
2024.12.14
Good Books Recommendations
Good Books Recommendation
데이터 읽기
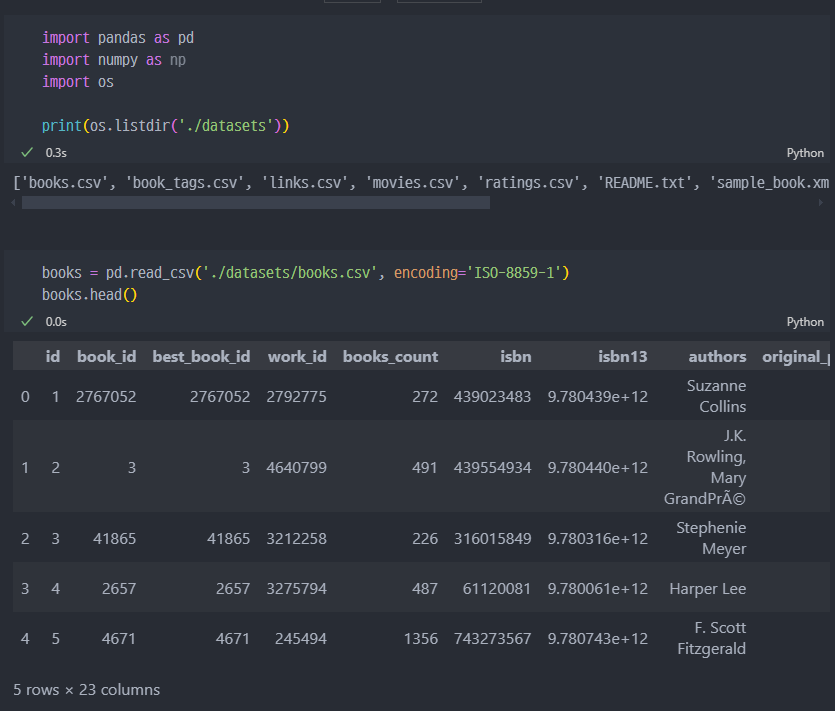
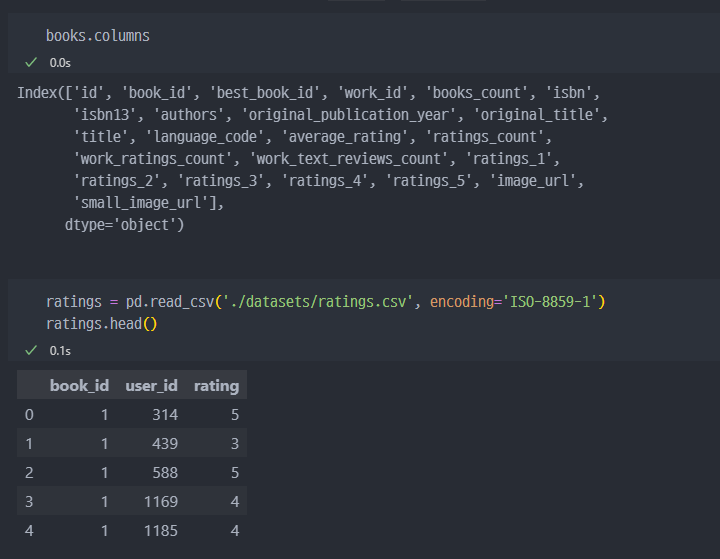
kaggle을 통해서 데이터 load 진행- books.csv 파일과 ratings.csv 파일, bokk_tag.csv 등
read진행- 각 컬럼, 데이터 구조 파악
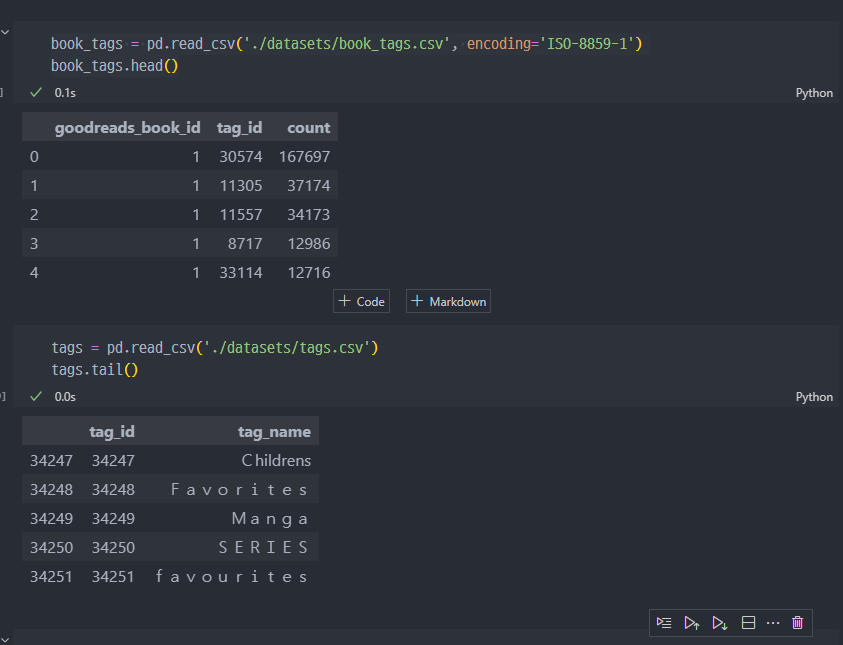
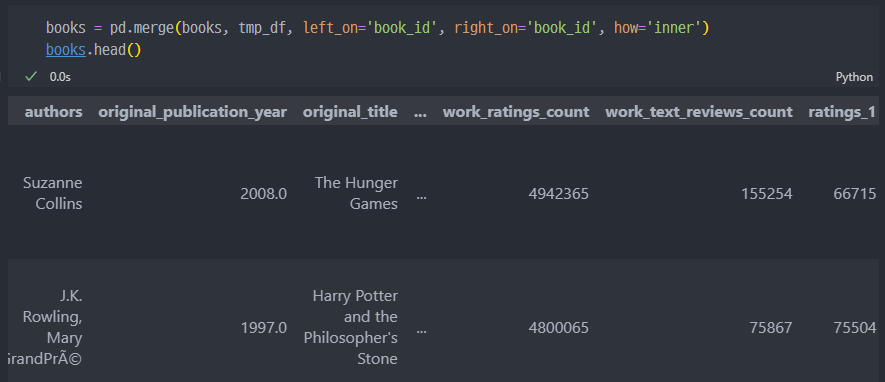
데이터 merge
book_tag와tag데이터 merge 진행
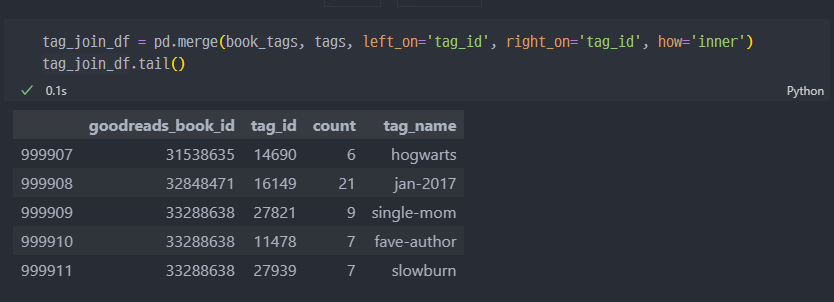
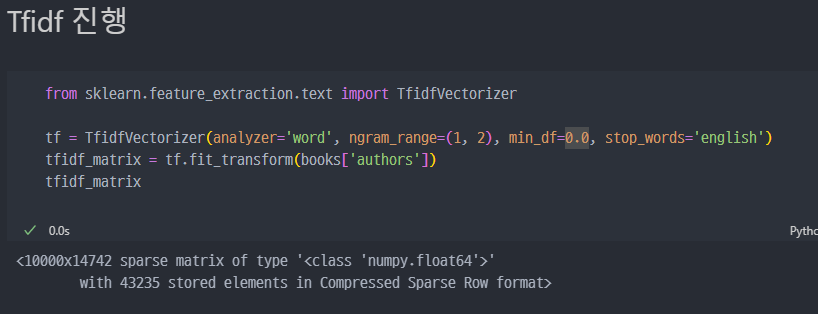
Tfidf Vectorizer 진행 (author 컬럼)
- 남아있는 데이터 확인
작가 이름(authors)으로만 진행.
- 코드해설
TfidfVectorizer는 텍스트 데이터를 TF-IDF(Term Frequency-Inverse Document Frequency) 방식으로 벡터화하는 도구
analyzer: 텍스트를 분석할 단위를 설정합니다. 기본값은 'word'로 단어 단위로 분석합니다.ngram_range: n-gram의 범위를 지정합니다. 예를 들어, (1, 2)는 1-gram(단어)과 2-gram(두 단어의 조합) 모두를 사용합니다.min_df: 문서에서 최소 빈도로 나타나야 하는 용어의 비율을 지정합니다. 여기서는 0.0으로 설정하여 모든 용어를 포함합니다.stop_words: 불용어를 제거합니다. 'english'로 설정하여 영어 불용어를 제거합니다.
F-IDF 설명
TF (Term Frequency): 특정 용어가 문서에서 나타나는 빈도입니다.IDF (Inverse Document Frequency): 용어가 전체 문서에서 얼마나 희귀한지를 측정하는 값입니다.
TF-IDF 값은 특정 문서에서 자주 등장하지만, 전체 문서에서는 드문 단어들에 높은 가중치를 부여합니다.
유사도 측정
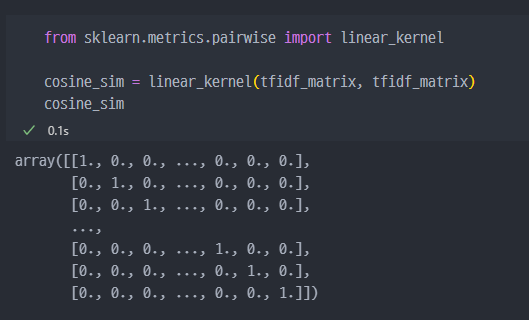
- 참고
Cosine Similarity
cosine_similarity는 두 벡터의 코사인 유사도를 계산합니다. 벡터가 이루는 각도에 기반하여 유사도를 측정하므로, 벡터의 크기보다는 방향이 중요한 경우에 유용합니다. 코사인 유사도는 -1에서 1 사이의 값을 가지며, 1에 가까울수록 두 벡터의 방향이 비슷하다는 것을 의미합니다.
Linear Kernel
linear_kernel은 주로 선형 커널을 사용한 SVM(Support Vector Machine)이나 다른 커널 기반 머신러닝 알고리즘에서 사용됩니다. 선형 커널은 두 벡터의 내적(dot product)으로 계산되며, 이는 벡터의 크기와 방향을 모두 고려합니다. 결과적으로 벡터 간의 유사도를 선형적으로 계산할 때 유용합니다.
주요 차이점 요약
- 코사인 유사도는 벡터 간의 각도를 기반으로 유사도를 측정하여 크기보다는 방향이 중요한 경우에 적합합니다.
- 선형 커널은 벡터의 내적을 기반으로 유사도를 측정하여 크기와 방향을 모두 고려합니다. 주로 SVM과 같은 커널 기반 머신러닝 알고리즘에서 사용됩니다.
유사도가 있는 친구들 찾기
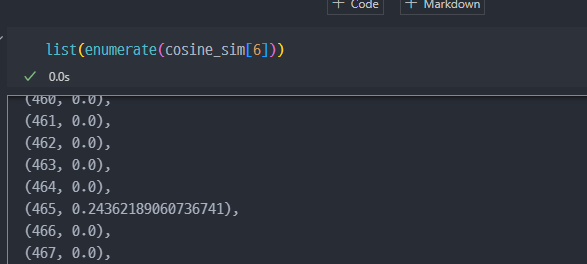
가장 유사한 책의 인덱스
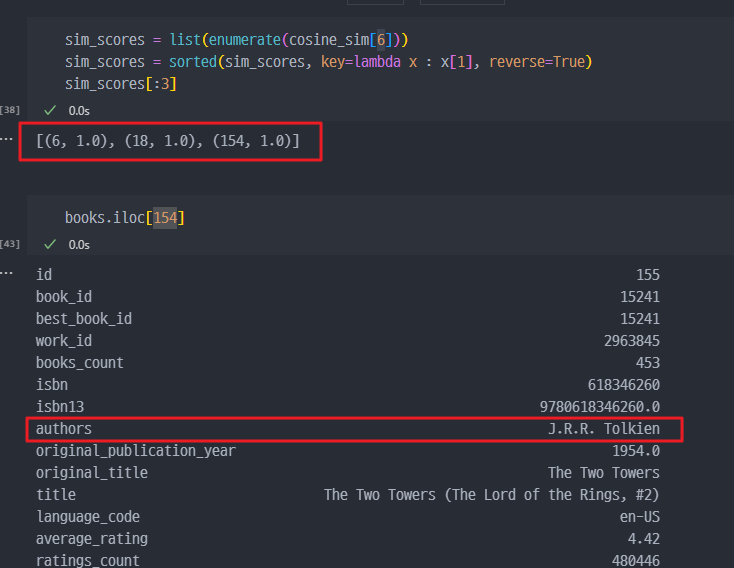
세가지 출력된 인덱스를 검색하면, 모두 같은 작가가 작성한 책이 검색된다.

Tfidf Vectorizer 진행 (tag 컬럼)
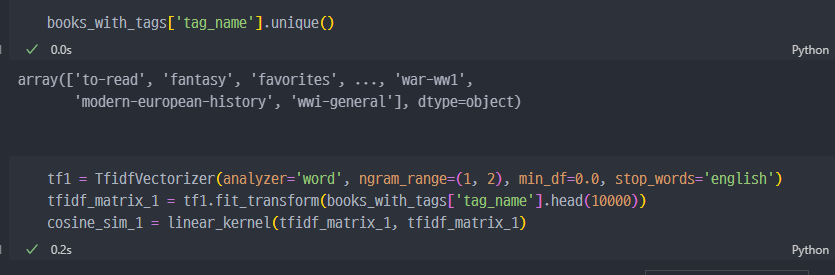
앞선 분석에서는
author컬럼에 대해서만 분석하여 진행하였다. 이번에는tag_name컬럼에 대해서 진행한다.
추천책을 반환하는 함수 ( tag_name 컬럼 분석값을 이용해서)


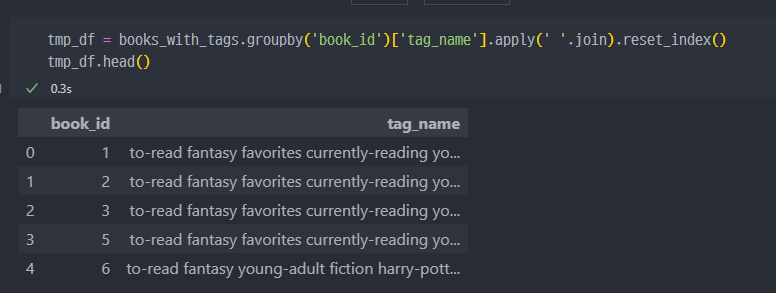
book_id 기준으로 tag_name 추가
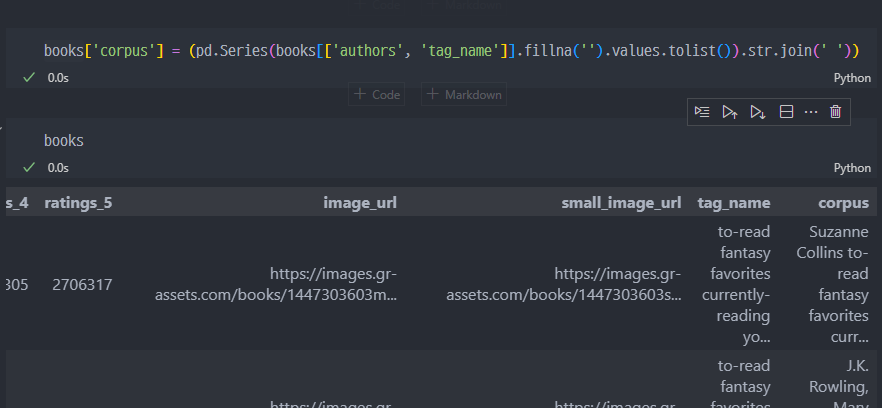
새로만든 corpus 컬럼으로 tfidf 진행
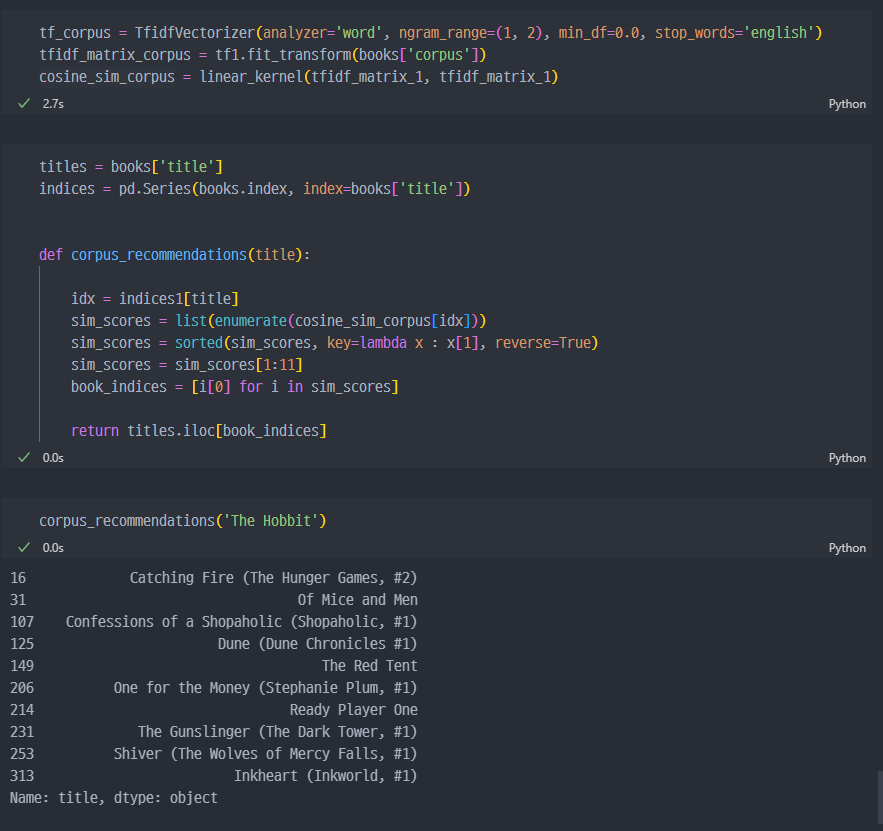
추천시스템이란 건 정답이 있는게 아니다. 어떤 컬럼으로 분석을 진행해서(유사도) 보여줄지를 선정하는것을 고민해야 한다.
