
MNIST data using PCA, kNN
titanic에도 적용해보기
MNIST
NIST datasets
- NIST 데이터 셋 (National Institute of Standards and Technology)
- 필기체 인식을 위해서 도입된 데이터셋 (1980년도 말)
- 이 필기체 데이터중에서 숫자만 모아놓은것이 MNIST Datasets 이다

kagglehub를 통해서 해당 데이터셋을 다운로드 받았음.
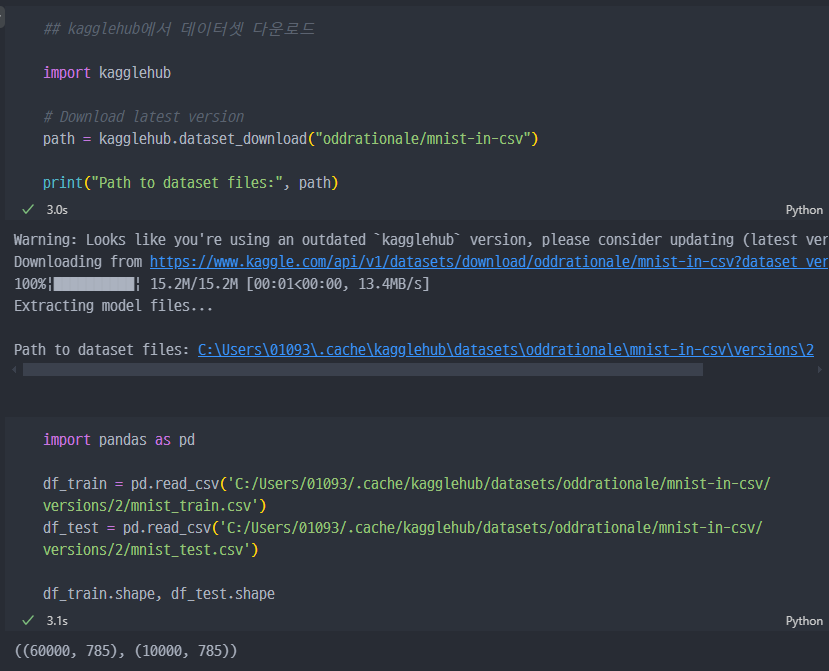
train데이터는60000 개의 행과785 개의 컬럼으로 구성test데이터는10000 개의 행과785 개의 컬럼으로 구성
각 컬럼의 이름들을 살펴보면... 라벨값이 제일처음에 있고 나머지는 feature 값들인 것을 알 수 있음.
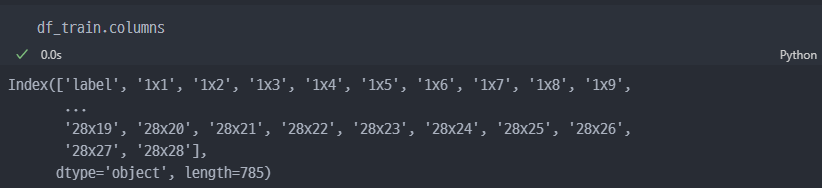
라벨값은 0부터 9까지의 숫자로 이루어진 것을 알 수 있음
데이터 정리 진행
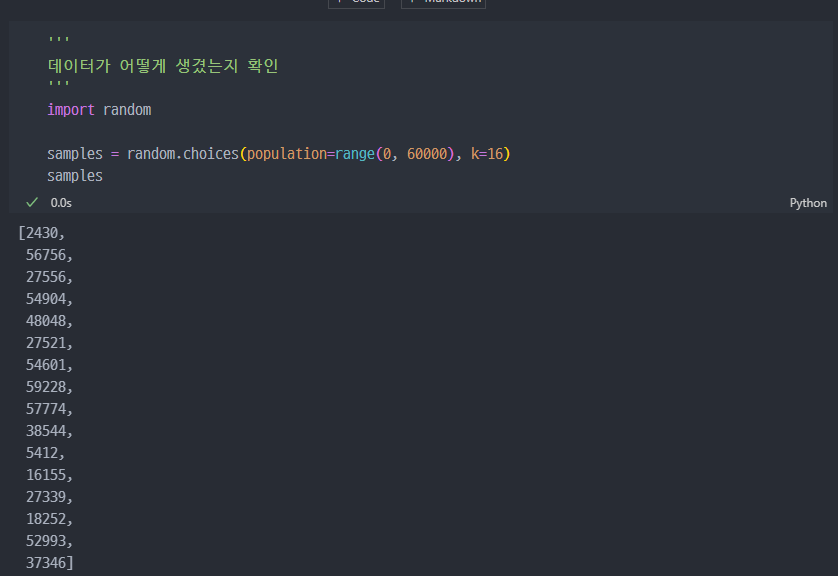
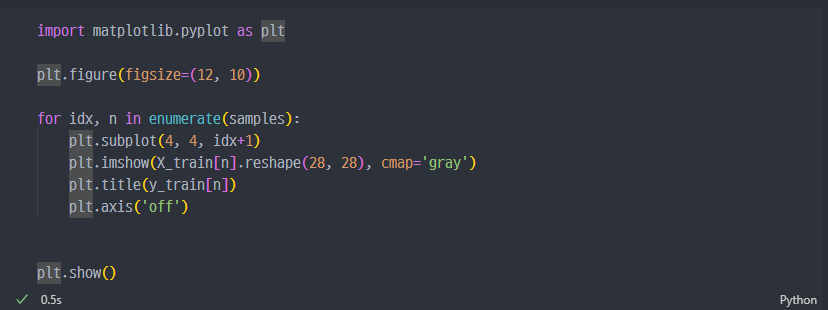
데이터 확인

kNN fit 진행
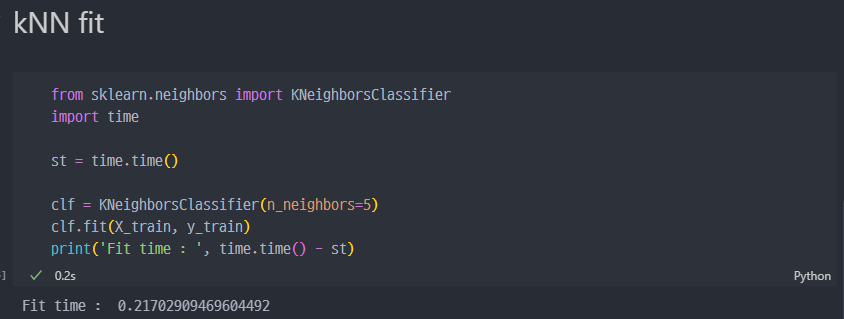
- KNN 분류기를 이용해서 학습(
fit( )) 진행. 5개의 최근접 이웃 찾기
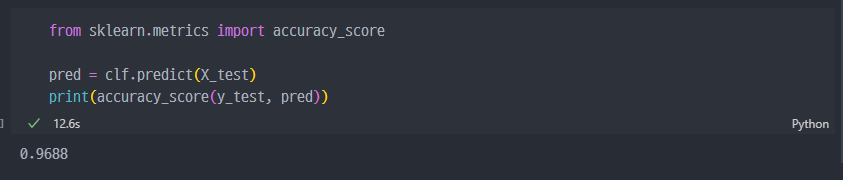
약 12초 정도 걸렸으며,
acc_score는 96% 정도이다.
PCA진행 후, kNN fit 진행
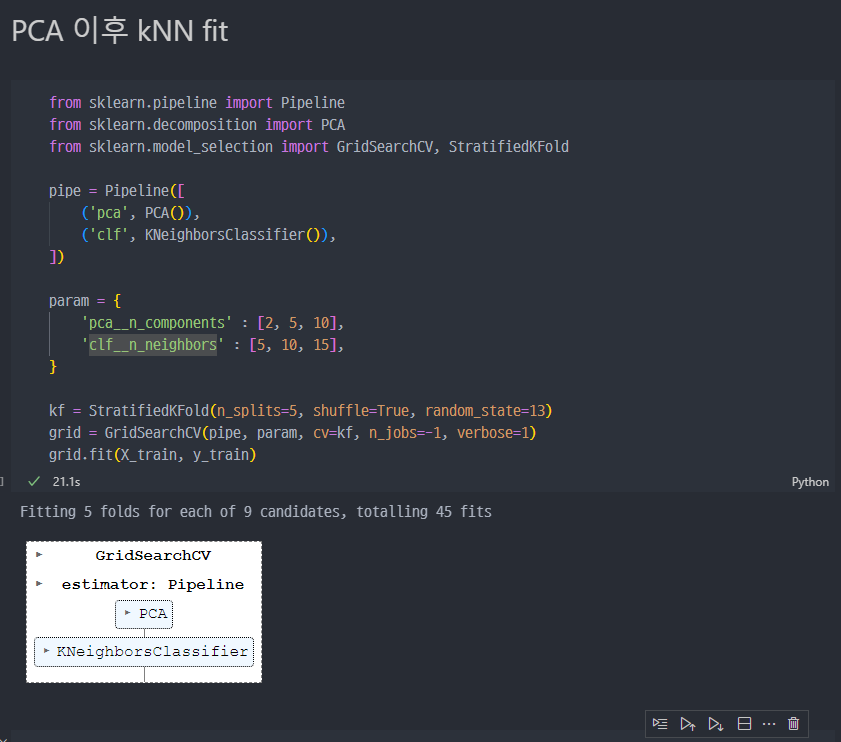
GridSearchCV의 확인
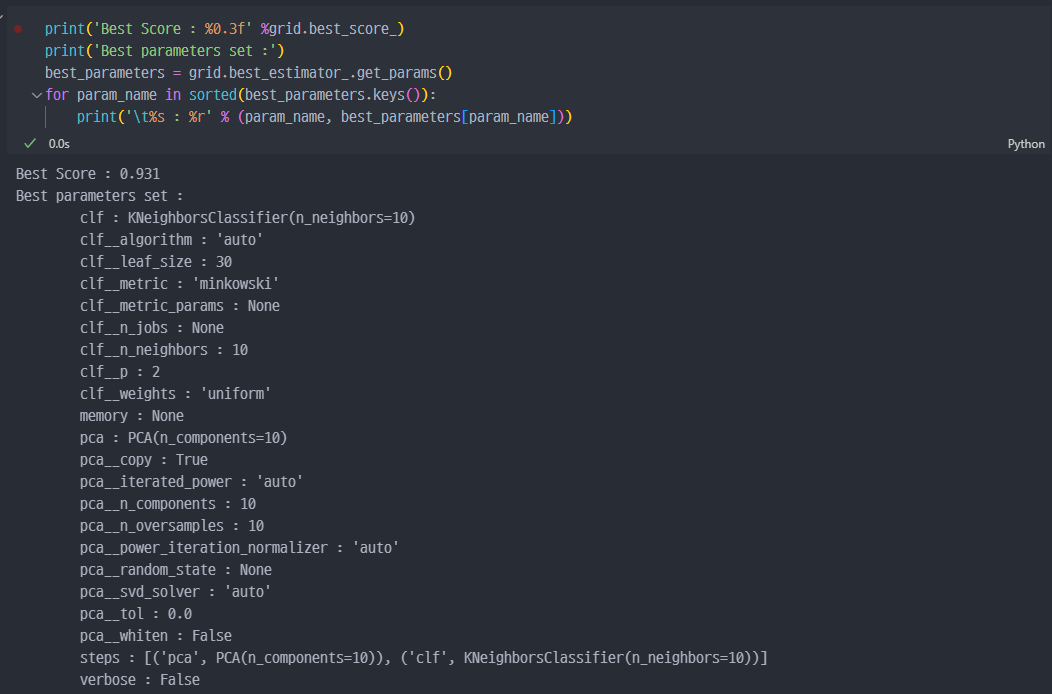
93%까지 score 출력됨.
- test 데이터에 대비해서도 92%정도 나오며, 1초정도 걸린다.
PCA이전에는 12초 정도 걸렸다.- 즉,
PCA는feature의 개수가 많을수록 적용하는것을 고려해야한다는 것을 알 수 있다. - 이번 데이터의
feature의 개수, 즉 컬럼의 수는 약 700개 정도이며, 6만개의 행이 있는 데이터이다.

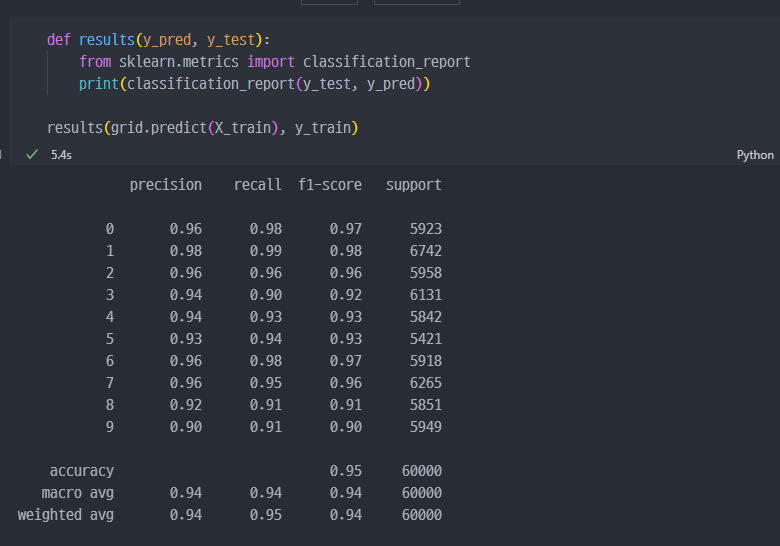
분류모델 테스트
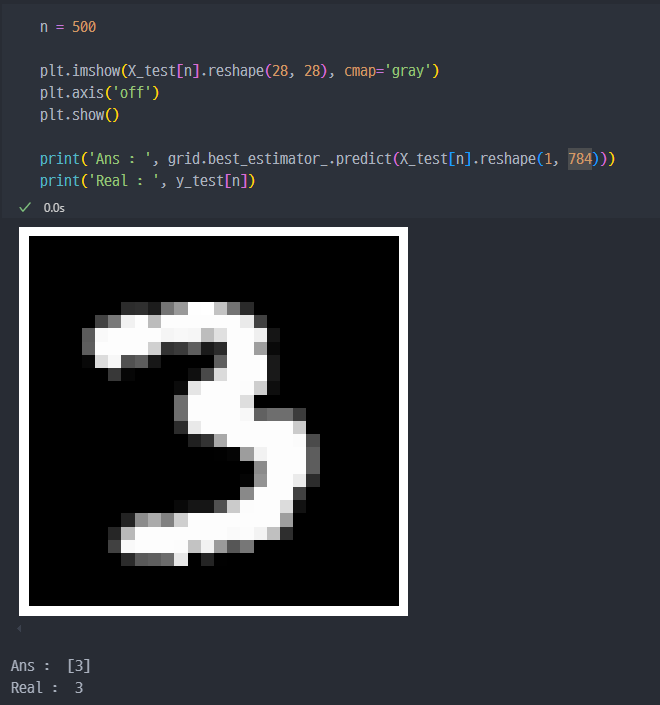

- 마지막에
reshape하는 이유는..grid분류모델이 학습할 때, 6만개의 행과 784개의 열로 이루어진 2차원 배열의 데이터로 학습 진행.- 예측시킨 데이터
X_test[500]의shape을 보면(784,)이므로 1차원 배열.- 그렇기 때문에 학습진행한 데이터와 동일하게 2차원 배열로 변경해주어야 함.
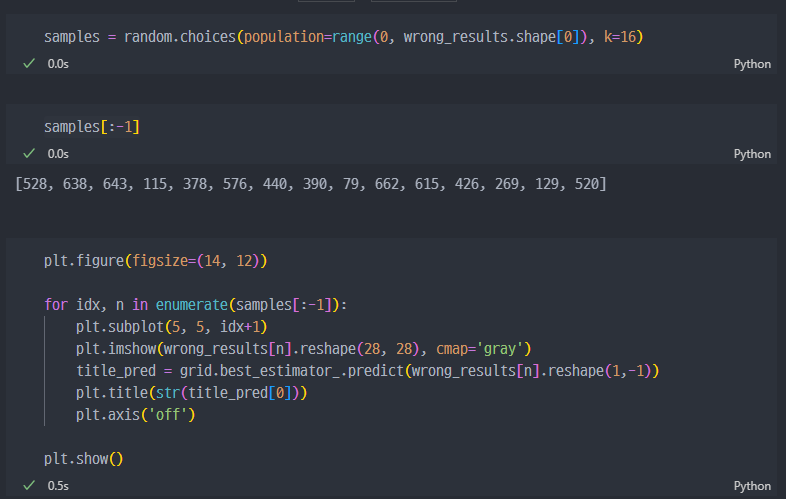
이번에는 틀린 데이터 관찰해보자.

y_test와pred2가 서로 다른X_test값만 마스킹하여 추출

Titanic 데이터에 적용 (간단히)
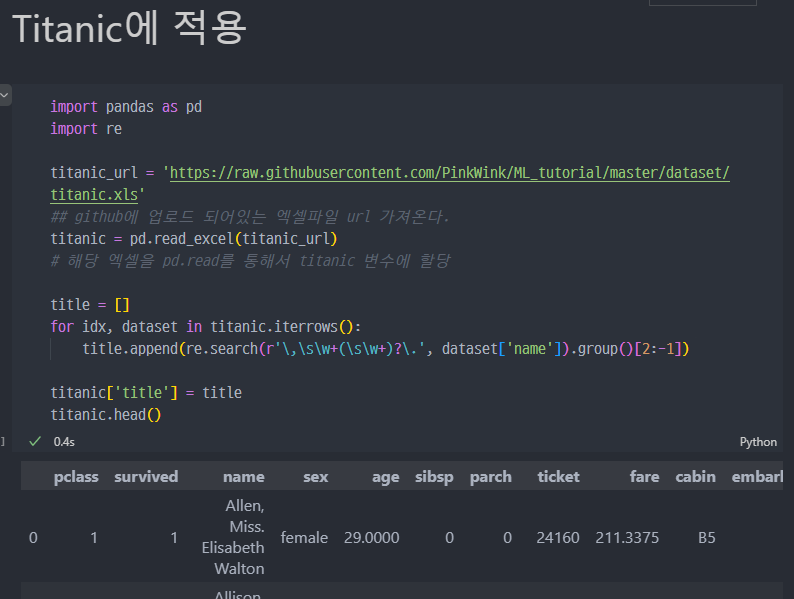
데이터 읽기 및 정규표현식을 이용한
name의 Mr, Miss 등 분류 (title)
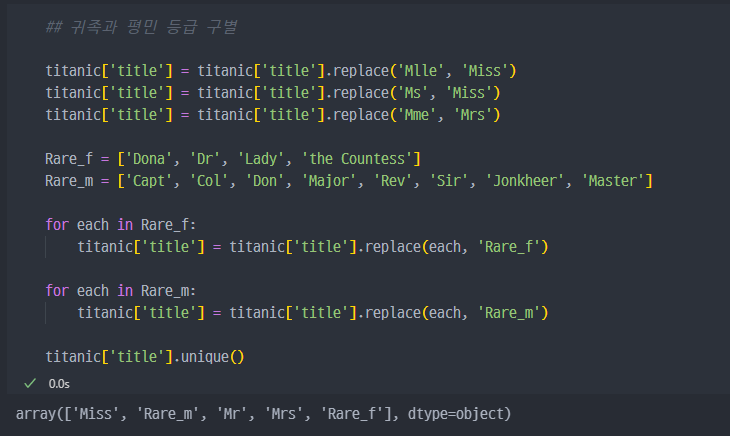
Miss,Mrs,Mr을 제외하고는 나머지는Rare_m또는Rare_f로 변경
labelEncoder()를 이용해서gender컬럼 생성 (남자, 여자)
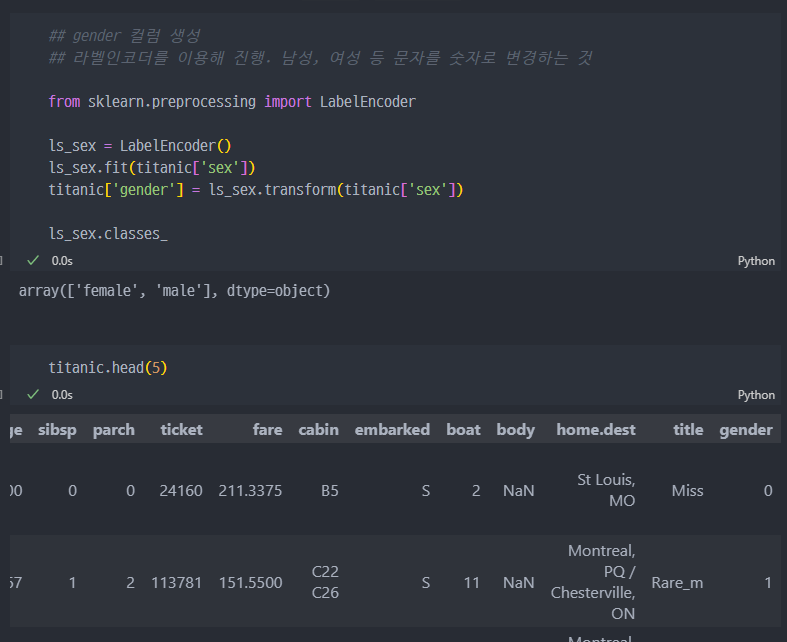
범주형 데이터: 예를 들어, 성별("남성", "여성")이나 국가("한국", "미국", "일본")와 같은 데이터는 범주형 데이터입니다.수치형 데이터: 머신 러닝 모델은 수치형 데이터를 필요로 하기 때문에, 범주형 데이터를 숫자로 변환해야 합니다.LabelEncoder: 범주형 데이터를 정수형으로 인코딩합니다. 예를 들어, "남성"을 0으로, "여성"을 1로 변환합니다.
gender컬럼과 동일하게labelEncoder를 이용해서grade컬럼 생성
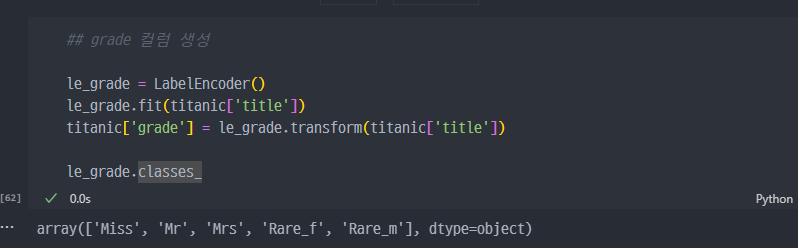
- Machine learning 진행 시 숫자로 이루어져 있어야하기 때문에, 각
feature컬럼들을 미리 숫자 형태로 변경하는 과정이다.
null데이터 제거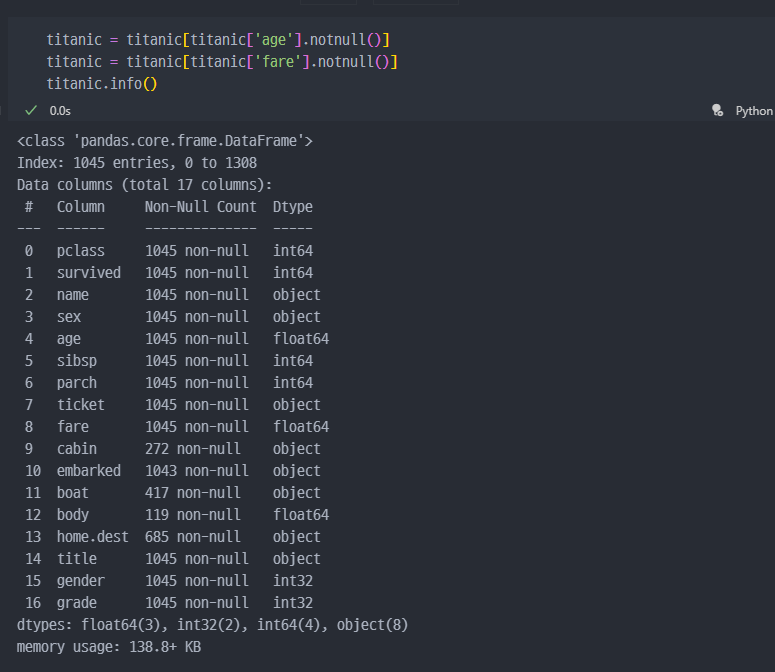

- 데이터 나누기 진행
PCA 진행
StandardScaler적용한 데이터와 적용하지 않는 데이터 두가지로PCA진행한다.
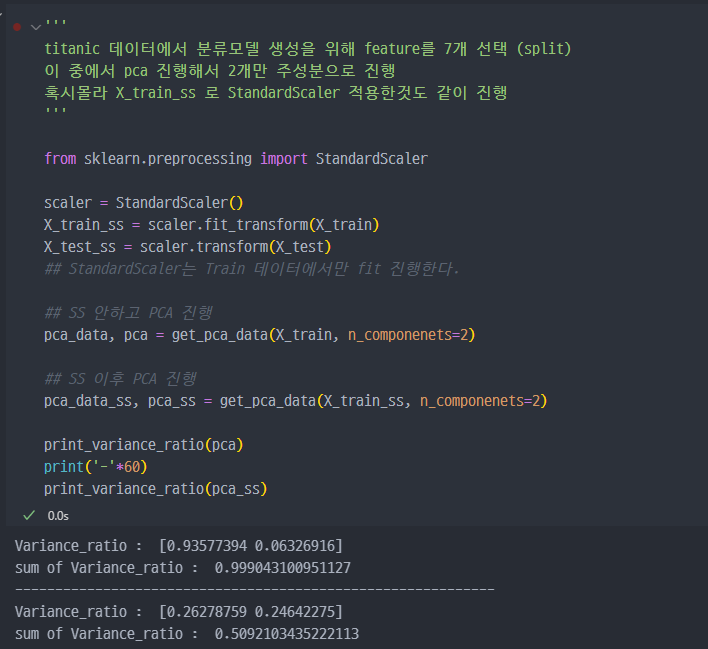
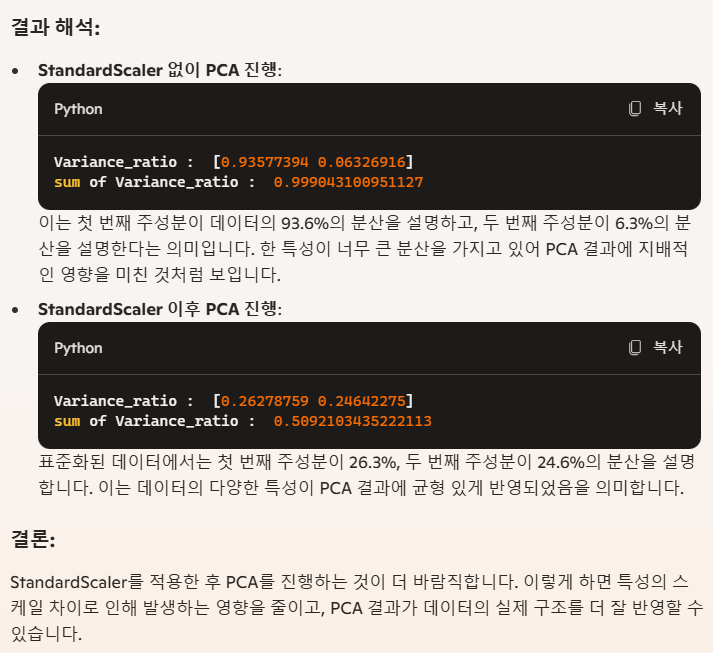
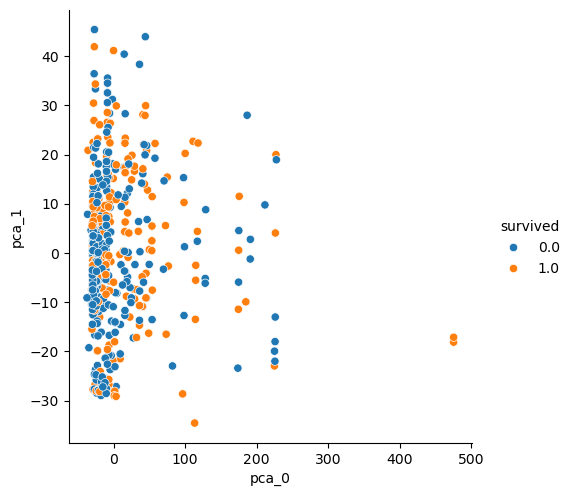
PCA된 데이터로 그래프를 그려보면...
먼저 StandardScaler 미적용 ver
다음 StandardScaler 적용 ver

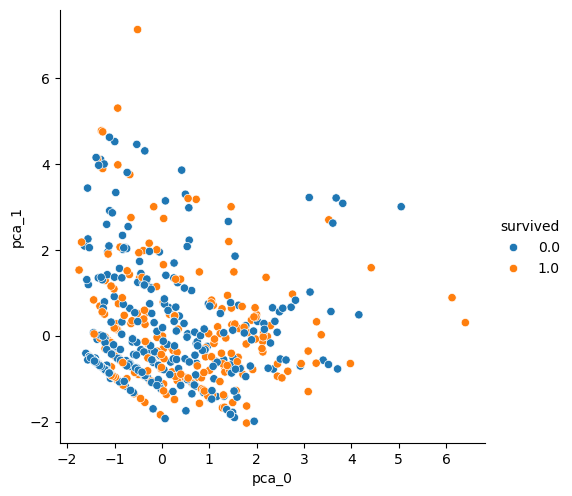
StandardScaler와 상관없이 둘 다 구분되지 않는다...
위 그래프 보면, 두 가지의 (1, 0)을 잘 구분할 수 있을지 잘 모르겠다. 물론 PCA를 두 가지 주성분만으로 진행했으므로 나타나는 결과지만, 일단 생각에는 구분이 잘 되지 않을것으로 보인다.
일단 kNN 으로 예측모델 생성해보자.
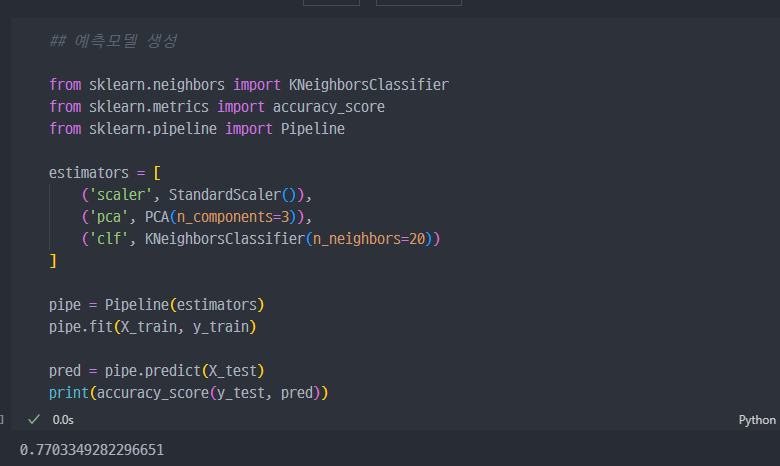
pipeline적용해서 순서대로...SS->pca->clf순서로 진행
acc_score가 그렇게 좋은 점수로 나온것 같지 않다.

(hellow. world)