우리가 이전에 알아봤던 Linear Regression은 입력에 대해서 연속적인 출력값을 예측해서 분류 문제(0 또는 1, class가 2개 이상이어도 됨)에는 부적합하다.
그럼 분류 문제는 어떻게 풀까?
먼저, threshold를 설정해서 threshold값보다 작으면 0, 크면 1을 주는 형식으로 해결할 수 있다.
그리고, Decision boundary를 구하는 방법이 있는데 차근차근 알아보자.
Logistic Regression
분류 문제를 위해 사용되는 모델 중 하나는 Logistic Regression이 있다.
Logisitic Regression을 알아보기 전, Sigmoid Function에 대해서 살펴보자.(이게 뭔데;)
Sigmoid Function
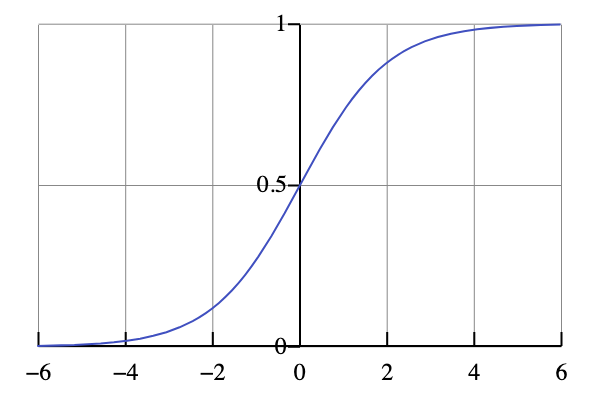
위에 보이는 그림은 sigmoid function을 나타내는 그래프 이다.
보이는 것처럼 output(y)는 0~1사이의 값으로 국한된다.
수식적으로는,
f(x)=1+e−x1
로 나타낼 수 있다.
(Logistic regression에서 사용되어서인지, Logistic Function이라고 부르기도 한다고 함.)
그럼 sigmoid function은 어디서 어떻게 사용되는 걸까?
일단 우리가 알던 식을 복기해보면
fw,b(x)=z=w⋅x+b
이러한 식이 나왔었다.
하지만 이 식은 위에서 말했던 것처럼 연속적인 출력값 즉, class들로만 국한되지 않는다.
그래서 우리는, z에 sigmoid function을 입혀서 출력이 0~1 사이로 국한되도록 해준다.
sigmoid(z)=1+e−z1=1+e−(w⋅x+b)1
로 나타낼 수 있고, 이렇게 되면 이제 output은 [0,1]값으로 국한되는 것이다.
그리고 이렇게 마지막에 sigmoid function을 넣어준 것을 Logistic Model이라고 한다.
Ex) x: 종양 크기, y: 0(종양 아님), 1(종양)
fw,b(x)=0.7(이 말은, 70퍼센트로 종양이라는 말이다.)
이 식을 보면 fw,b(x)=P(y=1∣x,w,b)
라고 볼 수 있다. 풀어서 말하면, vector x, vector w, b가 주어졌을 때 y가 1일 확률을 구하는 거와 동일하다는 것이다.
Decision Boundary
그럼 위의 값이 결국 0이냐 1이냐는 어떻게 파악할 것인가. 이걸 위해 결국 우리는 threshold가 필요한 것이다.
threshold 이상이면 1이고, 보다 작으면 0으로 판단한다는 것이다.
여기서 threshold를 통해서 우린 decision boundary를 구할 수 있는데,
바로 fw,b(x)=threshold 인 이 값이 바로 Decision Boundary가 되는 것이다.
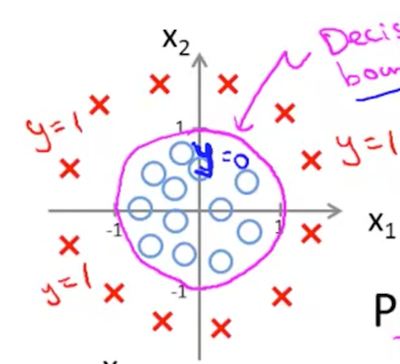
(이 그림에서는 threshold값이 0임을 파악할 수 있다.)
Logistic Regression에서는 보통 threshold값으로 0.5를 많이 지정한다.
Non-linear decision boundary
여기에 추가로 linear하지 않은 Polynomial logistic regression에 대해서 decsion boundary가 존재한다.
Ex) fw1,w2,b(x)=w1x12+w2x22+b
이 식의 threshold 값을 0이라고 하고, w1=1,w2=1,b=−1이라고 했을 때 z=x12+x22−1=0 이라는 식이 나오고, 이건 반지름이 1이고 중심이 (0,0)인 원이 decision boundary가 된다는 말이다.
Cost Function for logistic regression
자 이제 Logistic Regression의 cost function(비용 함수)에 대해서 알아보자.
i=1,...,m: m개의 학습 데이터
j=1,...,n: n개의 feature들
항상 우리가 궁금해하는 것은 fw,b(x)=1+e−(w⋅x+b)1 에서 w와 b를 어떻게 구할 것인지이다.
사실 우리가 이전에 봤던, linear regression과 별반 다르지 않지만, cost function의 형태가 다르다.
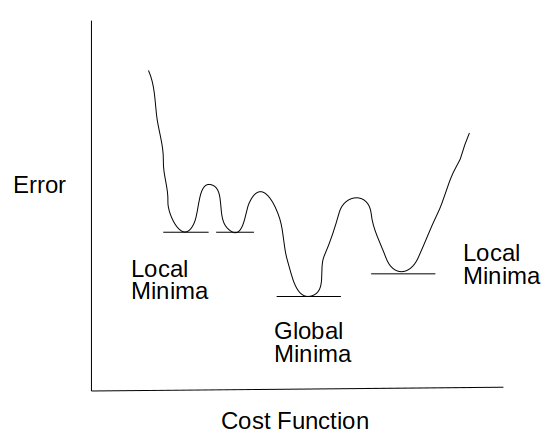
Linear Regression model에서는 Mean-squared Error를 사용하였지만 이 함수는 logistic regression model에서는 제대로 작동하지 않는다.
위의 그림과 같이 cost function이 convex하지 않게 된다. 그래서 Local minimal에 빠질 가능성이 높다.
그래서 대신 사용할 surrogate(대리) loss를 선택해야한다.
Logistic Regression에 대해서 우리는 log loss를 가져온다.(예측 확률이 실제 정답과 얼마나 일치하는 지를 측정하고, 예측이 실제와 멀어질 수록 더 큰 패널티를 부여한다고 함. 게다가 convex하다.)
L(fw,b(x(i)),y(i))
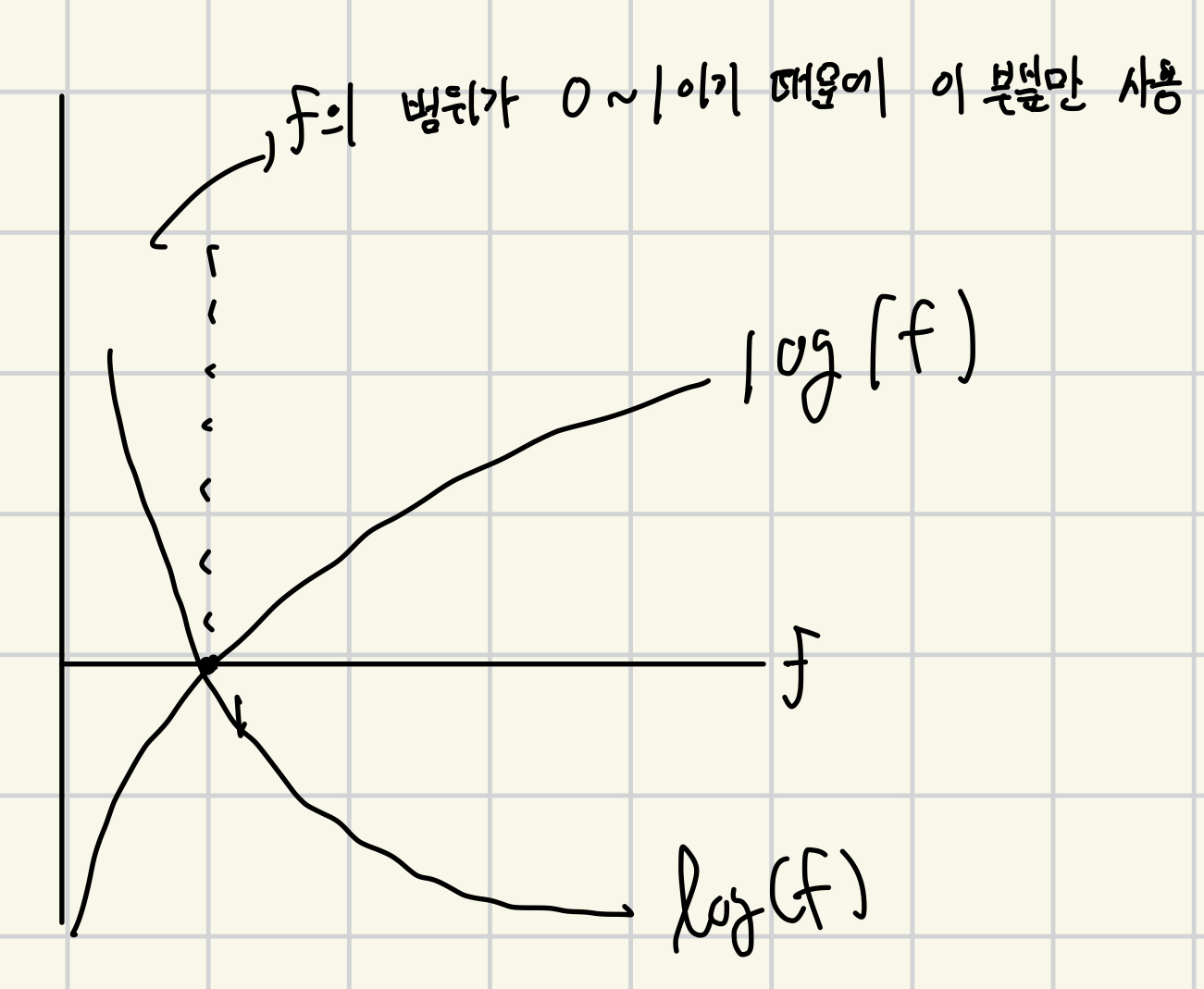
−log(fw,b(x(i))), if y(i)=1
−log(1−fw,b(x(i))), if y(i)=0
이러한 손실함수 식으로 만들면 논리적으로도 맞고, convex하게 된다.
(아래 log(f)가 -log(f)임.)
고로, 보이는 것 처럼 y가 1이면 f(x)가 1로 이동하여 손실함수의 값은 0에 가까워지고, y가 0이면 f(x)가 0으로 이동하여 총 손실함수는 다시 0에 가까워진다.