
추천시스템 #1 : 영화추천 프로그램.
2024.12.10
딥러닝의 전단계..
추천시스템 - 이론
1. 콘텐츠 기반 필터링 추천 시스템
- 사용자가 특정한 아이템을 선호하는 경우, 그 아이템과 비슷한 아이템을 추천하는 방식
2. 최근접 이웃 협업 필터링
- 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측, 평가
- 사용자 기반 : 당신과 비슷한 고객들이 다음 상품도 구매했음.
- 아이템 기반 : 이 상품을 선택한 다른 고객들은 다음 상품도 구매했음.
일반적으로는 사용자 기반보다는 아이템 기반 협업 필터링이 정확도가 더 높음
- 비슷한 영화를 좋아한다고 취향이 비슷하다고 판단하기 어렵거나
- 매우 유명한 영화는 취향과 관계없이 관람하는 경우가 많고
- 사용자들이 평점을 매기지 않는 경우가 많기 때문.
3. 잠재 요인 협업 필터링
- 사용자 - 아이템 평점 행렬 데이터를 이용해서
잠재요인을 돌출하는 것 - 주 요인과 아이템에 대한
잠재요인에 대해 행렬분해 하고, 다시 행령곱을 통해 아직 평점을 부여하지 않은 아이템에 대한 예측 평점을 생성하는 것
실습.1 : 영화추천
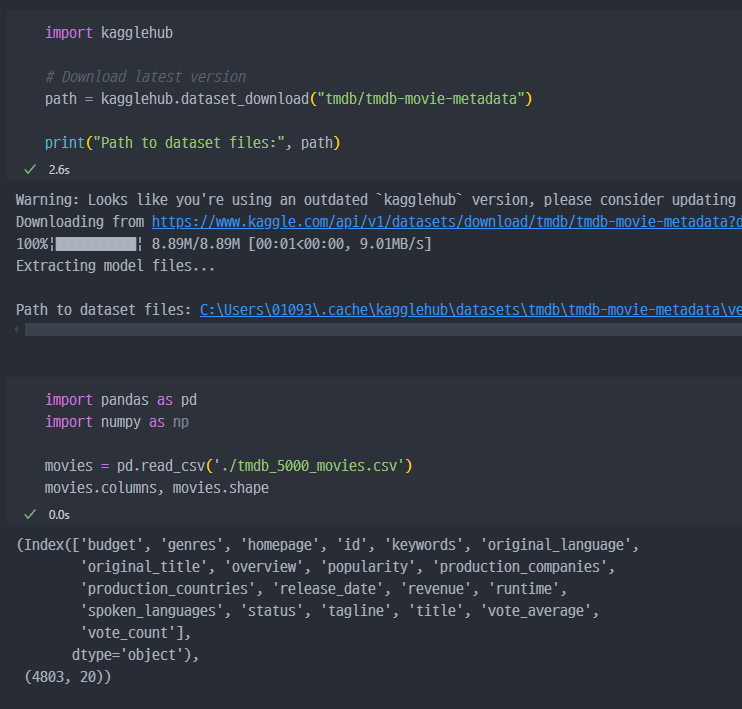
TMBD5000 영화 데이터 세트
kaggle에서 데이터셋 읽기
데이터 전처리
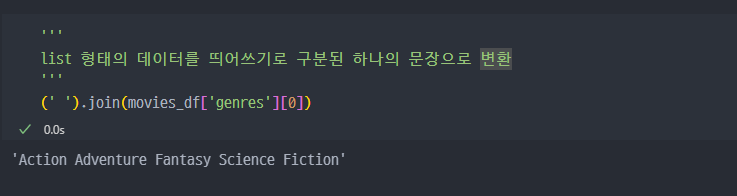
keyword컬럼과genres컬럼에 있는 데이터 형태가 이상하다.

dict 형태의 데이터가 뭉태기로 들어있는것처럼 보이지만, 사실
str형태로 들어있다.
해당 데이터에 대한 전처리 필요 ( ast 모듈/라이브러리 사용 )
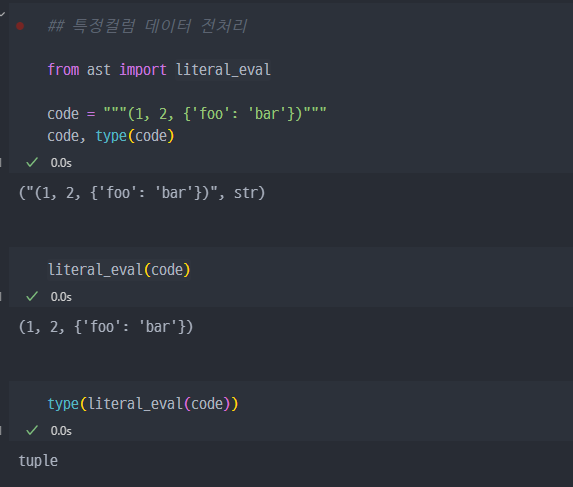
str로 저장되어 있지만, 그 안에 있는 어떠한 문자들이python에 적용되는 언어라면, 이를 변경한다.
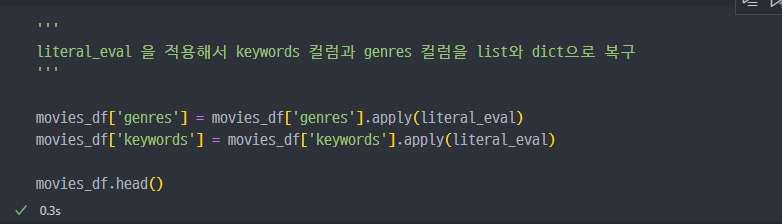
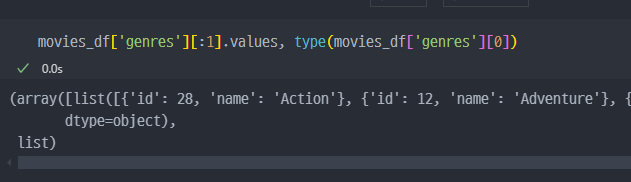
list로 변경된 것을 확인할 수 있음.
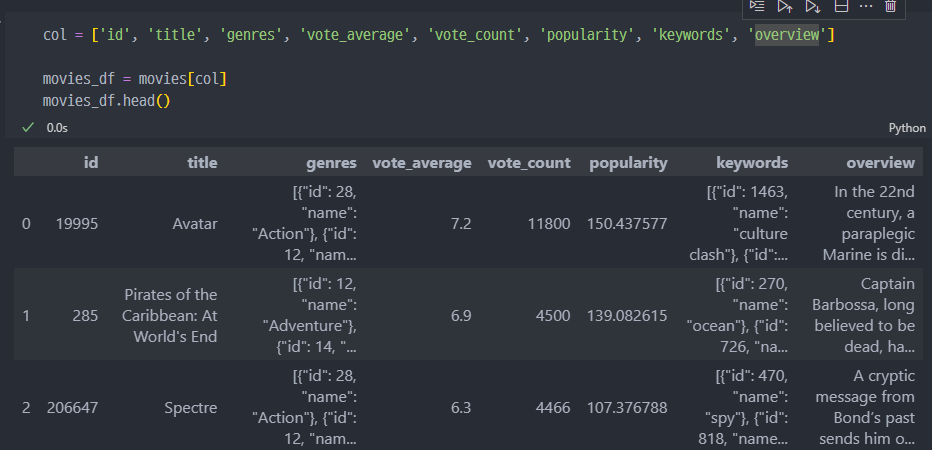
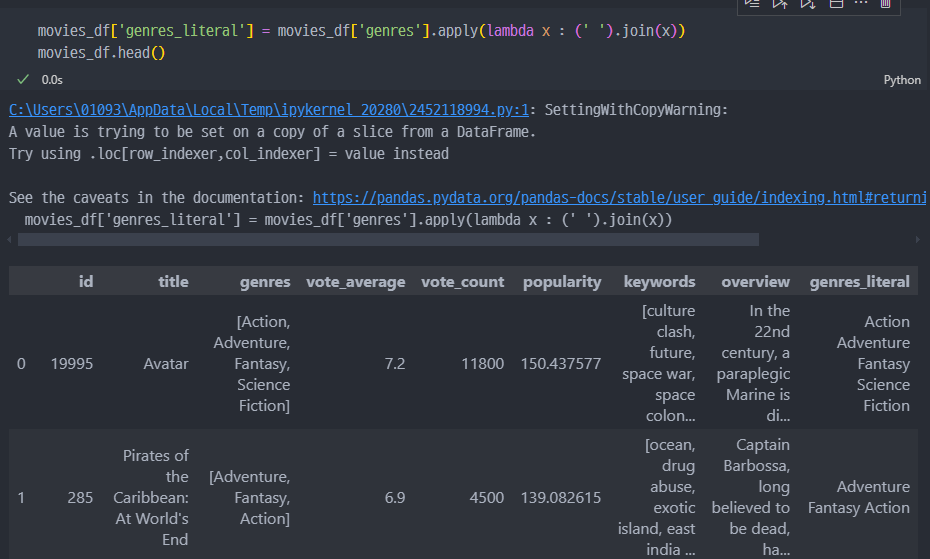
keywords, genres 컬럼값 변경
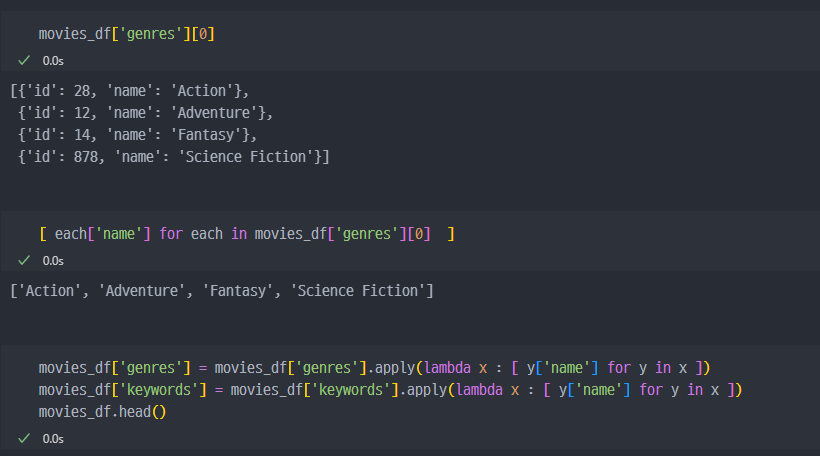
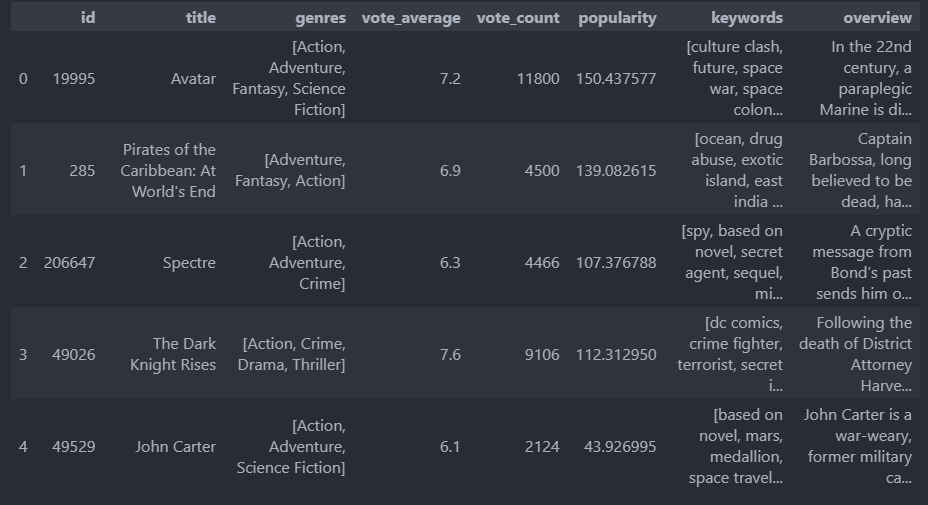
주요 컬럼 데이터 변환 (전처리)
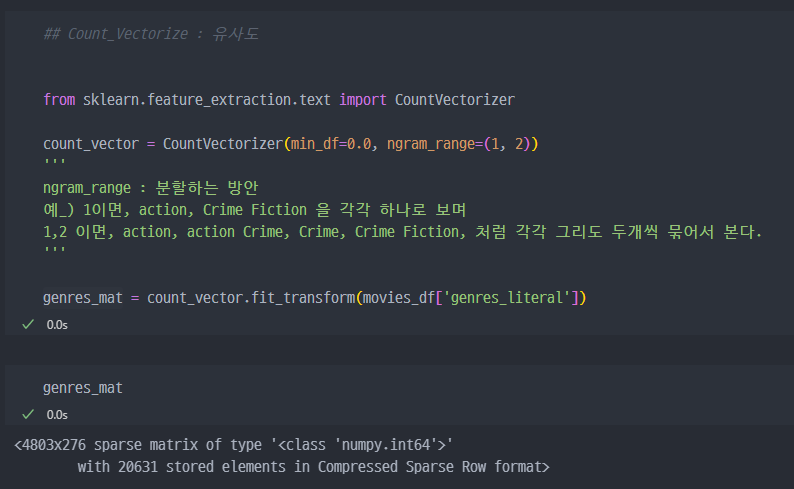
문자열로 변환된 genres를 CountVectorize 수행
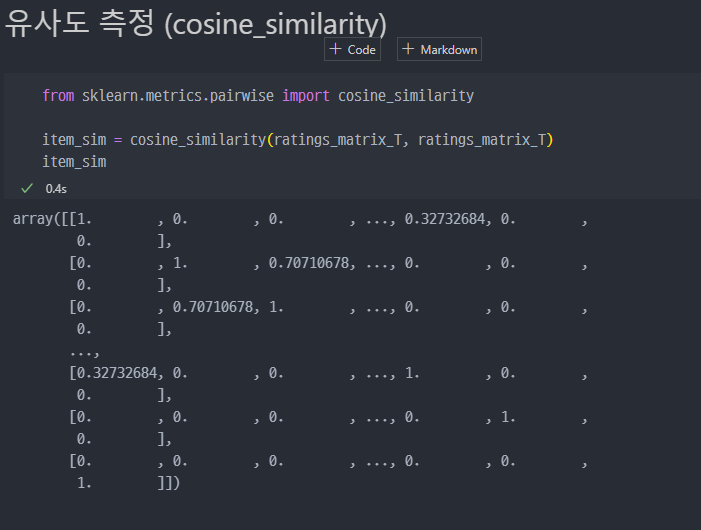
코사인 유사도 정보
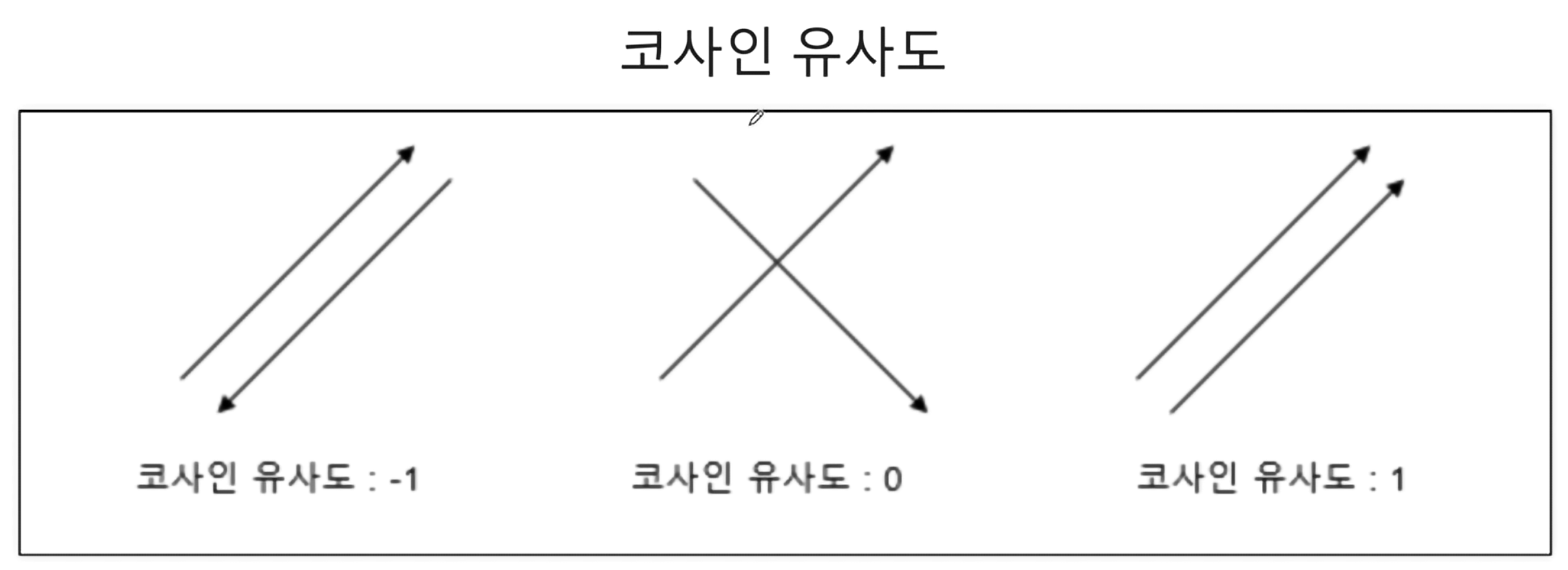
- 문장의 유사도 측정을 하는 방법 중 하나인 코사인 유사도 측정 수행

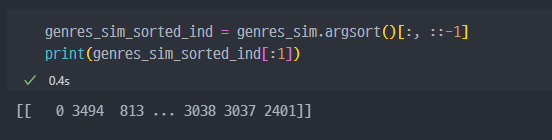
- 값이 높은 순서대로
sorting진행. 위 값들은 인덱스 값이다.
추천영화를 DataFrame으로 반환하는 함수
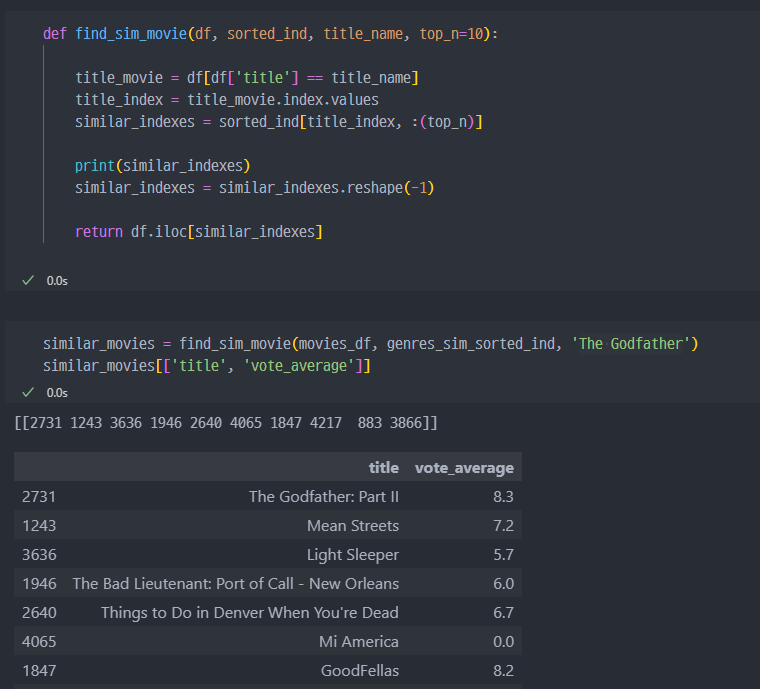
- 일단 코드를 보았을때, 장르 컬럼만 분석에 활용되고 그로인한 유사한 결과( 코사인 계산? )를 리턴하는 것 같다.
- 실제로 정말, 좋은 추천인지는 모르겠다.
영화추천을 하는 컬럼, 특성값에 대한 가중치

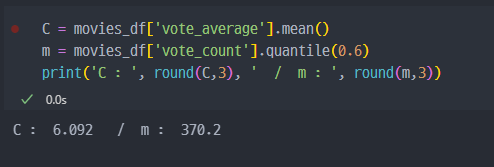
C :
vote_average의 전체 평균
m :vote_count의 60% 지점
- 가중치 식 적용

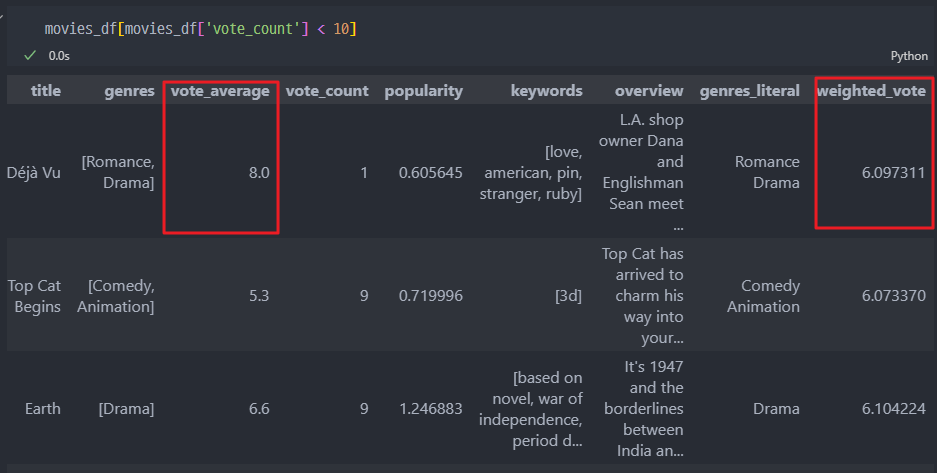
가중치 적용한 평점의 결과
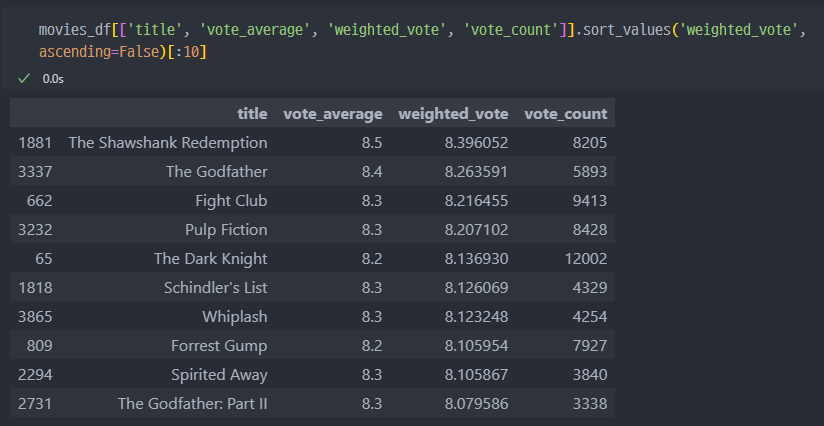
vote_average와vote_count개수가 어느정도 보증되는 영화들로 선별할 수 있다.

아이템 기반 최근접 이웃 협업 필터링
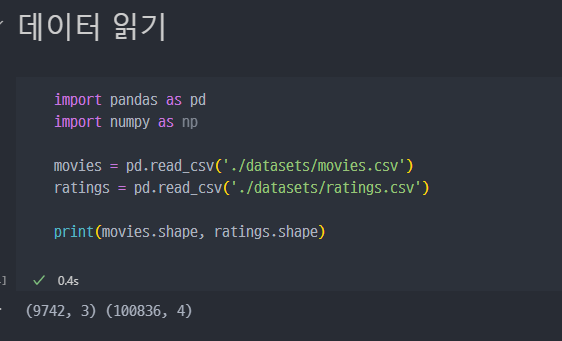
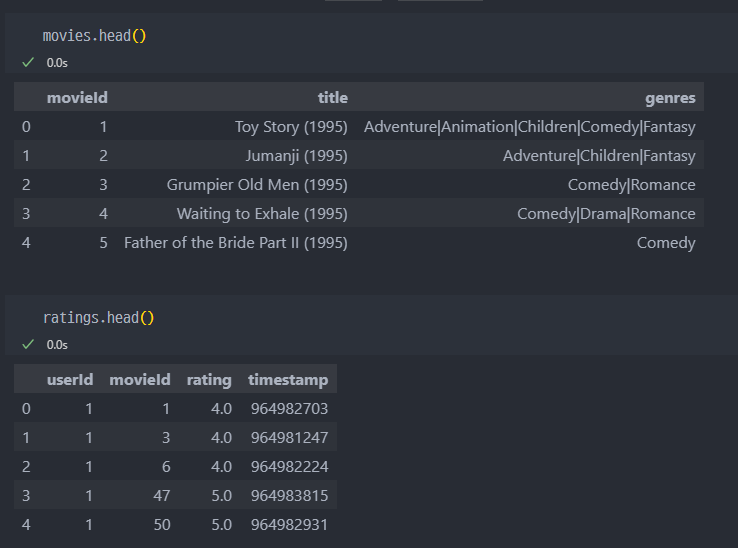
데이터 읽기
영화의 평점을 매긴 사용자와 영화 평점 행렬 등의 데이터
grouplens 홈페이지
raw data 변경
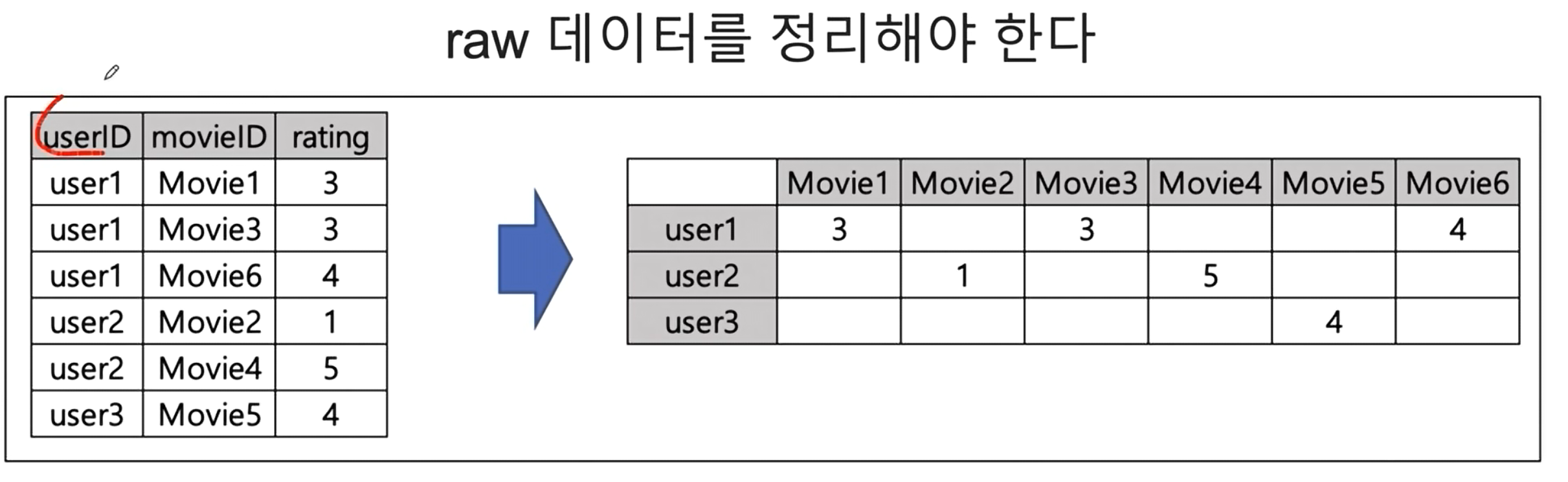
위 처럼 데이터를 변경해야 계산하기 편할 것 같다. 피벗테이블을 이용해서 변경한다
- 피벗테이블
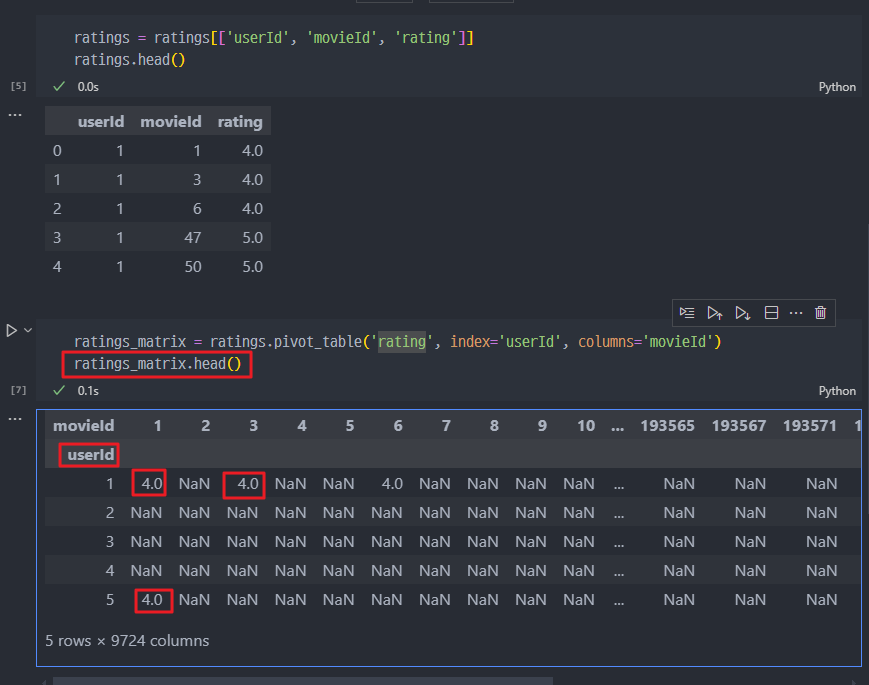
-
ratings와movies데이터를movieId컬럼 기준으로 결합
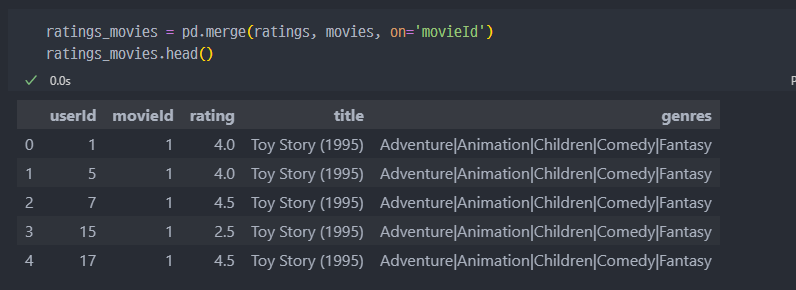
- 다시 피벗테이블 이용해서 정리
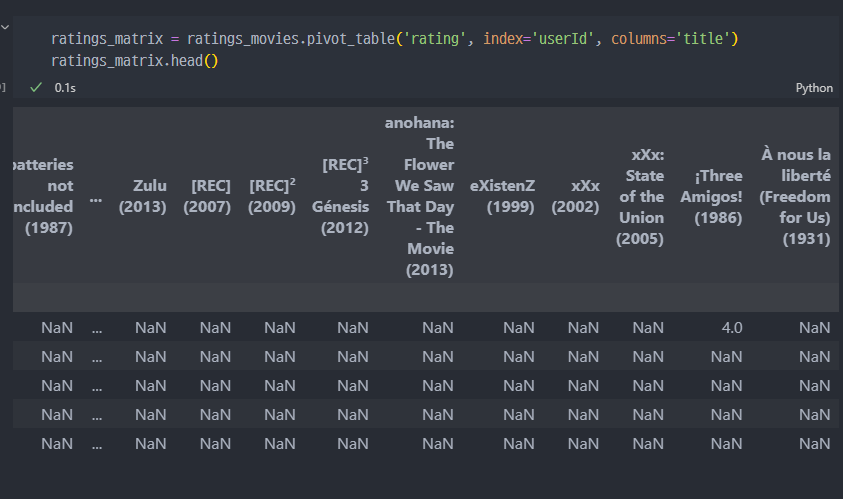
- NaN을 0으로 변경 (fillna() 함수 사용)

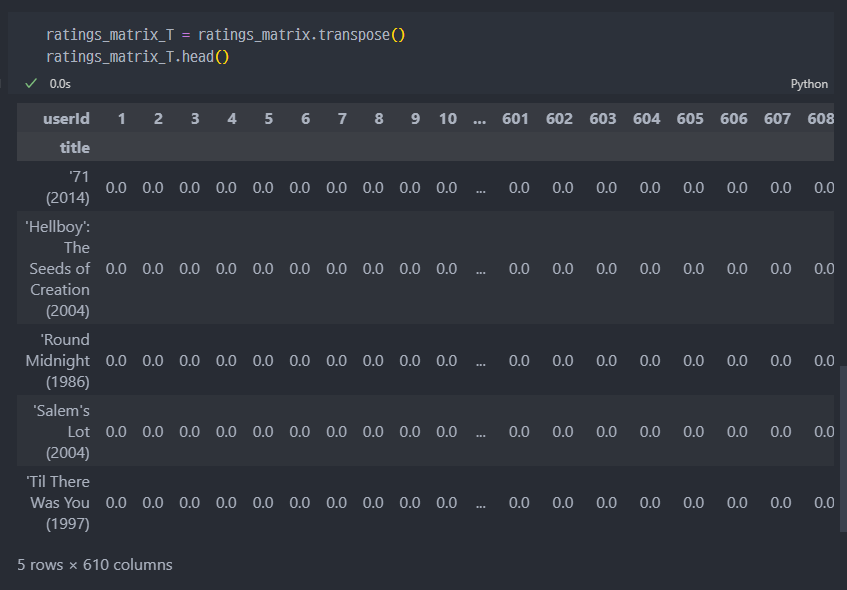
- 유사도 측정을 위해 행렬의
transpose진행
cosine_similarity 진행 (유사도 측정)
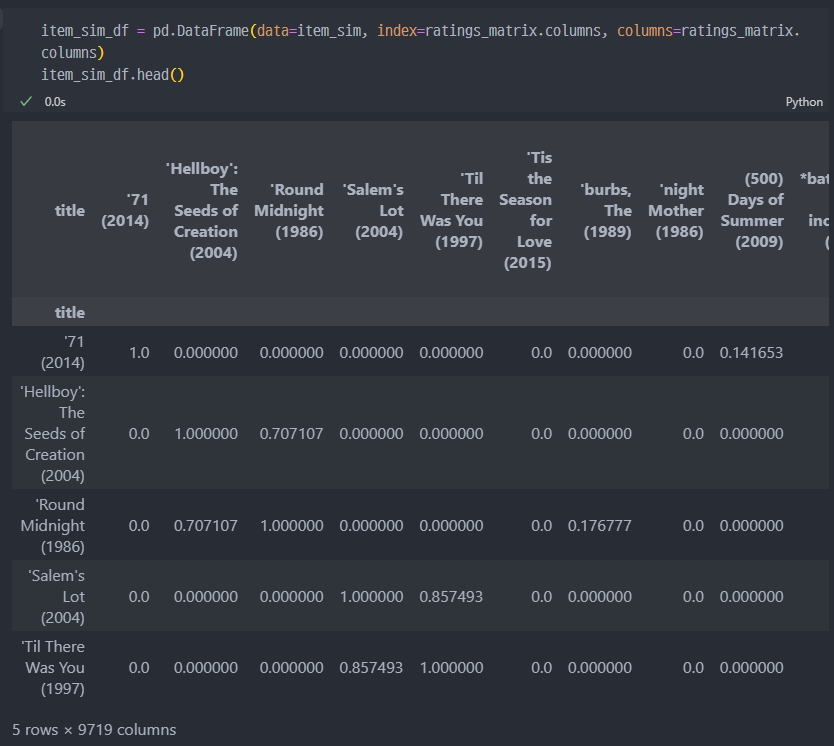
유사한 영화 확인


(hellow. world)