
과적합
- 머신러닝, 딥러닝에서 가장 많이 나타나는 혹은 첫 번째 확인해야 할 포인트 → 과적합
과적합(Overfitting) 은 머신러닝이나 딥러닝 모델이 훈련 데이터에 너무 잘 맞도록 학습된 경우를 말합니다. 이로 인해 모델이 훈련 데이터에 대한 성능은 매우 우수하지만, 새로운 데이터(테스트 데이터)에 대해 일반화 능력이 떨어지게 됩니다. 즉, 모델이 새로운 데이터를 예측할 때 성능이 저하되는 현상입니다.
-
과적합이 발생하는 주요 원인
- 훈련 데이터의 부족: 모델이 학습할 수 있는 데이터가 충분하지 않을 때, 모델이 훈련 데이터의 패턴뿐만 아니라 노이즈까지 학습하게 됩니다.
- 모델의 복잡도: 모델의 복잡도가 너무 높을 때(예: 너무 많은 파라미터나 깊은 신경망 구조), 모델은 훈련 데이터에 있는 모든 세부 사항을 학습하게 됩니다.
- 데이터의 노이즈: 훈련 데이터에 포함된 노이즈나 불필요한 정보까지 모델이 학습할 경우, 과적합이 발생할 수 있습니다.
-
과적합을 방지하는 방법
- 더 많은 데이터 사용: 더 많은 데이터를 수집하여 모델이 일반화할 수 있는 충분한 정보를 제공할 수 있습니다.
- 정규화(Regularization) 기법 사용: L1, L2 정규화와 같은 방법을 사용하여 모델의 복잡도를 제한합니다.
- 교차 검증(Cross-Validation): 모델을 여러 번 훈련하고 검증하여 최적의 파라미터를 찾습니다.
- 드롭아웃(Dropout) 등 규제 기법 사용: 신경망 학습 중 일부 노드를 무작위로 비활성화하여 모델의 복잡도를 줄이는 방법입니다.
- 조기 종료(Early Stopping): 모델의 검증 오류가 감소하지 않거나 증가하기 시작하면 학습을 멈춥니다.
ML의 일반적 절차
- 지도학습
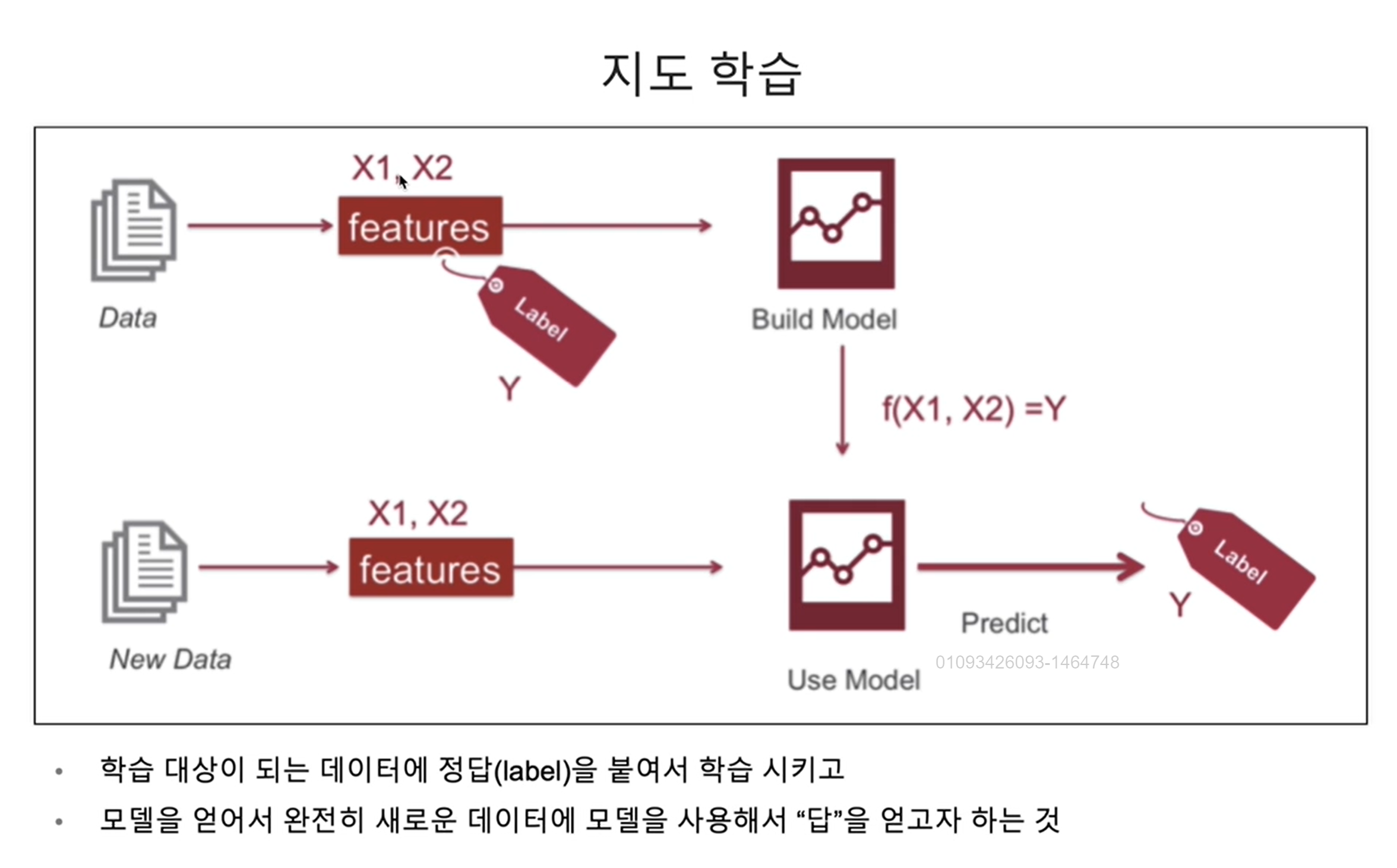
- 일반적으로 ML 안에 DL(Deep learning)이 포함되어 있지만 (학문적으로), 추후에는 별도의 분리 될 것으로 예상한다.
- 정답(label)을 통해서 모델을 만드는 과정을 학습 이라고 함.
- 학습된 모델을 통해서 Predict 하는 과정을 추론 이라고 함.
- 지난 시간에 진행했던, iris decision Tree는 Accuracy가 99.3%
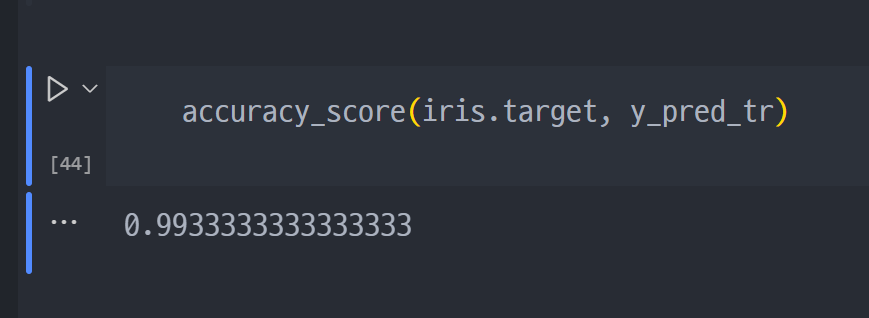
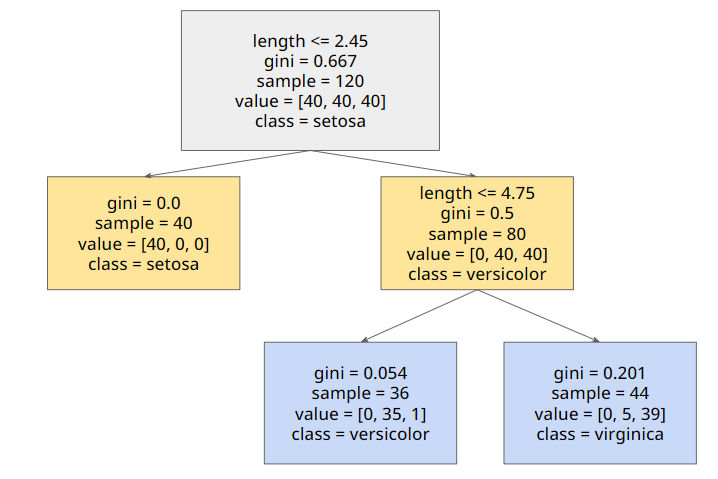
Tree Model Visualization

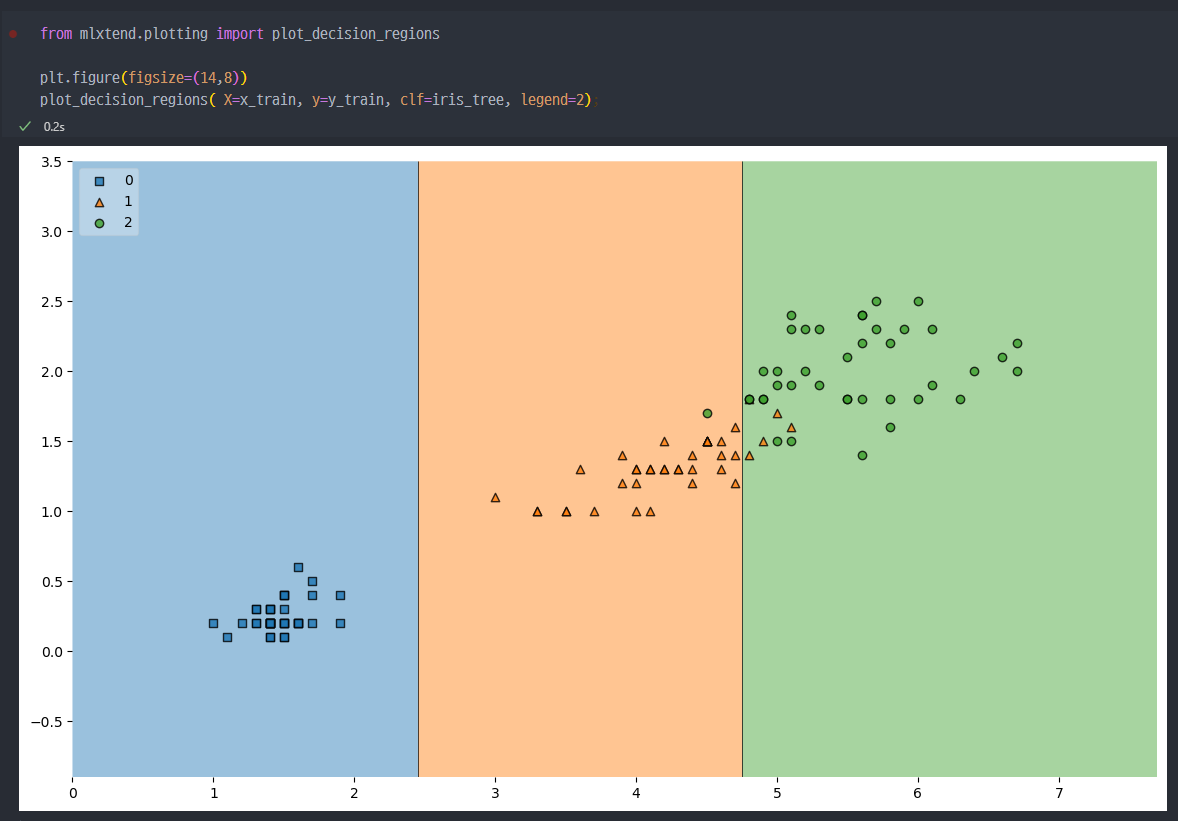
mlxtend 그래프
- 나의 데이터에 따라서, 경계면을 그려주는 함수 :
plot_decision_regions
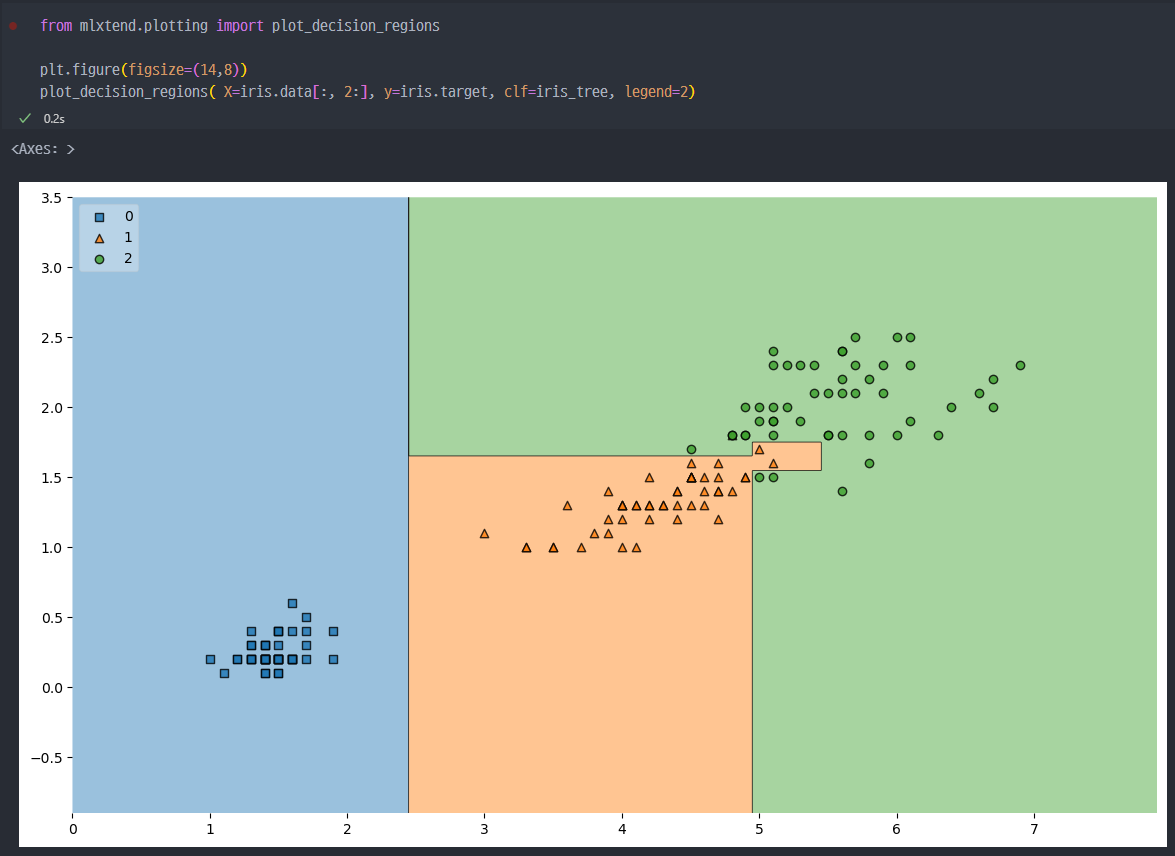
- 해당 데이터에서 보듯이, 복잡한 경계면 (구분하는 선)으로 인해서 수많은 조건문(위 Tree Model 참조)이 탄생하고, Accuracy가 높게 나온것 이다.
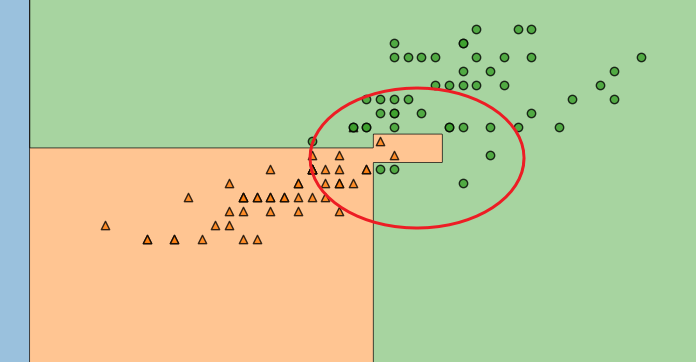
- 저러한 경계면은.. 결국 샘플 데이터를 통해서만 발생되는 경계이다.
- 결국, 제한된 데이터를 가지고 해석함에 있어서 저렇게 복잡한 경계면을 발생시키는 것이 주어진 데이터에서는 좋은 성능을 발휘할 수 있지만 일반적인, 일반화된 데이터에서는 더 심각한 오류를 발생할 수 있다.
- 결국 복잡한 경계면은 모델의 성능을 결국 나쁘게 만든다.
데이터 분리
- 과적합 여부에 대한 판정을 위해서
데이터의 분리가 필요하다. - 또, 더 나아가면, 훈련/학습을 위한 데이터, 검증을 위한 데이터, 테스트를 위한 데이터를 나누는 것이 훨씬 좋은 상황이다.
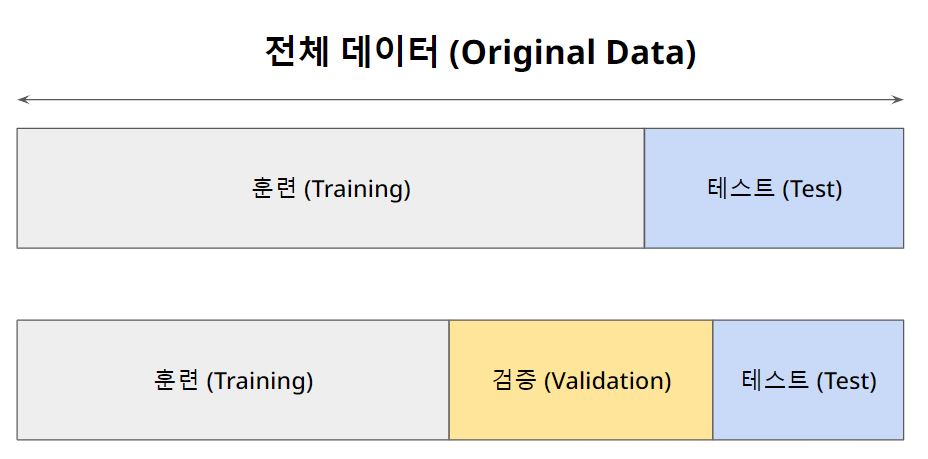
- 즉 확보한 데이터 중에서 모델 합슥에 사용하지 않고 빼둔 데이터를 가지고 모델을 테스트 한다.
이전 과정 재진행 (IRIS data)
- 필요한 라이브러리
import
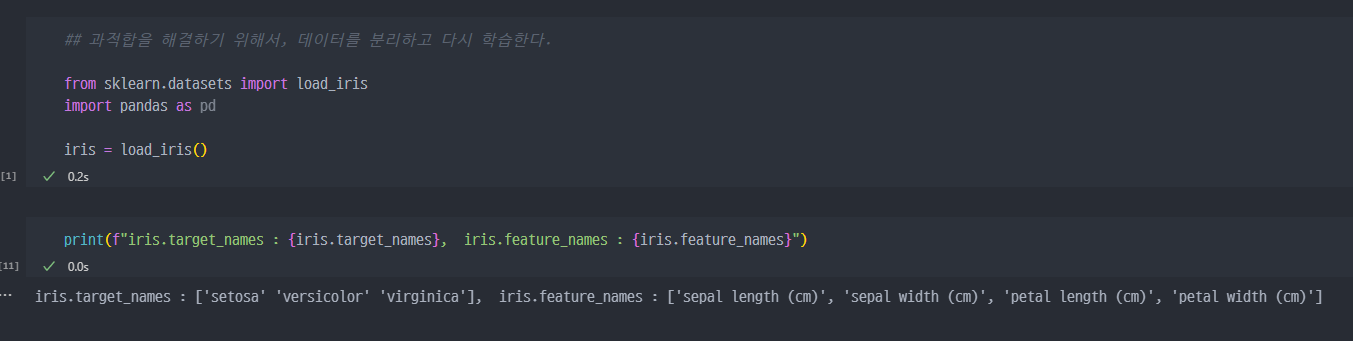
- sklearn에 내장된
train_test-split함수를 통해서 데이터 분할

Unique 검사
- 데이터 분할 시, class가 동일한 비율로 분할되는 것이 좋다.
numpy.unique함수를 통한 검사
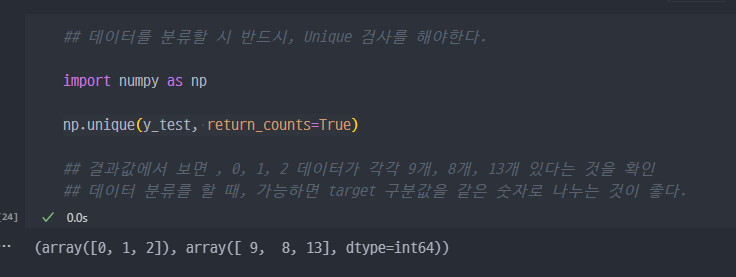
- stratify 옵션을 통해서, class를 같은 비율로 데이터 분할 진행.

분할된 Train 데이터로 Tree Model 생성
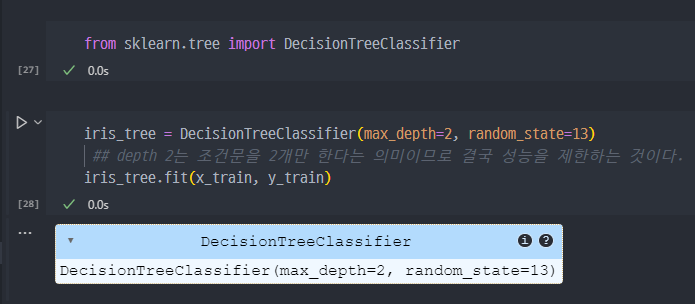
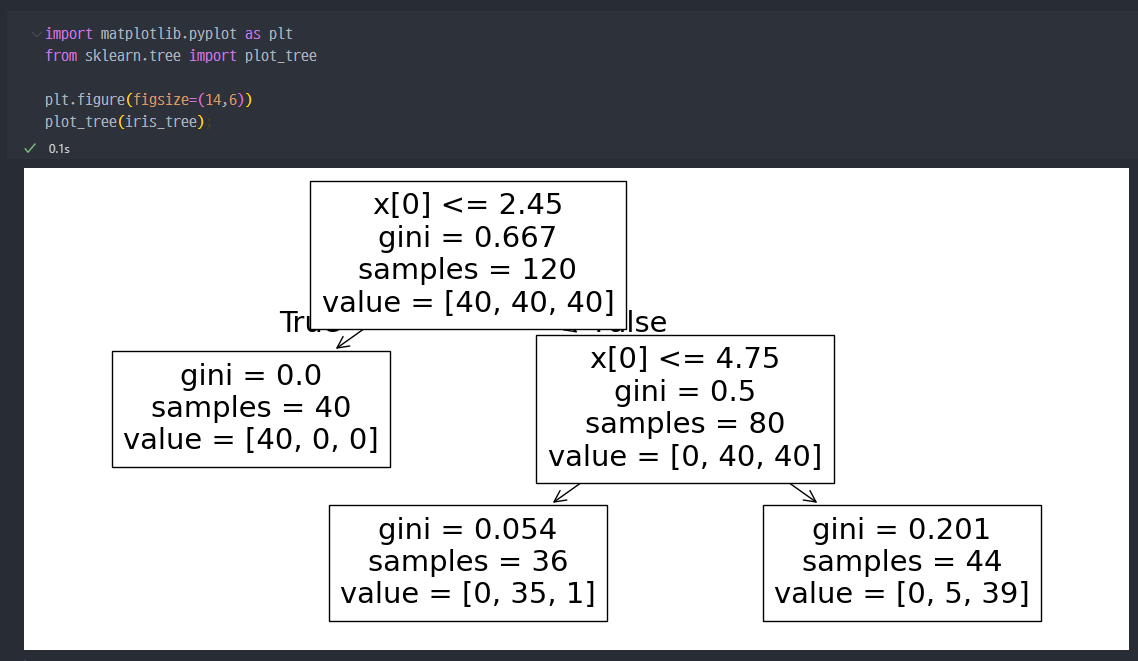
- accuracy 확인

- 처음 만들었던 모델 (acc = 99.3%) 대비하여 95.3%로 감소
iris 꽃을 분류하는 Decision Tree
- 분류된 데이터를 통해 학습한 Tree 모양
- 훈련데이터에 대한 결정경계 확인
- 참고
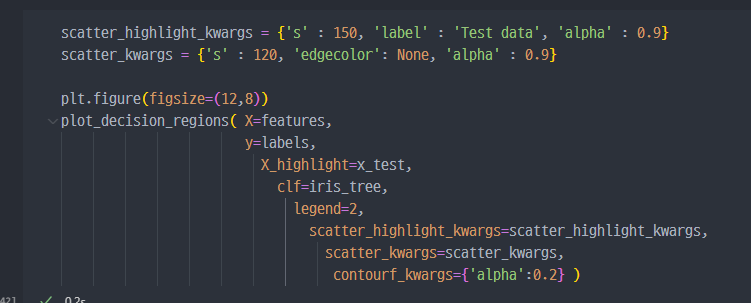
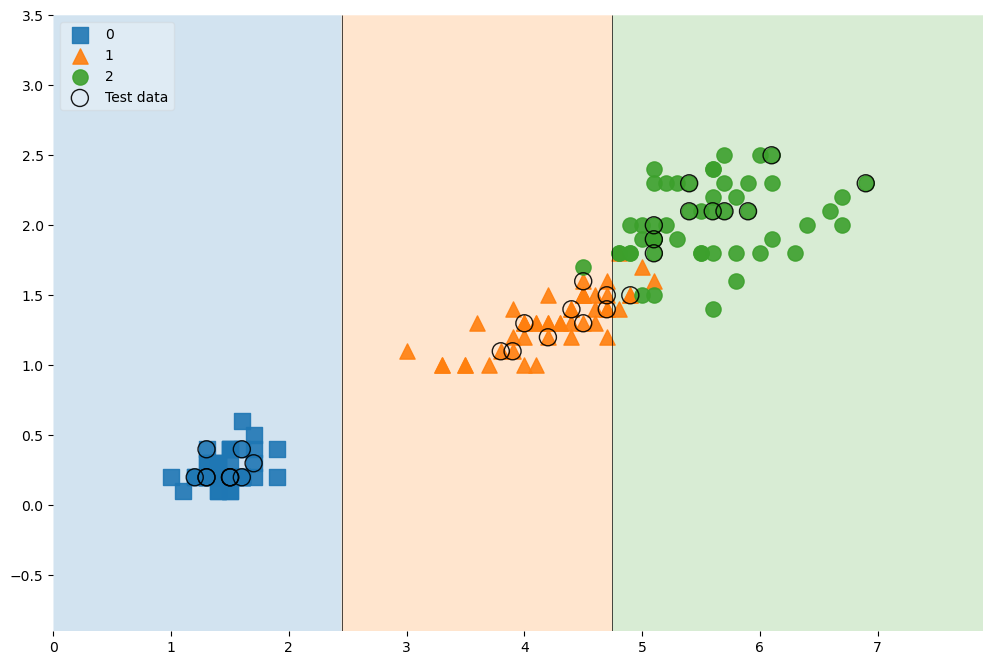
- Test Data를 랜덤하고 잡고, 그 랜덤한 데이터를 그래프에
highlight해주는 기능
예측모델의 사용
- 완성한 예측모델은 아래와 같이 사용하여 예측할 수 있다.
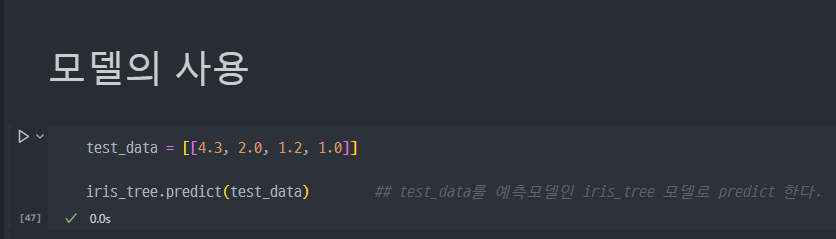
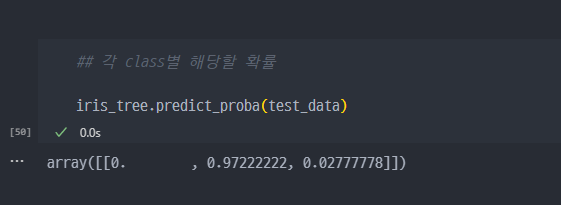
- 각 클래스별 해당할 확률
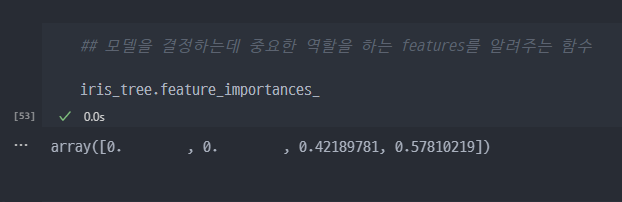
- 예측을 진행할 때, 중요한 features가 무엇인지 확인하는 함수
- 아래의 방법으로도 할 수 있다.

Zip과 언패킹
ZIP
- list를 튜플로 ZIP
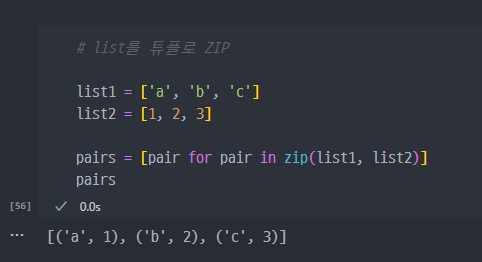
- ZIP된 튜플을 dict으로 변경
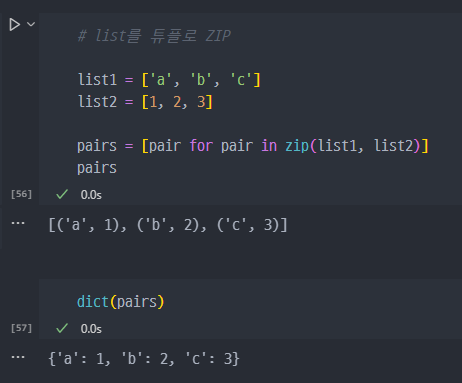
- 아래의 방법으로 바로 zip 하여 dict 형태로 변환도 가능하다.

언패킹
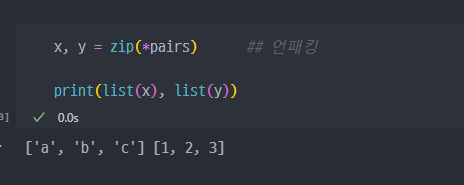

(hellow. world)