small pruned model에 있어서 유용하지 않다.
- 거대 모델로부터 물려 받은 weight보다 pruned architecture의 구조 차제가 더 중요하다.
최종적으로 랜덤하게 초기화된 weight들로 training하는 것이 pruned model을 fine tuning 하는 것과 동등하거나 더 좋은 성능을 보인다고 설명한다.
3. Background
Structured vs Unstructured pruning
pruning은 여러가지 방법론으로 분류가 될 수 있는데, 가장 주요한 분류 중 하나가 structured 와 unstructured pruning이다.
unstructured pruning은 특정한 기준으로 weight를 pruning하는 방법이다. Dropout, -norm regularization과 같은 방법이 이에 해당된다. Structured pruning의 경우 channel이나 layer의 수준에서 pruning이 진행되는 방법론이다.
Unstructured(weight) pruning의 경우 압축 비율이 높기 때문에 일반적으로 structured 방법보다 더 많은 가중치들이 제거될 수 있다. 하지만 pruning 결과가 sparse matrix로 표현되기 때문에 많은 하드웨어 자원이 필요하다는 단점이 있다.
Predifined vs Automatic pruning
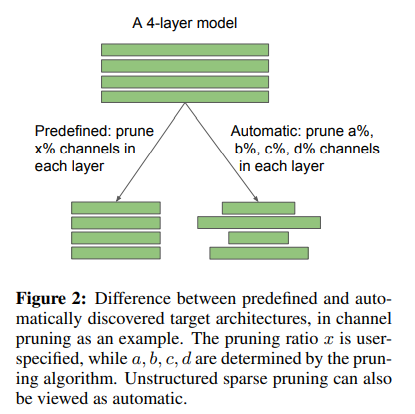
structured pruning의 Predifined pruning은 미리 정해둔 기준에 따라 channel을 pruning하는 방법이다. Automatic pruning은 학습 과정에서 알고리즘이 찾은 pruning 비율에 따라 pruning하는 방법이다.
Unstructured pruning(Weight pruning)의 경우는 pruning 될 weight의 비율을 훈련 과정을 통해 정하기 때문에 automatic pruning에 속한다.
4. Method
✨ methodology for training a small target model from scratch.
- Target Pruned Architecture
target pruned model의 구조가 predifined pruning을 따랐는지 automatic pruning을 따랐는지 두 가지 경우로 나누어 생각한다.
- datasets, network architectures and pruning methods
대표적인 predefined pruning, automatic pruning, 그리고 unstructured pruning 기법들을 선정하여 CIFAR-10, CIFAR-100,ImageNet에 대한 Image classification 실험을 수행하였다.
- Training Budget
small model 즉, pruning을 거친 모델을 처음부터 훈련시키는데 어느정도의 epoch동안 학습시켜야 하는가?가 주요 관건이다. 논문에서는 large model과 동일한 epoch을 학습시키는 것은 불공정하다고 본다. 따라서 large model과 small model 두 모델의 FLOPs을 계산하여 계산량이 동일하도록 small model의 epoch을 늘렸다. 그리고 이 경우를 'Scratch-B'라 부른다. 한편 large model과 동일한 epoch을 small model에 사용한 경우를 'Scratch-E'라 한다.
5. Experiments
1~3)은 각각의 pruning 방법론에 대하여 'training from scratch'와 'fine-tuning from inherited weights'를 비교한 실험이다.
1) Predefined structured pruning
- -norm based Filter pruning
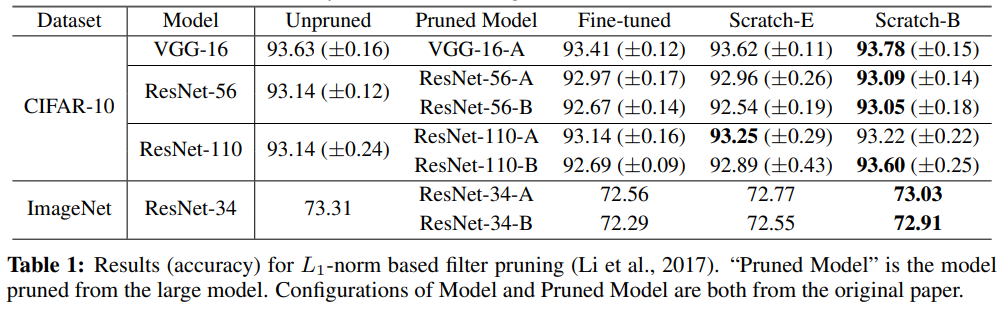
모델 학습 후 -norm 즉, 필터에 속한 가중치들의 절댓값의 합을 구하여 가장 작은 값을 갖는 필터부터 pruning하는 방법이다. 절댓값이 클 수록 더 중요한 필터라고 보는 것이다.
실험 결과 scratch-trained 모델이 fine-tuned model과 비슷하거나 더 좋은 accuracy를 보인다. scratch 모델 중에서는 대부분의 경우에서 수정된 epoch으로 학습한 Scatch-B가 조금 더 좋은 accuracy를 보인다.
-
ThiNet (Luo et al., 2017)
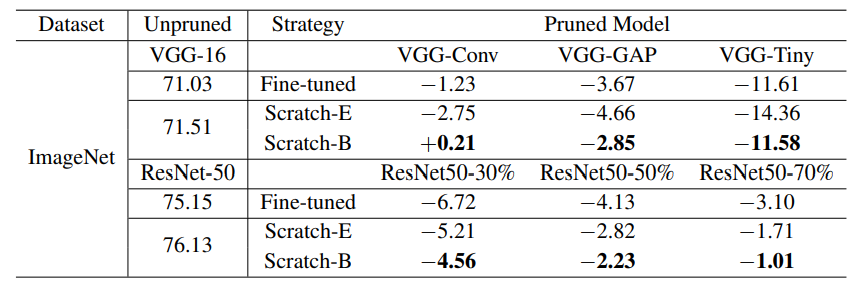
다음 레이어의 activation 값에 가장 작은 영향을 끼치는 channel을 greedy하게 pruning하는 방식이다. 비교 모델의 original paper에서의 accuracy에 대한 상대적인 accuracy drop으로 비교한 결과다. (VGG-16의 71.03은 해당 논문의 implementation을 따랐을 때의 accuracy이고 71.51은 이 논문의 implementation을 따랐을 때의 accuracy이다.) 대부분의 경우에서 scratch-B가 좋은 accuracy를 보이고 있다. 다만, VGG-Tiny에서 scratch-E를 적용했을 때 accuracy가 많이 떨어지는데 이 경우는 모델이 크게 pruned되기 때문에 training budget 측면에서 많은 손해를 봤기 때문이라고 논문에서 설명하고 있다. -
Regression based Feature Reconstruction
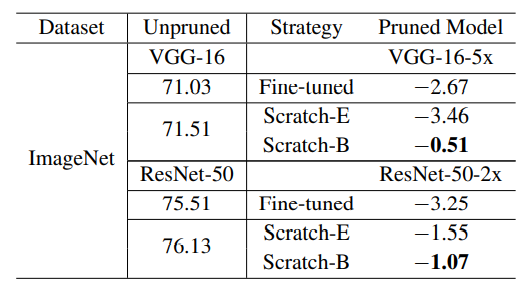
다음 레이어의 feature map reconstruction error를 최소화하도록 channel을 pruning하는 방법. 이 경우에도 Scratch-B가 더 좋은 accuracy를 보인다.
2) Automatic structured pruning
-
Network Slimming (Liu et al., 2017)
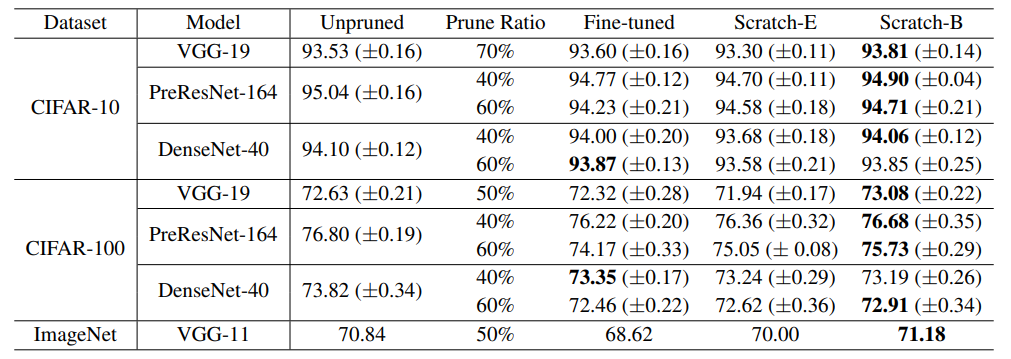
낮은 scailing factor를 갖는 channel을 pruning하는 방식이다. scailing factor는 모든 레이어에 걸쳐서 비교된 값이기 때문에 automatic한 pruning방식이라고 볼 수 있다. 이 경우에도 대부분의 모델에 대하여 Scratch-B가 fine-tuned한 경우와 비슷하거나 더 좋은 accuracy를 보이고 있다. -
Sparse Structure Selection (Huang & Wang, 2018)

Network slimming의 generalization한 방식이라고 볼 수 있다. scailing factor를 통해 structure를 pruning한다. channel외에도 residual blocks에 대하여 pruning을 진행할 수 있다. 위의 실험 결과는 residual block에 대한 pruning 결과다.
3) Unstructured Magnitude-Based pruning
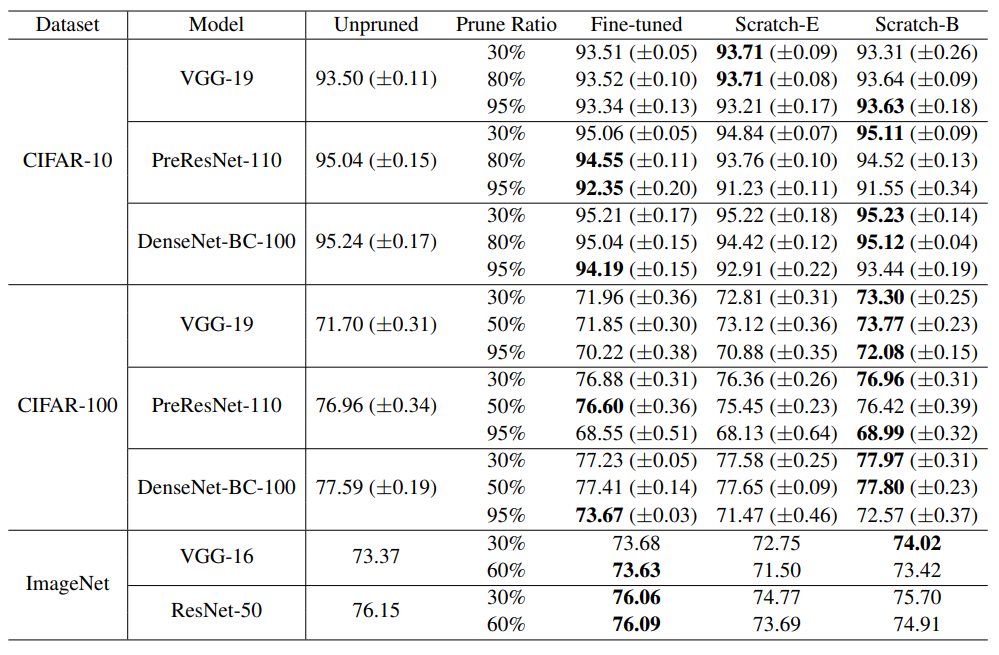
weight의 magnitude(절댓값)을 기준으로 작은 값을 pruning하는 방식이다. weight pruning의 경우 높은 비율로 pruning하는 것이 가능하다. 작은 dataset인 CIFAR-10의 경우 pruned ratio가 작을 때(<=80%) scratch를 사용하는 것이 더 좋지만, ratio가 크면 fine-tuning에서의 결과가 더 좋음을 확인할 수 있다. 더 큰 dataset인 ImageNet에서의 결과를 살펴보면 대부분의 경우에서 fine-tuning이 더 좋은 모습을 보이고 있다. 논문에서는 1) sparse networks(CIFAR)를 직접 학습시키는 것의 어려움, 2) Unstructured pruning은 structured pruning와 달리 pruning 후 weight distribution이 크게 바뀌기 때문일 것이라고 그 이유를 추측하고 있다.
4) Network pruning As Architecture Search
위의 실험 결과로부터 structured pruning의 경우, large model로부터 inherited 된 weight를 사용하는 것은 random한 weight를 사용하는 것보다 더 좋을 것이 없다는 것을 확인하였다. 이 챕터에서는, automatic pruning을 통한 architecture search와 predefined pruning(uniformly pruning)방식을 비교한다.
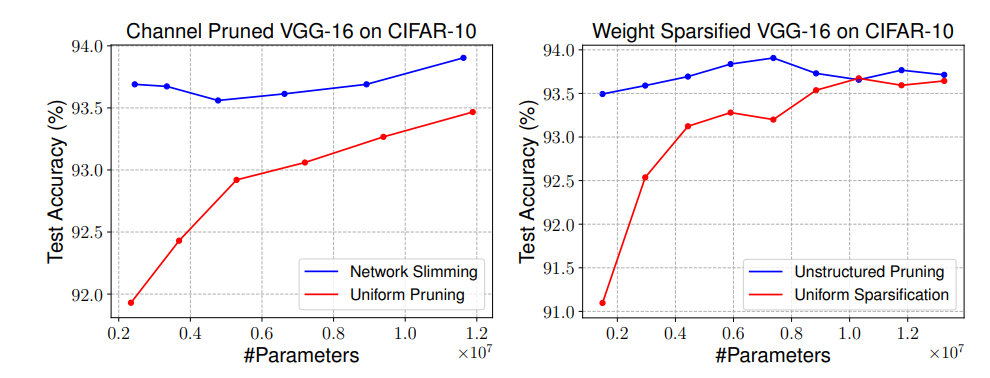
왼쪽의 그림은 automatic channel pruning method(Network slimming)와 각 레이어마다 같은 비율의 channel을 pruning한 predifined pruning method(Uniform pruning)의 parameter efficiency를 비교한 결과다. Network slimming의 경우가 훨씬 효율적임을 확인할 수 있다.
오른쪽의 그림은 Unstructured pruning method와 Uniform Sparsification method를 비교한 결과다. 이 경우에서도 unstructured pruning, 즉 automatic한 method를 사용했을 때의 parameter efficiency가 더 좋음을 확인할 수 있다.
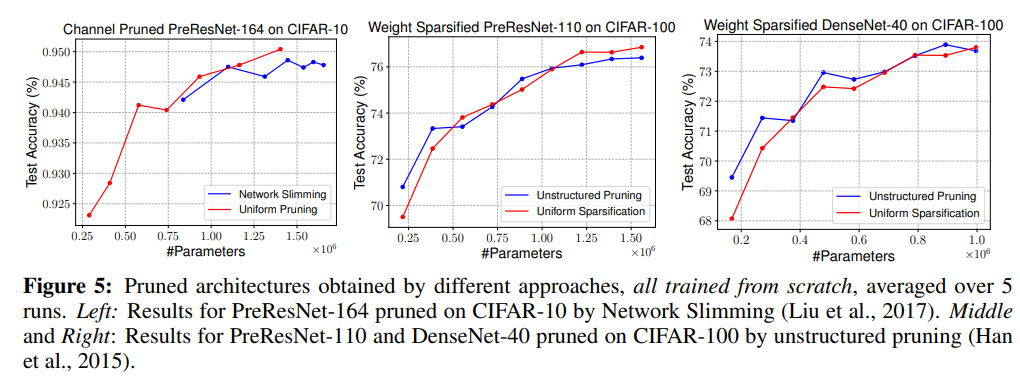
그러나 automatic pruning이 항상 좋은 효율성을 보이지는 않았다. 비교적 최근 아키텍쳐(ResNets, DenseNets)의 겨우에는 uniform pruning과 큰 차이를 보이지 않는다. 논문에서는 pruning 이후 남은 weight를 stage별로 살펴본 결과, 거의 uniform하게 pruning 하고 있음을 확인하였다고 한다. 즉, uniform pruning방식과 큰 차이가 없다는 것이다.
5) Experiments on The Lottery Ticket Hypothesis(Frankle & Carbin, 2019)
Lottery Ticket Hypothesis 논문은 큰 네트워크의 sub-network 중에서는 기존 네트워크와 비교했을 때 비슷하거나 더 성능이 좋은 sub-network, 즉 winning ticket이 존재하는데, 이는 large network의 initialization과 관련이 있다고 설명한다. network pruning과 가중치 초기화를 다루고 있다는 점에서 본 논문과 비슷한 점이 많은 논문이다. 그러나 세부적으로는 lottery ticket논문은 unstructured pruning방식에 대한 가정이다. 이 밖에도 본 논문과는 다른 몇 가지 가정들이 전제되어 있다. 이 챕터에서는 lottery ticket논문의 pruning 방식과 본 논문의 pruning 방식을 비교하는 실험을 진행하였다.
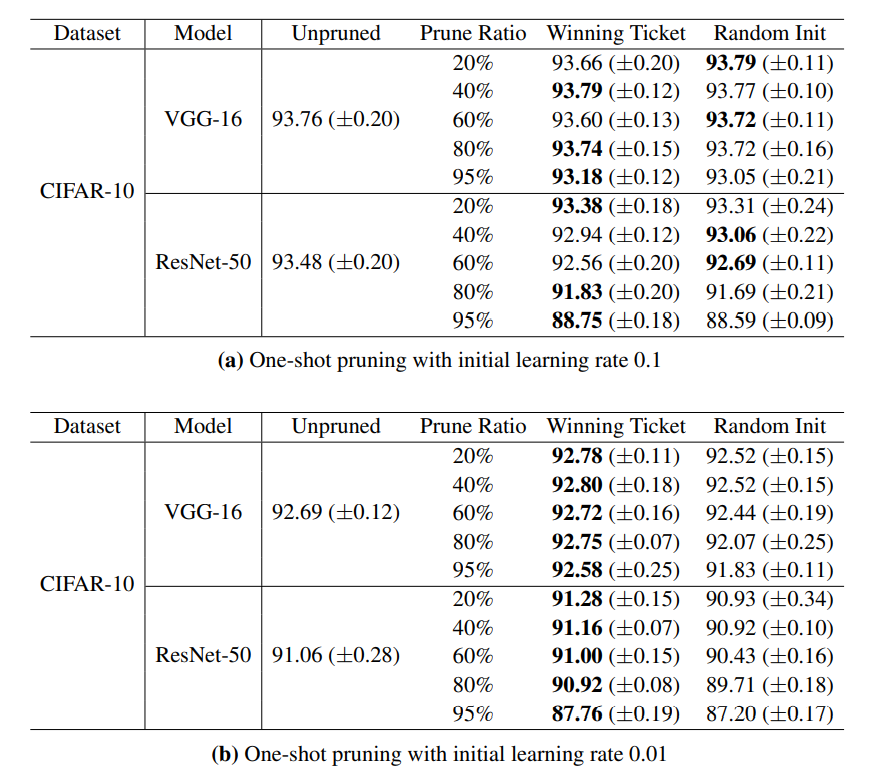
unstructured pruning 방식을 적용한 경우 lottery ticket hypothesis는 learning rate가 작을 때(=0.01) 좋은 성능을 보이고 있음을 확인할 수 있다.
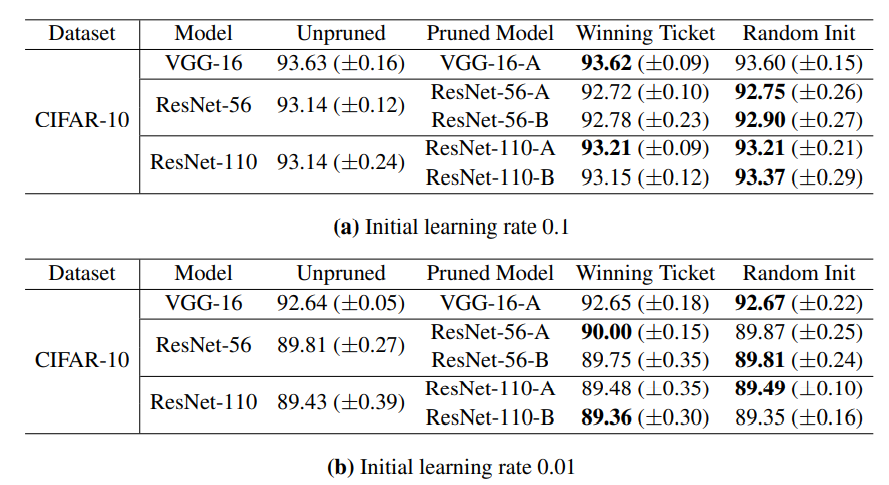
structured pruning 방식을 적용한 경우에는 learning rate에 상관없이 winning ticket과 random init이 비슷한 성능을 보이고 있다. (-norm based filter pruning 수행)
정리해보면, winning ticket의 경우 unstructured pruning 방식에서 learning rate가 작을 때에만 효과가 있음을 확인할 수 있다고 본 논문에서는 설명한다. 그 이유에 대해서 저자는 최종 학습된 모델의 가중치가 작은 learning rate 때문에 처음 가중치 값에서 크게 달라지지 않기 때문일 것이라고 추측하고 있다.
6. Contributions
-
기존에 통상적으로 사용되어 오던 pruning method에 대하여 의문을 제시하였고, pruning method에 대하여 좀 더 주의있게 접근해야한다는 점을 시사하였다.
-
다양한 pruning method에 대한 비교를 제시하였다.
