
What is Machine Learning ?
머신러닝이란
- 명시적으로는 프로그래밍을 하지 않고도 컴퓨터에 학습할 수 있는 능력을 부여하는 학문
- 즉, 주어진 데이터를 통해 규칙을 찾는 것
- 과거 데이터 (경험)이 쌓여감에 따라 주어진 Task의 성능이 점점 좋아질 때, 컴퓨터 프로그램은 경험으로부터 학습한다라고 할 수 있음.
머신러닝, 딥러닝의 역사
-
머신러닝(Machine Learning) 은 컴퓨터가 데이터를 학습하고, 이를 바탕으로 예측하거나 결정을 내릴 수 있도록 하는 인공지능(AI)의 한 분야입니다. 머신러닝은 명시적으로 프로그래밍되지 않은 작업을 수행하기 위해 알고리즘을 사용하여 패턴을 찾아내고, 학습된 모델을 통해 새로운 데이터에 대해 예측할 수 있도록 합니다.
-
딥러닝(Deep Learning) 은 머신러닝의 하위 분야로, 인공 신경망(Artificial Neural Network)을 기반으로 한 알고리즘을 사용하여 데이터로부터 고수준의 특징(feature)을 자동으로 학습합니다. 딥러닝은 여러 층(layer)의 신경망을 사용하여 이미지 인식, 음성 인식, 자연어 처리 등과 같은 복잡한 문제를 해결할 수 있습니다.
머신러닝과 딥러닝의 역사
-
1950년대 - 1970년대
- 머신러닝의 기초는 1950년대와 1960년대에 수학과 통계학의 발전과 함께 형성되었습니다. 1956년 다트머스 회의(Dartmouth Conference)에서 인공지능(AI)이라는 용어가 처음 사용되었습니다.
- 1959년, 아서 사무엘(Arthur Samuel)은 '컴퓨터가 명시적인 프로그래밍 없이 스스로 학습할 수 있다'는 아이디어를 제시하며 "머신러닝"이라는 용어를 처음 사용했습니다.
- 1960년대에는 인공 신경망의 기초가 되는 퍼셉트론(Perceptron) 모델이 개발되었지만, 당시의 컴퓨팅 파워와 데이터 부족으로 인해 한계에 부딪혔습니다.
-
1980년대 - 1990년대
- 1980년대에는 여러 층의 뉴런을 사용한 다층 퍼셉트론(Multilayer Perceptron)과 역전파 알고리즘(Backpropagation)이 개발되면서 인공 신경망이 다시 주목받기 시작했습니다.
- 1990년대에는 통계적 학습 이론이 발전하면서 서포트 벡터 머신(SVM), 결정 트리(Decision Tree), 랜덤 포레스트(Random Forest)와 같은 다양한 머신러닝 알고리즘이 개발되었습니다.
-
2000년대 - 현재
- 2000년대 이후, 인터넷의 발전과 빅데이터의 등장, 그리고 GPU의 발전으로 인해 대량의 데이터와 높은 연산 성능을 활용할 수 있게 되면서 딥러닝이 급격히 발전하게 되었습니다.
- 2010년대 초반, 제프리 힌튼(Geoffrey Hinton)과 그의 연구팀은 딥러닝을 이용한 이미지 인식 대회(Imagenet)에서 뛰어난 성과를 거두었고, 이를 계기로 딥러닝이 주목받기 시작했습니다.
- 이후 딥러닝은 음성 인식, 자연어 처리, 자율 주행, 의료 진단 등 다양한 분야에서 활용되며 빠르게 발전하고 있습니다.
딥러닝의 최근 성공은 주로 딥러닝 알고리즘의 개선, 대규모 데이터셋의 활용, 그리고 GPU와 같은 고성능 하드웨어의 발전 덕분에 가능해졌습니다. 머신러닝과 딥러닝은 앞으로도 인공지능의 핵심 기술로써 다양한 분야에서 더 많은 혁신을 가져올 것입니다.
데이터의 관찰
- 유명한 IRIS 데이터를 활용 ( Scikit-learn 라이브러리에 기본적으로 포함되어 있는 Sample Dataset )
IRIS 데이터 관찰
- Datasets import
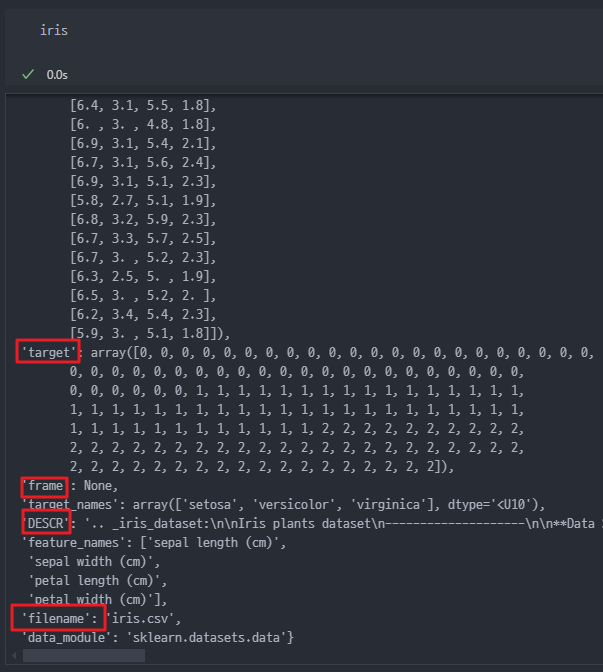
- 실제 IRIS 데이터는 Dict와 유사한 형태로 데이터가 저장된 것을 확인.
- 데이터 Type 은
<class 'sklearn.utils._bunch.Bunch'>
- iris.key() → keys 형태들을 살펴본다.

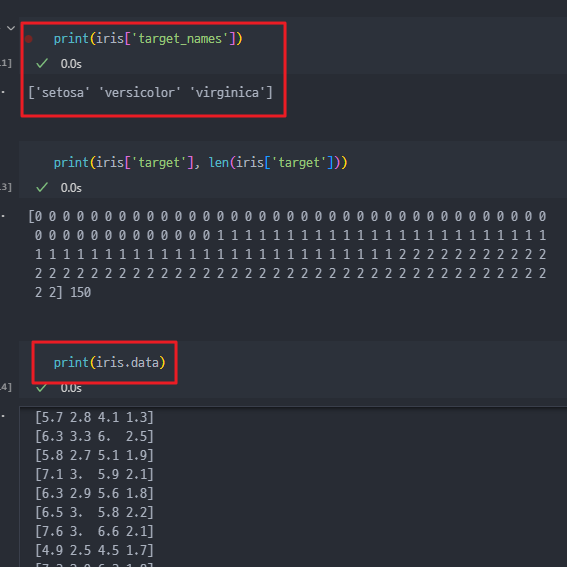
- 데이터 호출은 위 두가지 형태 모두 가능하다.
iris['data']oriris.data
- 사람은 과연 peral, sepal의 length 와 width로 품종을 구분할 수 있을까 ?

- 결국 사람도 구분하기 위해서는 IRIS(붓꽃)의 특성을 공부하고 품종을 공부해야 한다.
- 품종 : Versicolour, virginica, setosa
IRIS Data To DataFrame
- pandas를 통해서 IRIS 데이터를 DataFrame으로 변경. 여기서 컬럼은 기존 데이터 활용하여 지정

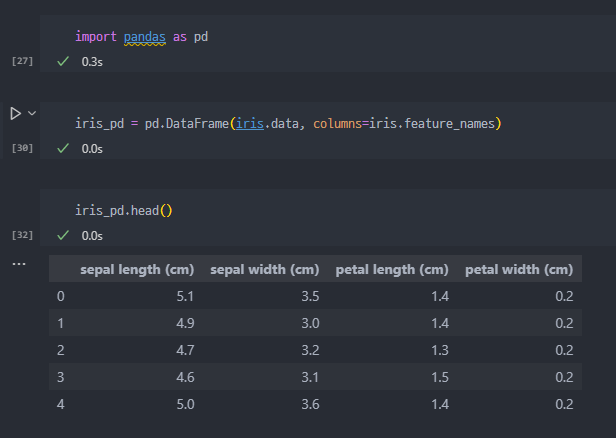
- 컬럼 이름을 아래의 사진처럼 별도지정할 수 있다.
- 만들어진 DataFrame에서 Species 컬럼 추가

그래프
- 일단 데이터 불러와서 그래프 그려보자.
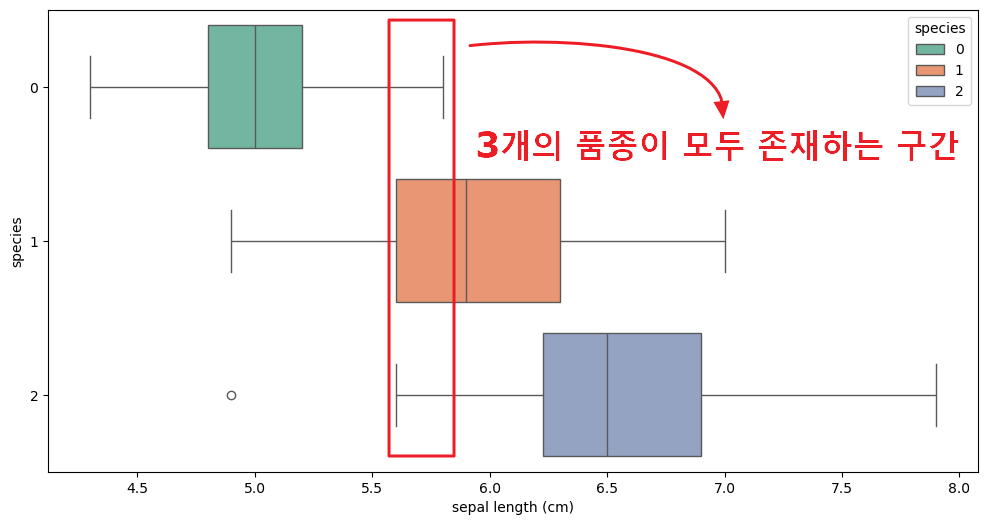
- sepal length 데이터로만은 품종( setosa, Versicolour, virginica )을 구분하기 쉽지 않다.
- 다른 데이터를 활용해서 보자
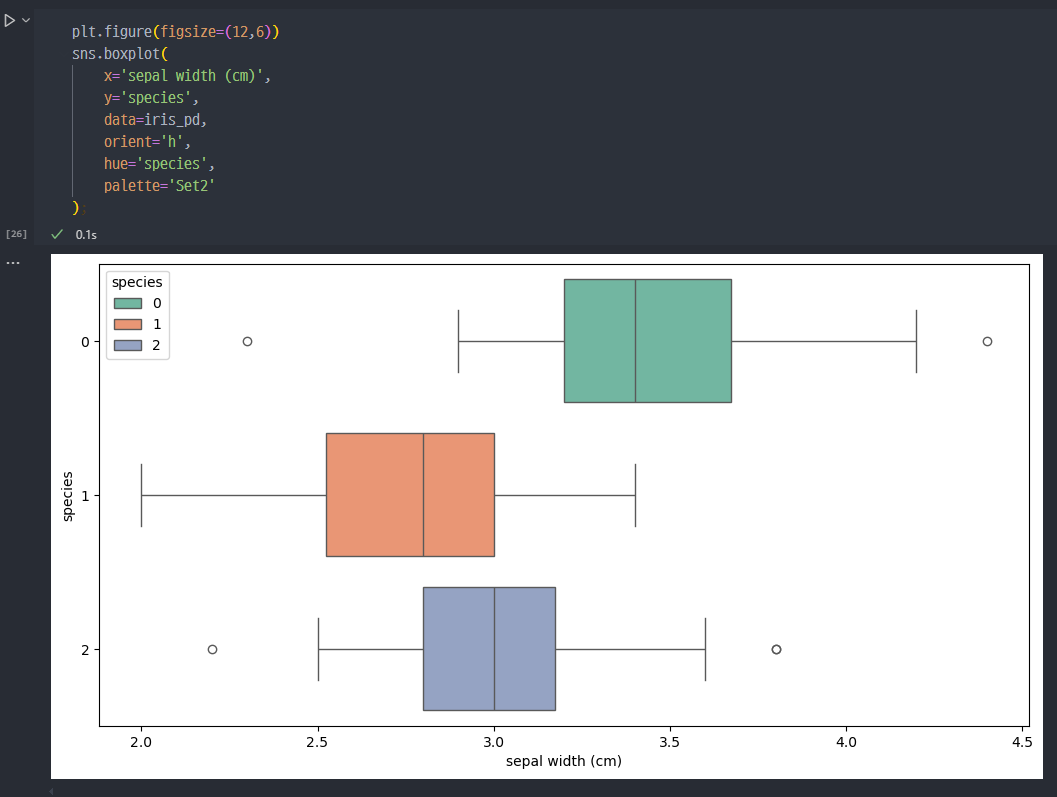
- sepal _ width를 활용해도 특별히 구분할 수 있는 특성은 보이지 않는다.
- 또 다른 데이터를 활용해서 보자
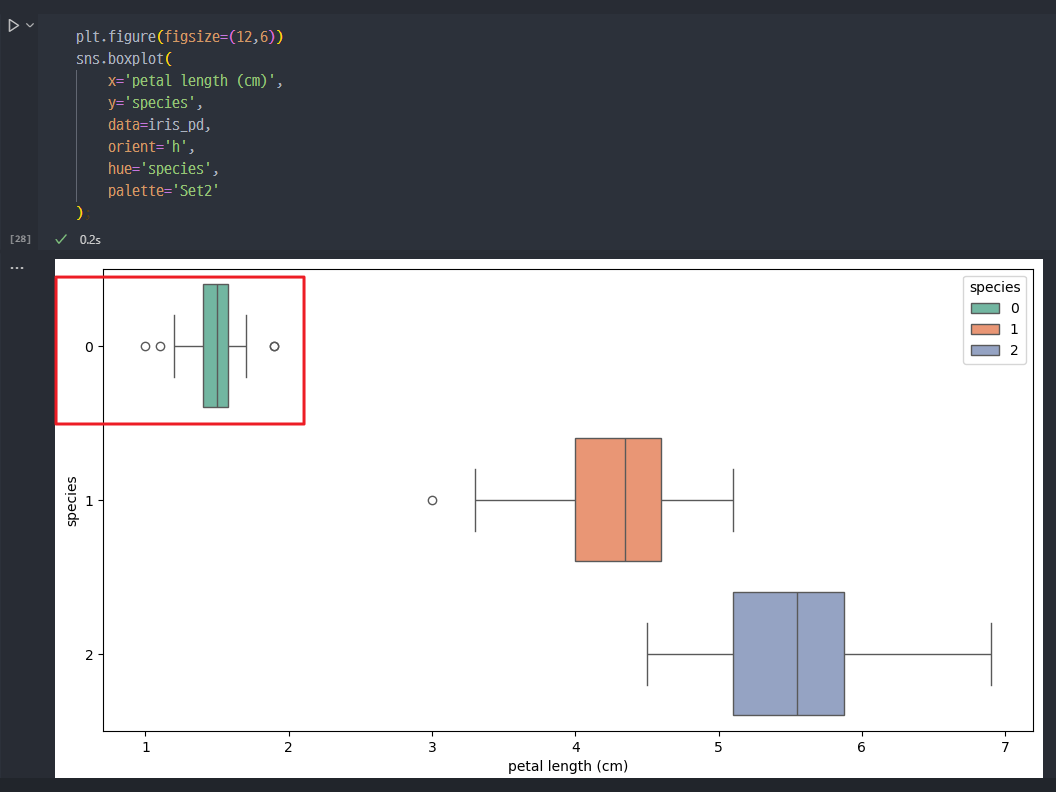
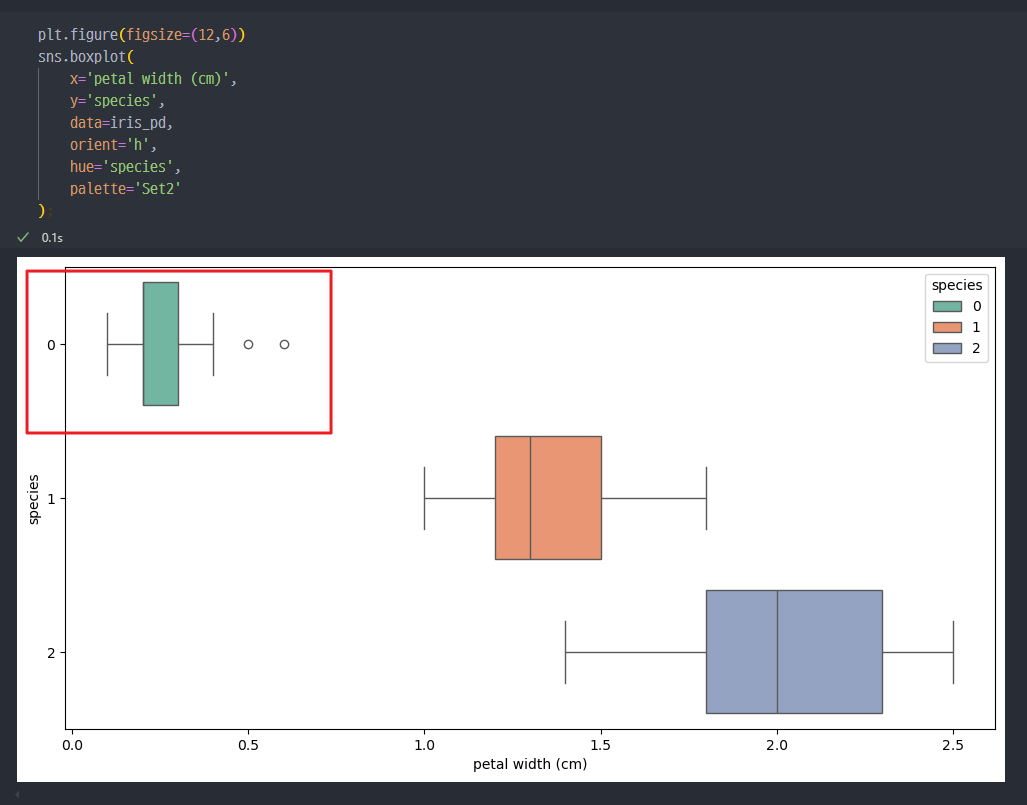
- petal _ length, width 데이터를 확인 시, petal_length, width는
Setosa 품종을 구분하거나 대표하는 특징이라고 할 수 있다.
- pairplot을 활용해서 확실히 대조해보자.
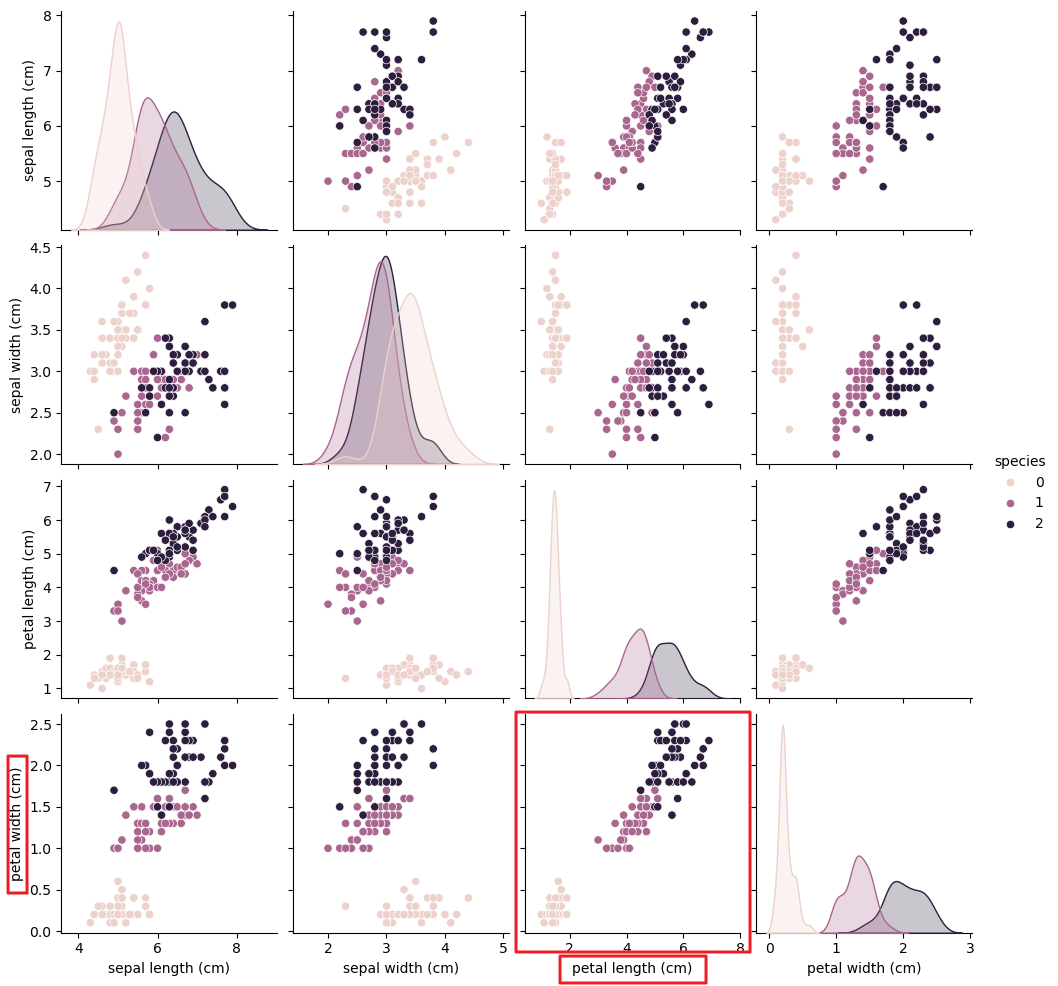
- 확실하게 petal은 일부 품종을 구분할 수 있는 특성 이 될 수 있을것 같다.
- 좀 더 확대해서 그래프를 보고 해석하게 되면..
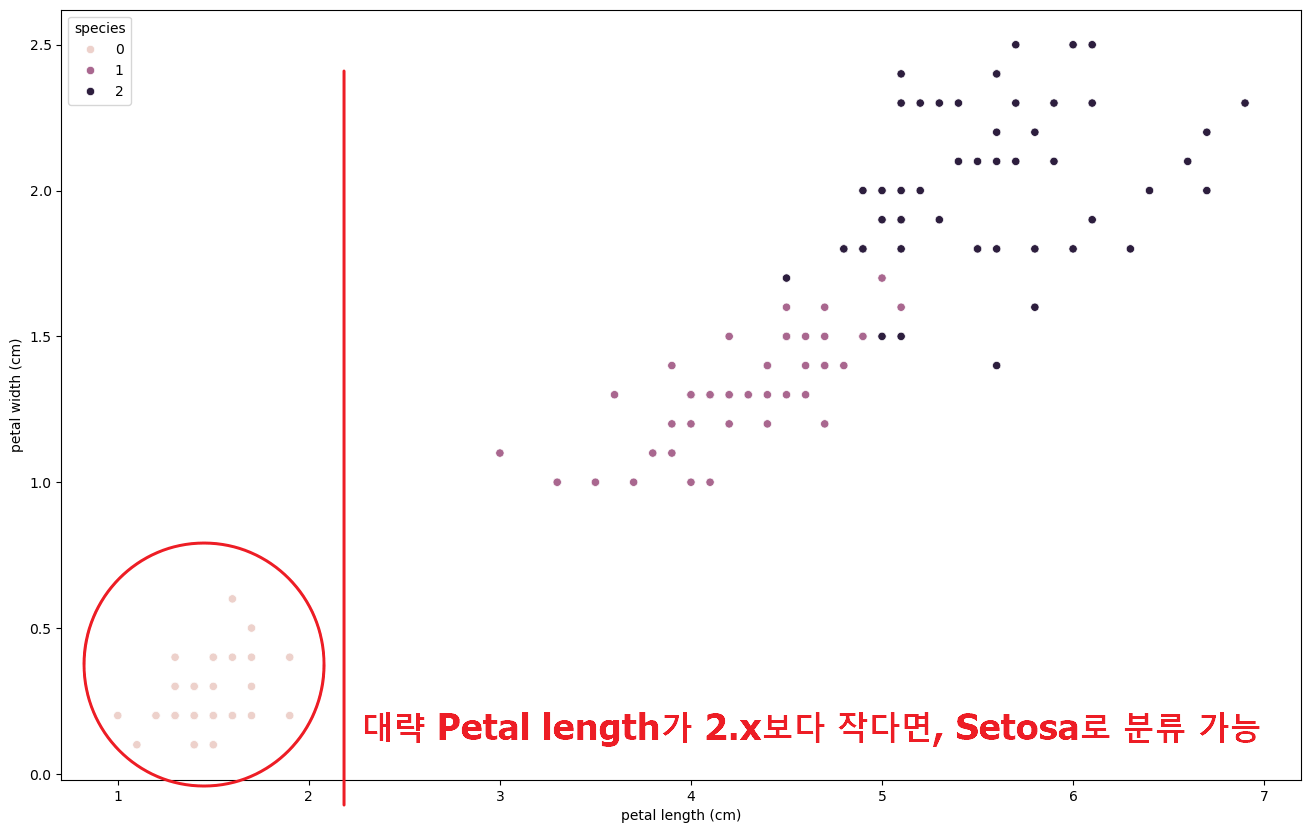
-
petal length에 대하여 기준을 마련하여Setosa는 분류 가능하다.
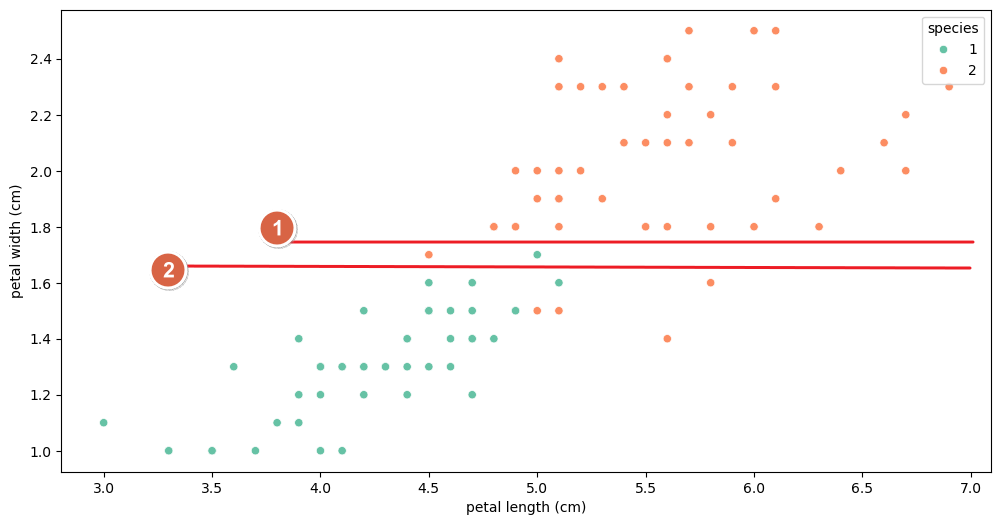
- 나머지 두 개 품종에 대한 분석 ( Versicolour, Virginica )
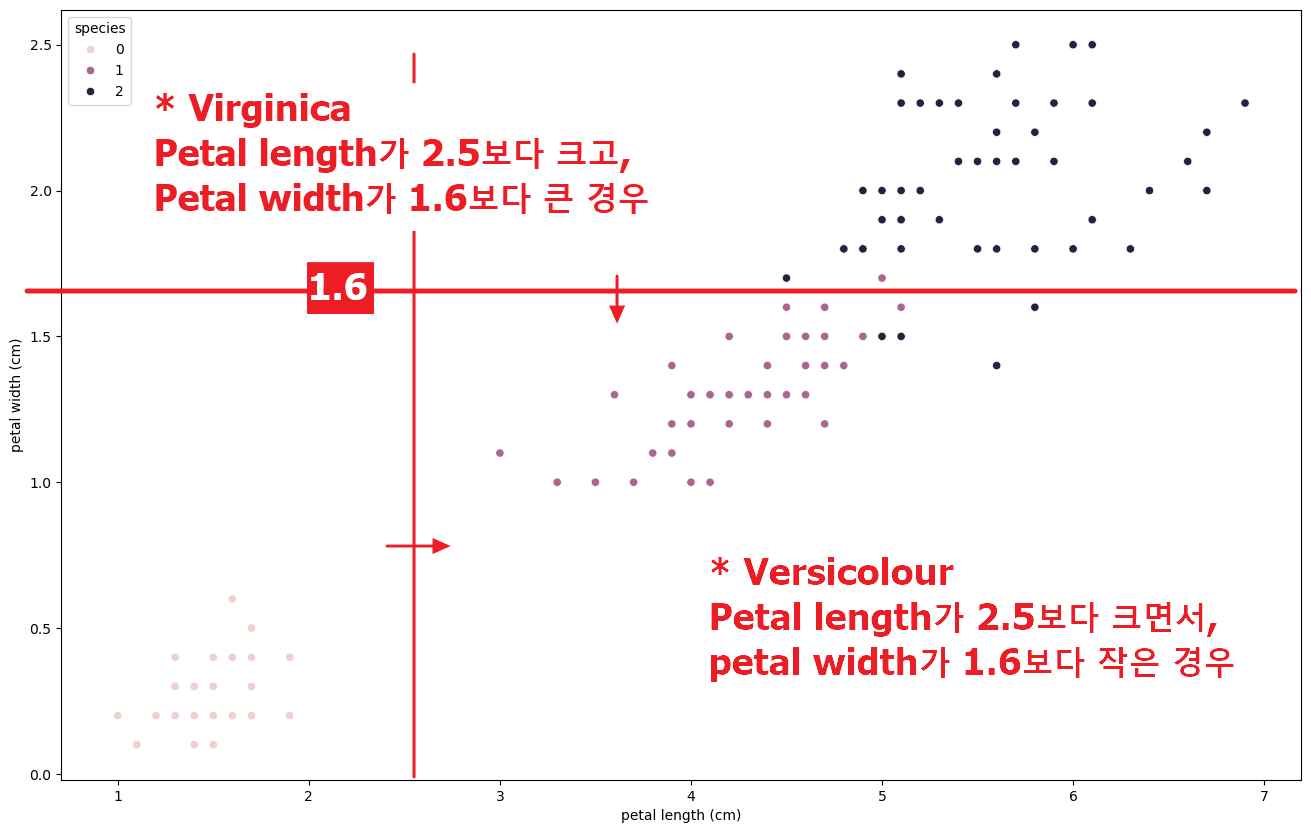
- 몇 개의 이질적인 데이터는 어쩔 수 없지만, petal width 1.6을 기준으로 Versicolour 품종과 Virginica 품종 구분
- 따라서,
Decision Tree의 경우- Petal length 가 2.5보다 작은 경우 →
Setosa품종 - 그렇지 않은 경우,
- Petal width가 1.6보다 작은 경우 →
Versicolour품종 - Petal width가 1.6보다 큰 경우 →
Virginica품종
- Petal width가 1.6보다 작은 경우 →
- Petal length 가 2.5보다 작은 경우 →
- 위와 같은 근거가 되는 구조, 방법, 선택사항 등이
알고리즘
Decision Tree
-
Machine Learning의 첫 번째 개념으로는
Desicion Tree등장. -
위의 IRIS 데이터에서 1차적인 데이터 구분은 Petal length 2.5를 기준으로 Setosa 품종을 구분하였고, 그 다음으로 Petal Width 1.6 기준으로 Versicolour 와 Virginica 품종을 구분하였다.
-
여기서, Petal length 2.5 기준은 너무나 명확하여 이견이 없을 수 있지만, Petal width 1.6이라는 기준은 임의로 진행한 거지 명확한, 구체적인 근거가 부족하다.
-
결국 왜 1.6인지, 1.7 또는 1.5는 안되는지, 1.65가 더 적합한지 등 구체적인 근거와 기준을 알고리즘을 통해 마련하는 것이 Desicion Tree 라고도 할 수 있다.
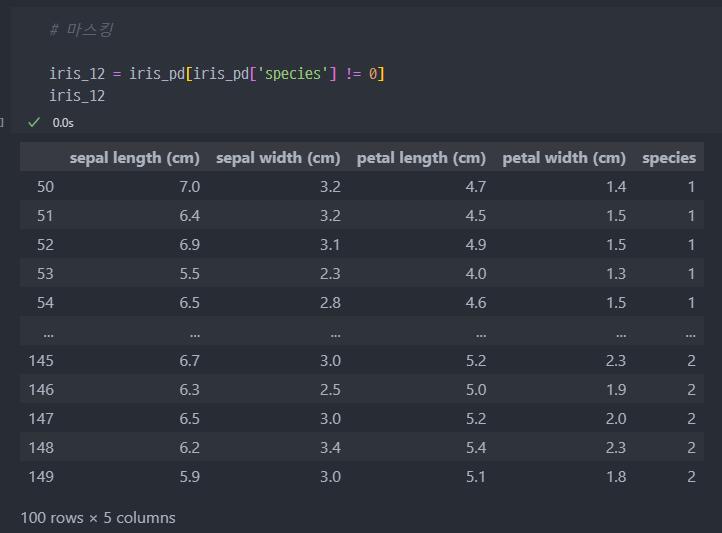
데이터 변경 (기준마련 위한)
- species 가 0 인 Setosa는 제외하고, 나머지 품종에 대하여 마스킹, iris_12로 데이터 정의
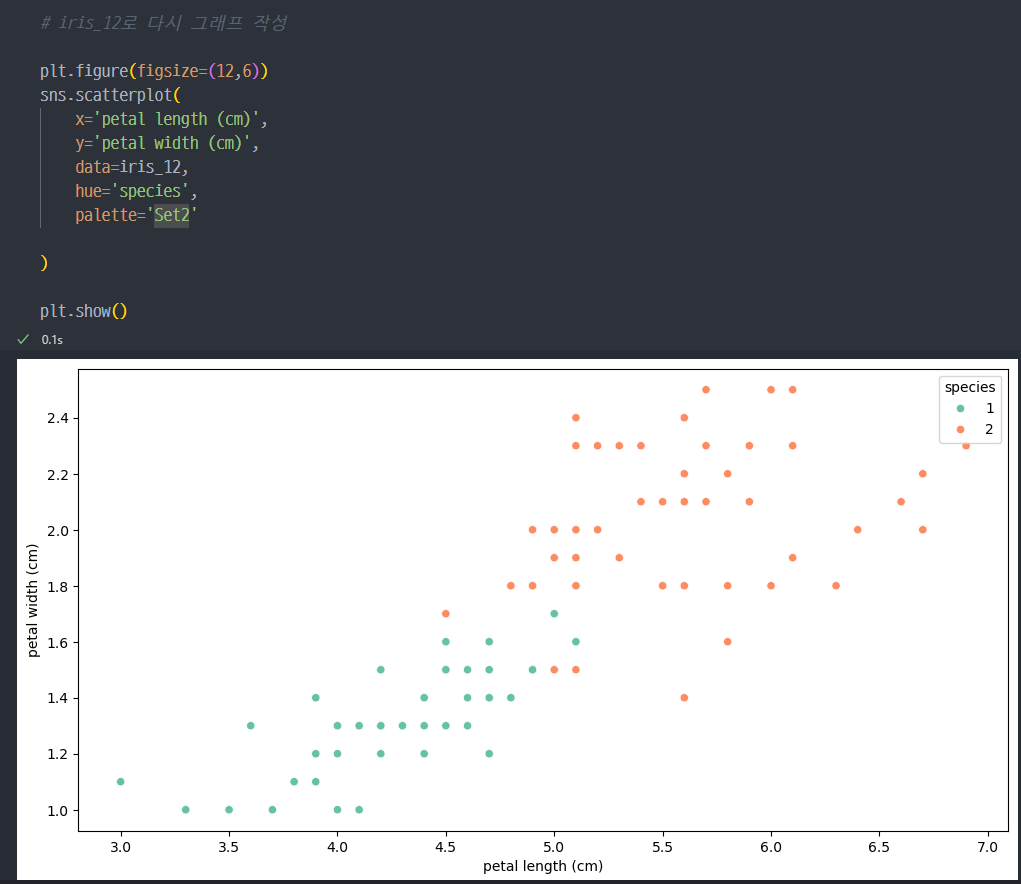
iris_12데이터로 다시 그래프 작성
Decision Tree의 분할기준
- Split Criterion
결국 데이터 구분에 있어서 어느것을 기준으로 정할것인가에 대한 문제.
-
정보 획득 (Information Gain)
- 정보의 가치를 반환하는데 발생하는 사전의 확률이 작을수록 정보의 가치는 커진다.
- 정보 이득이란, 어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것
- 엔트로피 개념
- 열역학의 용어로 물질의 열적 상태를 나타내는 무리량의 단위 중 하나. 무질서의 정도를 나태냄
- 1984년 엔트로피 개념에서 힌트를 얻어 확률 분포의 무질서도나 불확실성 혹은 정보 부담 정도를 나타내는 정보 엔트로피 개념을 클로드 섀넌이 고안함.
※ Entropy (엔트로피) : 얼마만큼의 정보를 담고 있는가? 또한, 무질서도(disorder)를 의미, 불확실성(uncertainty)를 나타내기도 함.
정보 엔트로피
- p는 해당 데이터가 해당 클래스에 속할 확률이고, 위 식을 그려보면 아래와 같다.
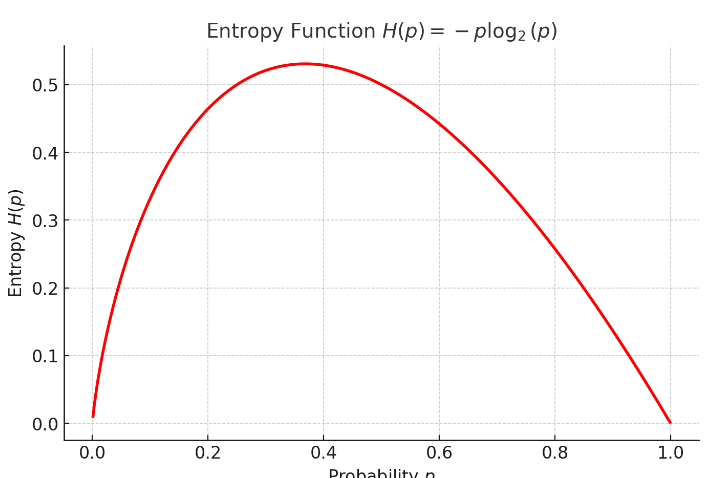
- 어떤 확률 분포로 일어나는 사건을 표현하는데 필요한 정보의 양이며, 이 값이 커질수록 확률 분포의 불확실성이 커지며, 결과에 대한 예측이 어려워짐.
- 엔트로피는 이 확률들의 합이다.
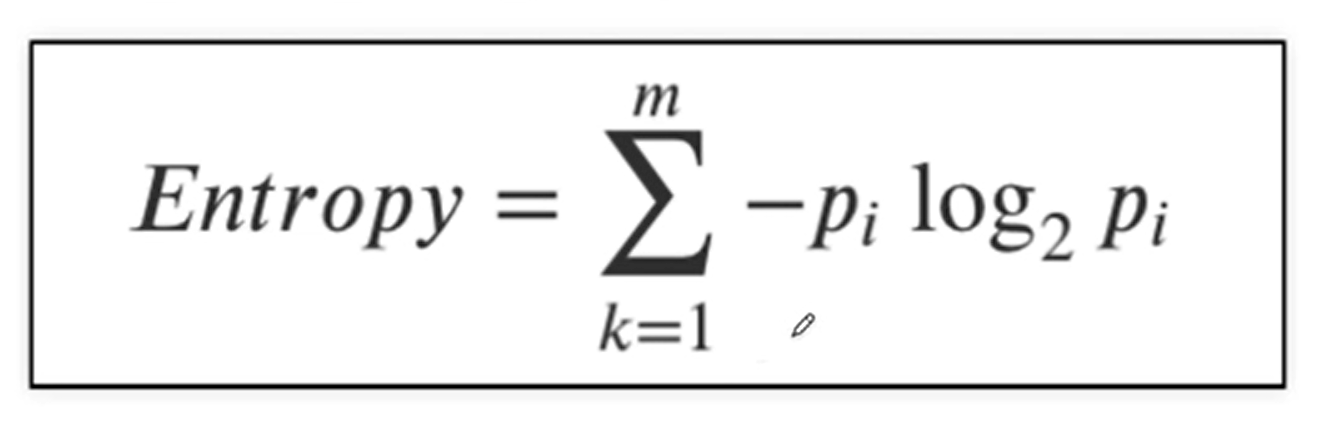
※ 엔트로피 연습.
- 공이 총 16개가 있는데 이 중 10개가 빨강색, 6개가 파란색.
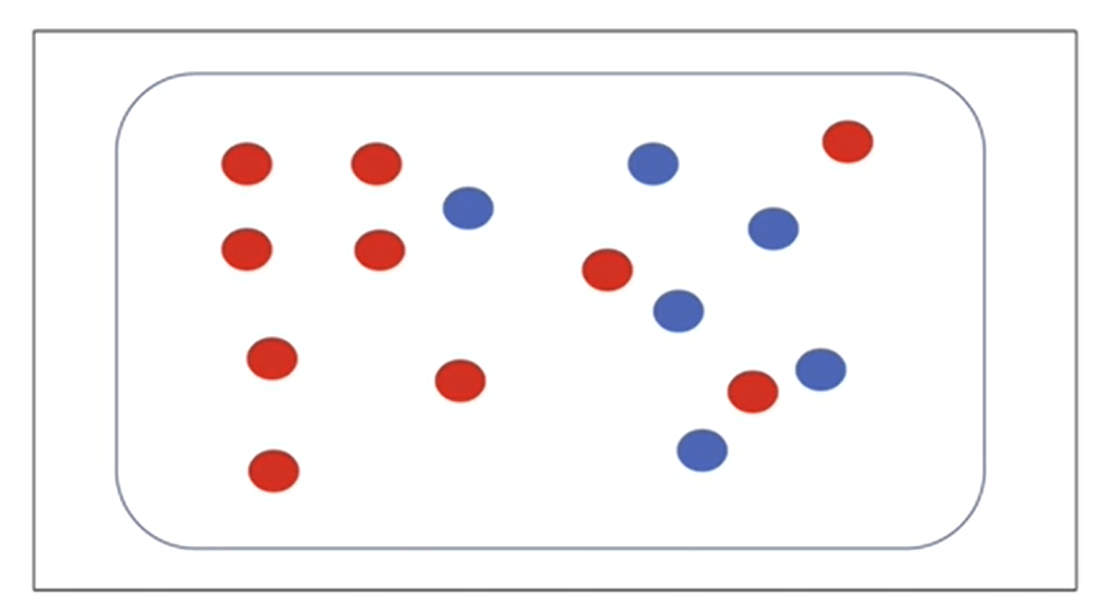
Entropy =[ -10/16 X log_2(10/16) ] + [ - 6/16 X log_2(6/16) ] = 0.954...
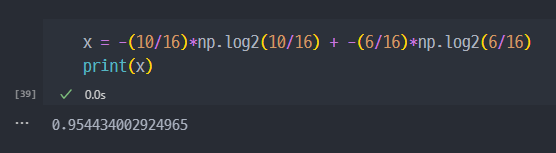
분할을 통한 엔트로피 감소 → 이 경우 분할하는 것이 좋다.
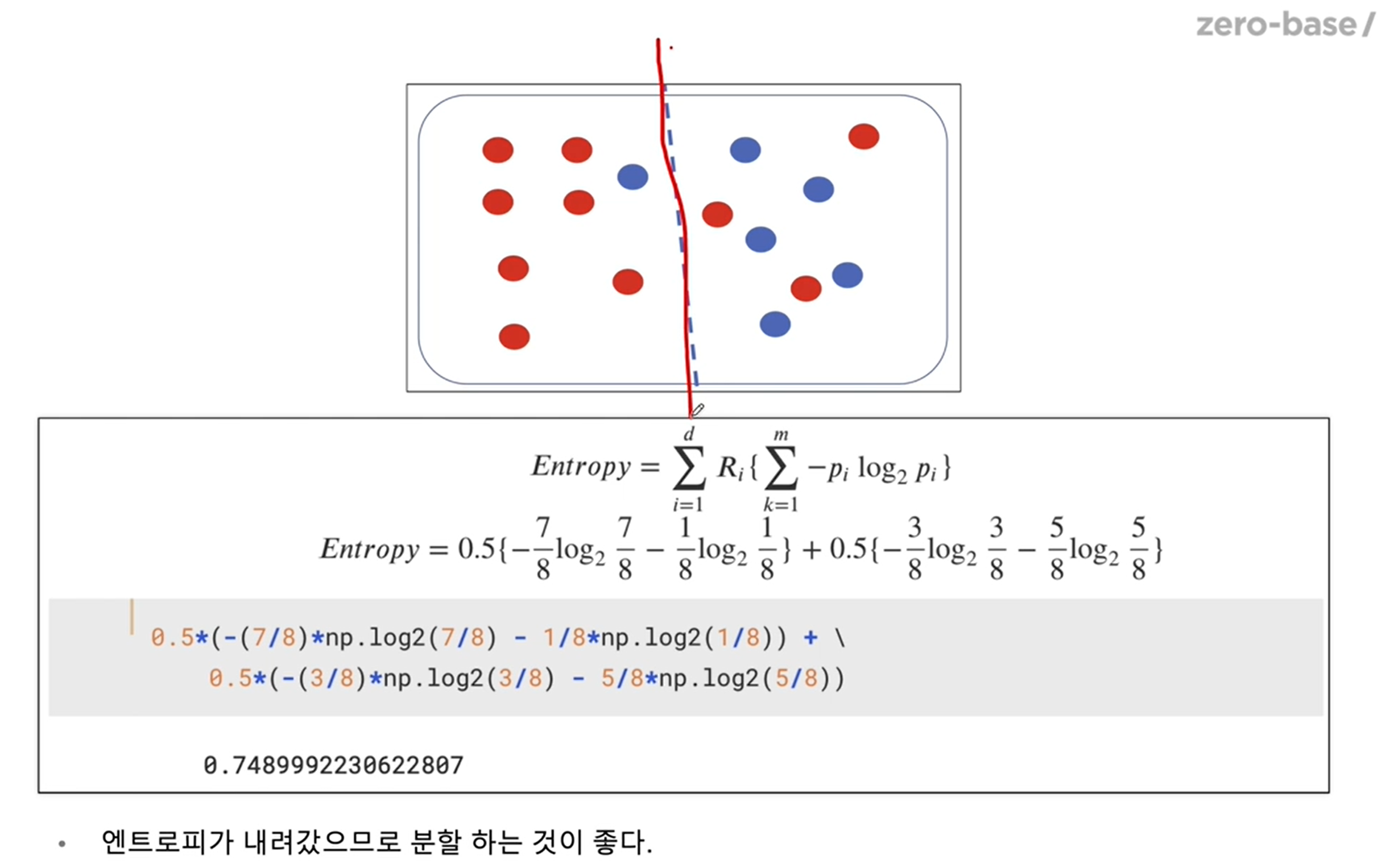
- (참고) 엔트로피 식을 이용하면 계산량이 많아지는 단점이 있다. 이렇기에
지니 계수라는 보다 계산량이 적은 식을 사용할 수 있다.
Scikit Learn
- 2007년 구글 썸머 코드에서 처음 구현
- 현재 파이썬에서 가장 유명한 기계 학습 오픈 소스 라이브러리
- Scikit-Learn 개요
Scikit-Learn은 파이썬을 기반으로 한 오픈 소스 기계 학습 라이브러리로, 다양한 데이터 분석 및 모델링 작업을 지원합니다. 데이터 과학과 기계 학습 분야에서 널리 사용되며, 사용자가 쉽게 접근할 수 있는 고수준의 API를 제공합니다. Scikit-Learn은 특히 회귀, 분류, 군집화, 차원 축소 등 다양한 기계 학습 알고리즘을 포함하고 있어 데이터 전처리부터 모델링, 평가까지의 전 과정을 간편하게 수행할 수 있게 합니다.
- 역사
Scikit-Learn은 2007년 프랑스의 David Cournapeau에 의해 시작되었으며, 2010년에 첫 번째 공식 버전이 릴리스되었습니다. Scikit-Learn은 사이킷-이미지(scikit-image)와 같은 다른 Scipy 프로젝트와 함께, NumPy와 SciPy 라이브러리를 기반으로 구축되었습니다. 초기에는 Cournapeau가 Google Summer of Code 프로그램의 일환으로 개발하였으며, 이후 여러 개발자들의 기여로 점차 성장하였습니다.
Scikit-Learn은 기계 학습을 더 쉽게 사용할 수 있도록 파이썬의 단순함과 우수한 성능을 결합한 것이 특징입니다. 현재는 커뮤니티 주도로 유지 관리되고 있으며, 기계 학습 교육용 라이브러리로서의 역할도 충실히 하고 있습니다.
- 주요 기능
Scikit-Learn은 다음과 같은 주요 기능을 제공합니다:
- 데이터 전처리: 데이터 정규화, 누락된 값 처리, 카테고리형 데이터 인코딩 등.
- 회귀 및 분류 알고리즘: 선형 회귀, 로지스틱 회귀, 서포트 벡터 머신, 결정 트리, 랜덤 포레스트 등 다양한 모델이 포함되어 있습니다.
- 군집화 알고리즘: K-평균, 계층적 군집화, DBSCAN 등.
- 차원 축소: PCA(주성분 분석), LDA(선형 판별 분석) 등.
- 모델 선택 및 평가: 교차 검증, 모델 평가 메트릭(예: 정확도, 정밀도, 재현율 등).
- 사용처
Scikit-Learn은 다음과 같은 다양한 분야에서 사용됩니다:
- 데이터 분석 및 시각화: 데이터의 패턴을 찾고 시각화하여 의미 있는 통찰을 도출하는 데 사용됩니다.
- 기계 학습 모델 개발: 분류, 회귀, 군집화 등 여러 종류의 기계 학습 모델을 신속하게 개발하고 평가하는 데 유용합니다.
- 의료, 금융, 마케팅 등의 산업 분야: 예측 분석(예: 고객 이탈 예측, 질병 진단), 위험 관리, 추천 시스템 등에서 사용됩니다.
- 교육 및 연구: Scikit-Learn은 기계 학습 개념을 배우고 실습하는 데 널리 사용되는 도구로, 많은 강의와 책에서도 주로 사용됩니다.
- 전망
Scikit-Learn은 지속적으로 발전하고 있으며, 앞으로도 중요한 기계 학습 도구로 자리매김할 가능성이 높습니다. 이는 다음과 같은 이유 때문입니다:
- 광범위한 사용자 기반과 커뮤니티: 오픈 소스 프로젝트로서 활발한 커뮤니티 지원을 받으며, 지속적인 업데이트와 개선이 이루어지고 있습니다.
- 확장성 및 호환성: Scikit-Learn은 TensorFlow, PyTorch 등 다른 기계 학습 라이브러리와 함께 사용할 수 있어, 복잡한 기계 학습 워크플로를 쉽게 통합할 수 있습니다.
- 교육 및 학습 도구로서의 역할: 기계 학습을 배우려는 학생 및 연구자들에게 적합한 라이브러리로서 그 인기는 계속될 것입니다.
- 산업계에서의 지속적인 활용: Scikit-Learn은 다양한 산업 분야에서 데이터 분석 및 예측 모델링에 널리 사용되기 때문에, 앞으로도 기업의 데이터 기반 의사결정을 지원하는 핵심 도구로 자리할 전망입니다.
Sklearn Decision Tree

- sklearn.tree 호출
- 데이터 탐색
- 데이터 분할
- sklearn 학습
Sklearn Fit에 대한 Accuracy 확인
- predict을 통해 예측
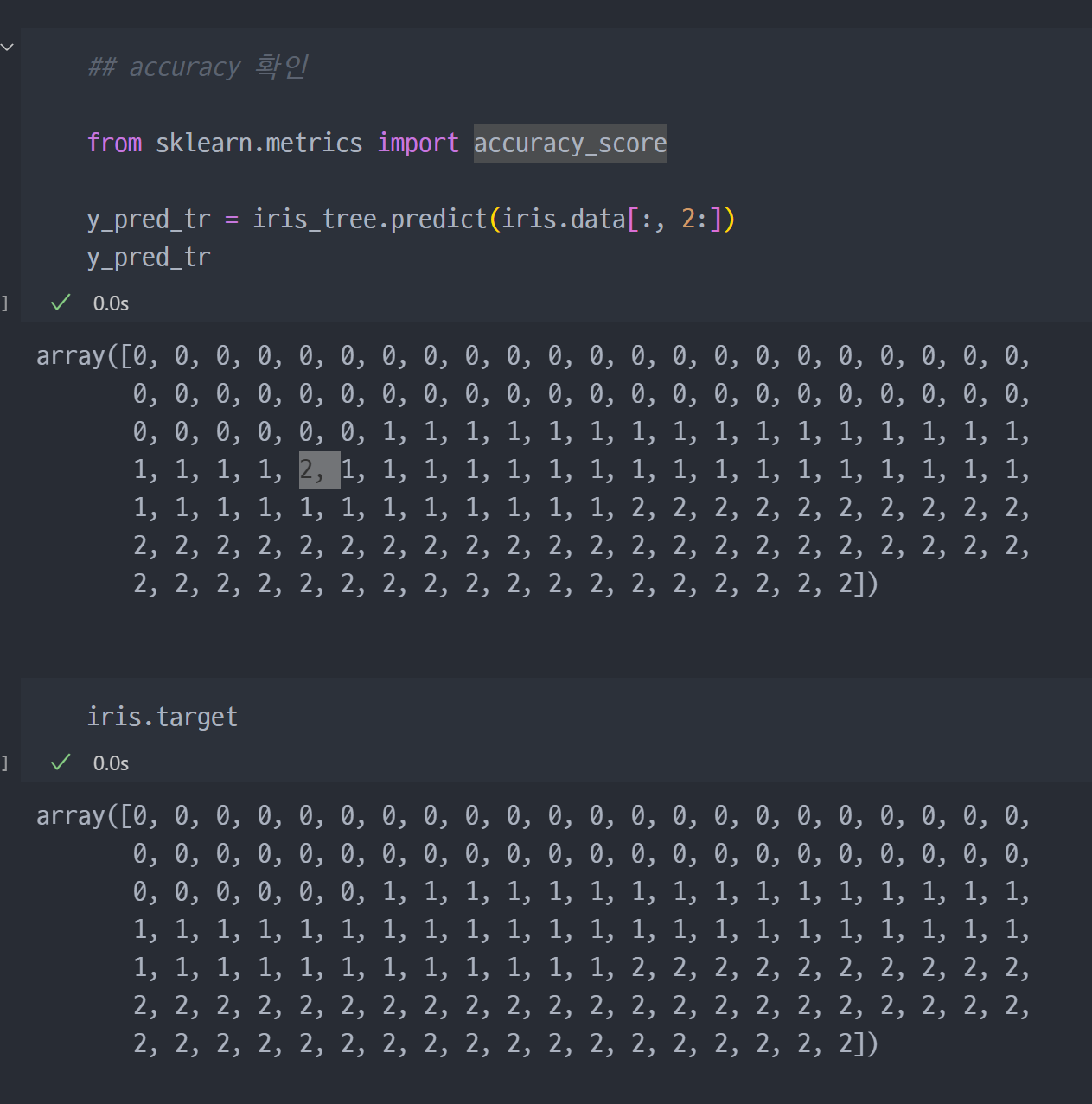
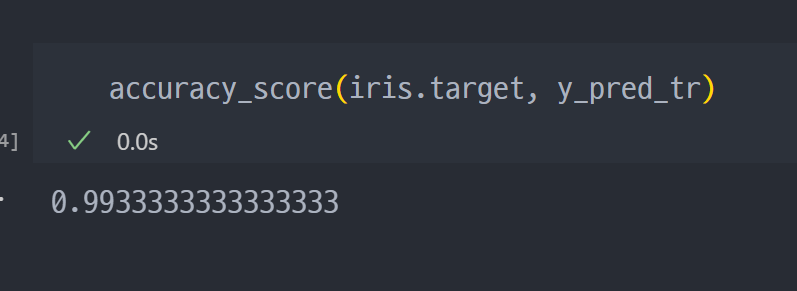
- 기존 정답 (iris.target) 과 학습으로 도출한 predict 값(y_pred_tr) 비교
- 위 과정은 아주아주 개념적인, 개략적인 과정.
