실무를 할 때 귀찮은 부분 중 하나이며, 간과되기도 하는 validation set이 필요한 이유를 알아보자
https://m.blog.naver.com/ckdgus1433/221587105470 참고
모델 검증(Model Validation)

우리가 얻을 수 있는 data의 종류는 크게 시계열, 이미지, 정형(Table)로 나뉘는 것이 일반적이다. 이 중 직관적으로 이해하기 쉬운 정형 데이터를 예로 들어보자.
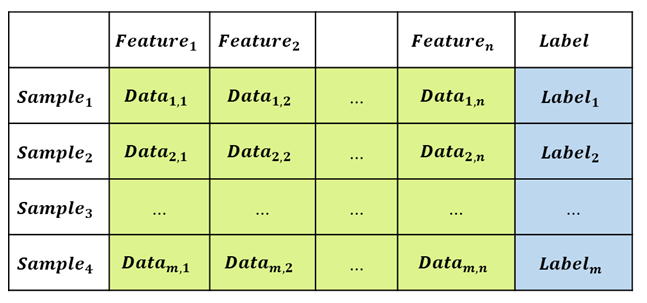
연두색으로 표시된 부분이 실제 우리가 취득한 Data이고, 하늘색으로 표시된 부분이 해당 Data의 정답 Label 이다. 테이블에 표시된 한 row가 하나의 Sample point이고, 각 sample은 여러가지 feature들을 갖는다.

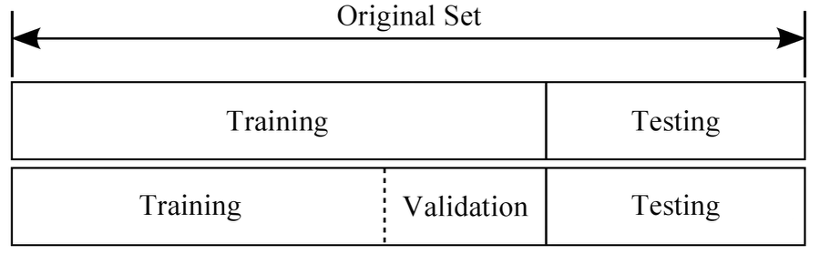
데이터들은 위 처럼 Train data와 Test data로 나뉜다. Train data set은 모델을 훈련할 때 사용하고, Test data set은 모델의 최종 성능을 평가할 때 사용한다.
사실 여기에는 한가지 가정이 있는데, Test set에 label이 존재한다는 것이다. 만일 test set에 label이 없다면, 우리는 당연히 모델의 최종 성능을 평가할 수 없다.
자, 그럼 두가지 경우로 나누어서 아래와 같은 상황을 한번 생각해보자.


첫번째 이미지와 같이 test set에 label이 없는 경우 (a), test set에 label이 있는 경우 (b) 가 있다.
만약, (a)와 같은 데이터가 주어졌을 때, 내 모델이 잘 훈련되었는지 아닌지, 잘 예측하는지 아닌지를 어떻게 검증할 수 있을까? 이때 필요한 것이 바로 validation set이다. 만약 validation set이 없다면, 우리는 훈련된 모델의 파라미터가 최적화 되어있는지 알지도 못한 채 실제 시스템에 적용해야 하는 상황을 마주하게 된다. (test set을 통해 predict)
이를 극복하기 위해서, 갖고 있는 train set에서 일부를 쪼개 validation set으로 할당한다. 물론 모델을 훈련시키는데 사용되는 데이터 샘플의 수는 줄어들겠지만, validation을 통한 파라미터 튜닝으로 좀 더 일반화된 모델을 얻을 수 있다.
(하지만 이 희생을 감수하지 못할만큼 data set의 크기가 작다면 cross-validation이라는 방법을 쓰기도 한다.)


(b) 처럼 구성된 데이터를 이용할때에도 마찬가지로 train set에서 일부를 쪼개어 validation set으로 할당한다.
이쯤에서 의문점 하나가 생기는데, "test set에 label이 있는데 왜 또 따로 validation set을 만들까?" 라는 것이다.
validation set은 trian set으로 훈련된 모델의 하이퍼 파라미터(Hyper parameter) "튜닝" 에 사용한다.
다시말해, validation set은 파라미터 설정 -> 모델의 성능 검증 -> 파라미터 수정을 통한 방법으로 모델의 훈련 과정에 관여한다.
하지만, test set은 튜닝된 최종 모델의 최종 성능이 어느정도인지를 검증할 때만 사용함으로써 모델의 훈련과정에 관여하지 않는다.
따라서, label이 있는 test set으로 모델의 성능을 검증하고, 다시 모델의 파라미터 튜닝 작업을 거친다면 이것은 test set이 아니라 또 다른 validation set인 것이다.
모델의 성능을 검증하는 것에 중요성은, 첫번째로 test accuracy를 가늠해 볼 수 있다. 머신러닝의 목적은 결국 unseen data 즉, test data에 대해 좋은 성능을 내는 것인데, 그러므로 모델을 만든 후 이 모델이 unseen data에 대해 얼마나 잘 동작할지에 대해서 반드시 확인이 필요하다. 하지만 training data를 사용해 평가하면 안되기 때문에 따로 validation set을 만들어 정확도를 측정하는 것이다.
두번째는 파라미터 튜닝을 통해 모델의 성능을 높일 수 있다. 예를 들어, overfitting 등을 막을 수 있다. 만약 training accuracy는 높은데 validation accuracy는 낮다면, 데이터가 training set에 overfitting이 일어났을 가능성을 생각해볼 수 있다. 이런 경우에는 overfitting을 막아서 training accuracy를 희생하더라도 validation accuracy와 training accuracy를 비슷하게 맞춰 줄 필요가 있다. (딥 러닝 모델을 구축한다면 regularization 과정을 한다거나 epoch을 줄이는 등의 방식으로..)
validation set은 모델의 파라미터를 수정할 때 사용하는 것이고, test set은 수정된 모델의 최종 성능을 평가하기 위해 사용된다는 점이 핵심이다.
<요약>
- label이 있는 test set도 있고, label이 없는 test set도 있다. 이는 최종 성능을 검증할 수 있는지의 여부와 직결된다.
- validation set은 모델의 파라미터를 수정할 때 사용하는 것이고, 모델의 훈련과정에 관여한다.
- test set은 모델의 최종 성능을 평가할 때 사용하는 것이고, 모델의 훈련과정에 관여하지 않는다.
