이번 강의 에서는 Machine Learning 개념에서 다양하게 사용되는 기법들에 대해서 소개해준다.
먼저 신경망(Neural Network)에 대해서 설명해준다.
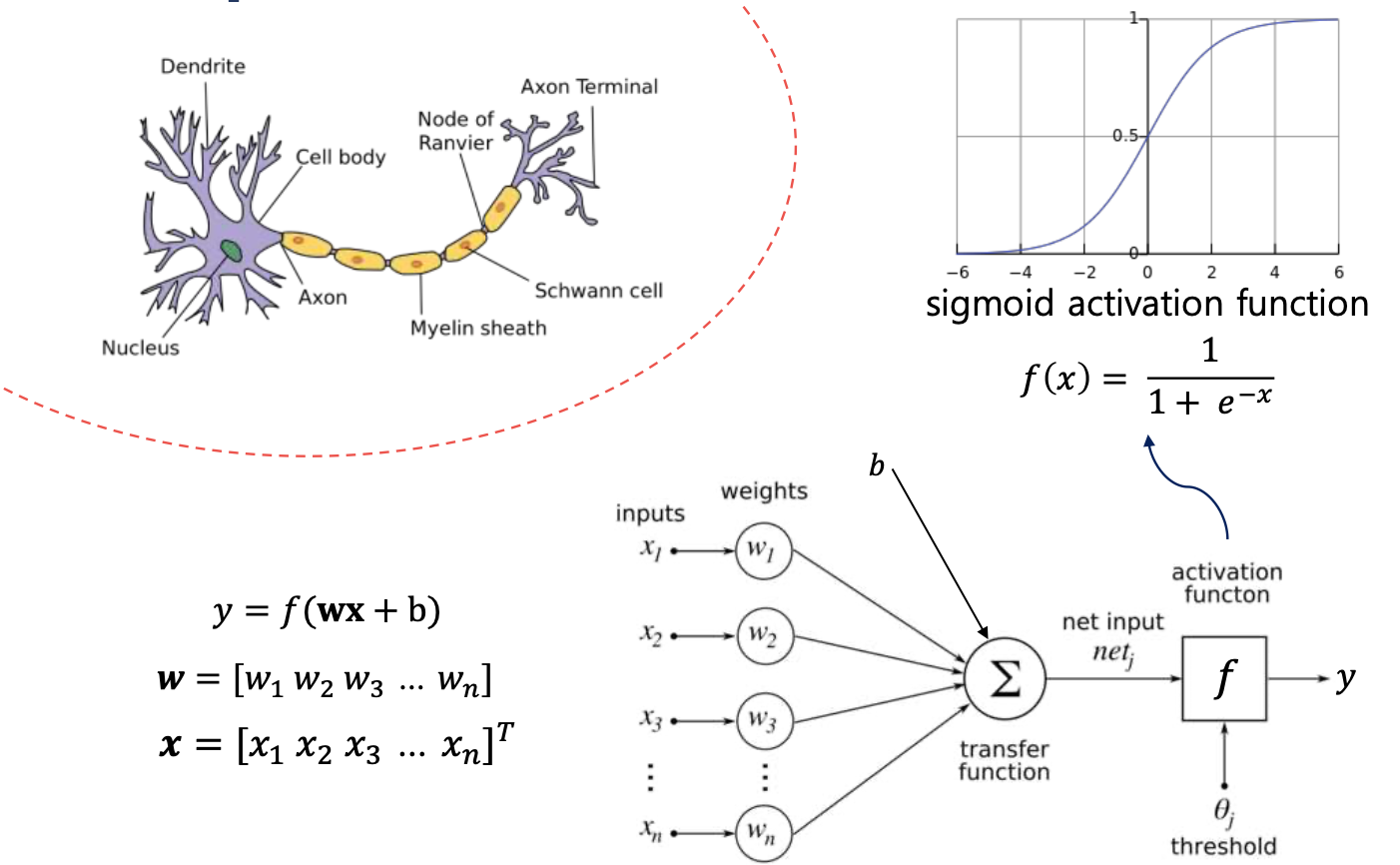
신경망을 간단하게 말하면, 그냥 우리의 뇌에서 신호를 전달하는 과정을 코드로 옮겨놓은 것이라고 볼 수 있다.
예를 들어, 우리의 뇌에서 뇌 세포가 임계치 이상의 신호를 받으면 다음 뉴런으로 보내는 것 처럼 코드에서도 이렇게 할 수 있도록 하는 것이다.
강의에서는 티셔츠 판매량 예측에 대한 예시를 드는데,
입력으로 가격, 배송비, 마케팅, 품질을 입력했을 때, top seller가 될 수 있는 확률을 구한다.
이럴 경우, 각 입력에 맞는 뉴런에 연결해서 그 뉴런에서 값을 뽑아내고 그 값을 sigmoid함수를 이용해 0~1 사이 즉 확률값으로 바꿔준다.
하지만, 이런 식으로 각 입력에 어떤 뉴런이 적합한 지에 대하여 사람이 직접 설정해주는 데에는 무리가 있다.
이러한 경우는 그럼 어떻게 해야할까? 간단하게도 일단은 모든 입력값을 각 뉴런에 전부 연결하고 어떤 입력이 각 뉴런에 대해서 얼만큼 영향을 미쳐야하는 지를 학습하면 된다.
이걸 위해서 각 입력에 가중치를 두어서 어떤 건 큰 영향을 주고 어떤 건 작은 영향을 주도록 한다.
이러한 입력값들이 있는 계층을 input layer라고 말한다.
- (input layer)
이런 식으로, 각 계층에서는 벡터를 입력으로 받고 다음 계층으로 벡터의 입력을 준다. 그렇게 해서 마지막 output layer에서는 우리가 원하는 값을 얻기 위한 activation function을 사용해 값을 얻는다. 그렇게 해서 결국, neural network는 input layer, hidden layer, output layer이렇게 나뉜다.
어떻게 보면, Logistic regression model과 neural network는 hidden layer의 차이라고 볼 수 있을 것 같다. => hidden layer가 없으면 Logistic regression인 거임.
Ex. image에서는 각각의 픿ㄹ의 값들이 하나의 feature 값으로 동작할 수 있는 거임.
Neural network layer
좀 더 깊게 neural network를 들여다보면,
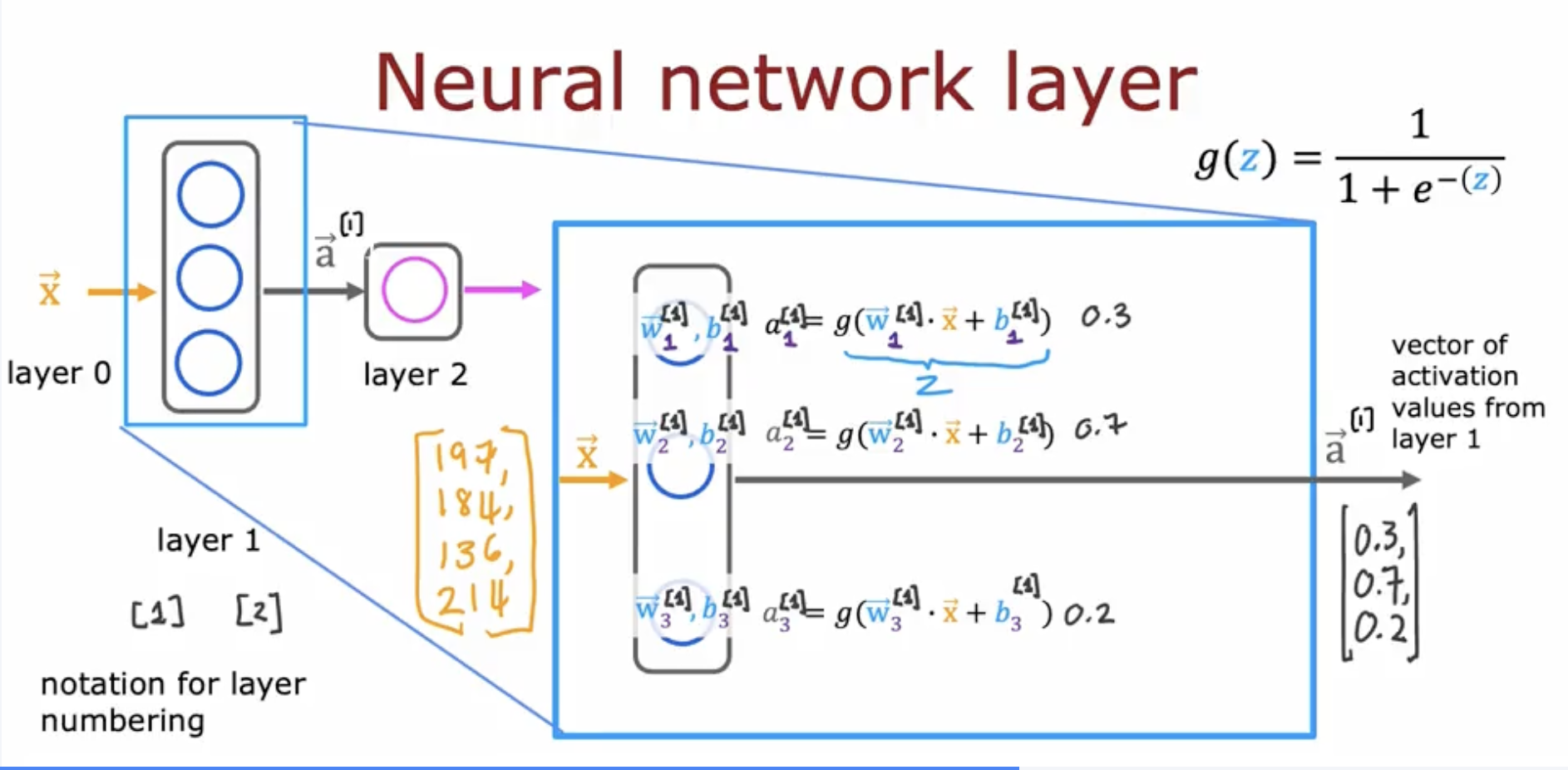
위의 그림을 보면, hidden layer에 대해서 자세히 나와있다.
먼저 입력값에 대해서 각 뉴런들이 가중치()를 부여한다. => 여기서 뉴런의 개수는 내가 설정하는 거임. 간단하게 생각해서 아까 티셔츠 판매에 관련해서 보면 얼마나 많은 숨은 특징들을 생각할 것이냐 정도이다. (price + shipping cost => 가성비, marketing => 대중성, price + material = 합리적인 품질) 처럼 내가 몇개의 추가적인 특징들을 볼 지 생각하는 거임.
가중치를 부여하고 bias값을 더해서 나온 값을 activation function에 넣어서 값을 도출해낸다. => activation function을 사용하는 이유는 간단하게 우리는 linear한 문제만 풀 건 아니니까. activation function이 없으면 linear한 문제밖에 해결 못함.(bias는 얼마나 임계값을 얼마나 쉽게 넘을 것인지에 대한 것)
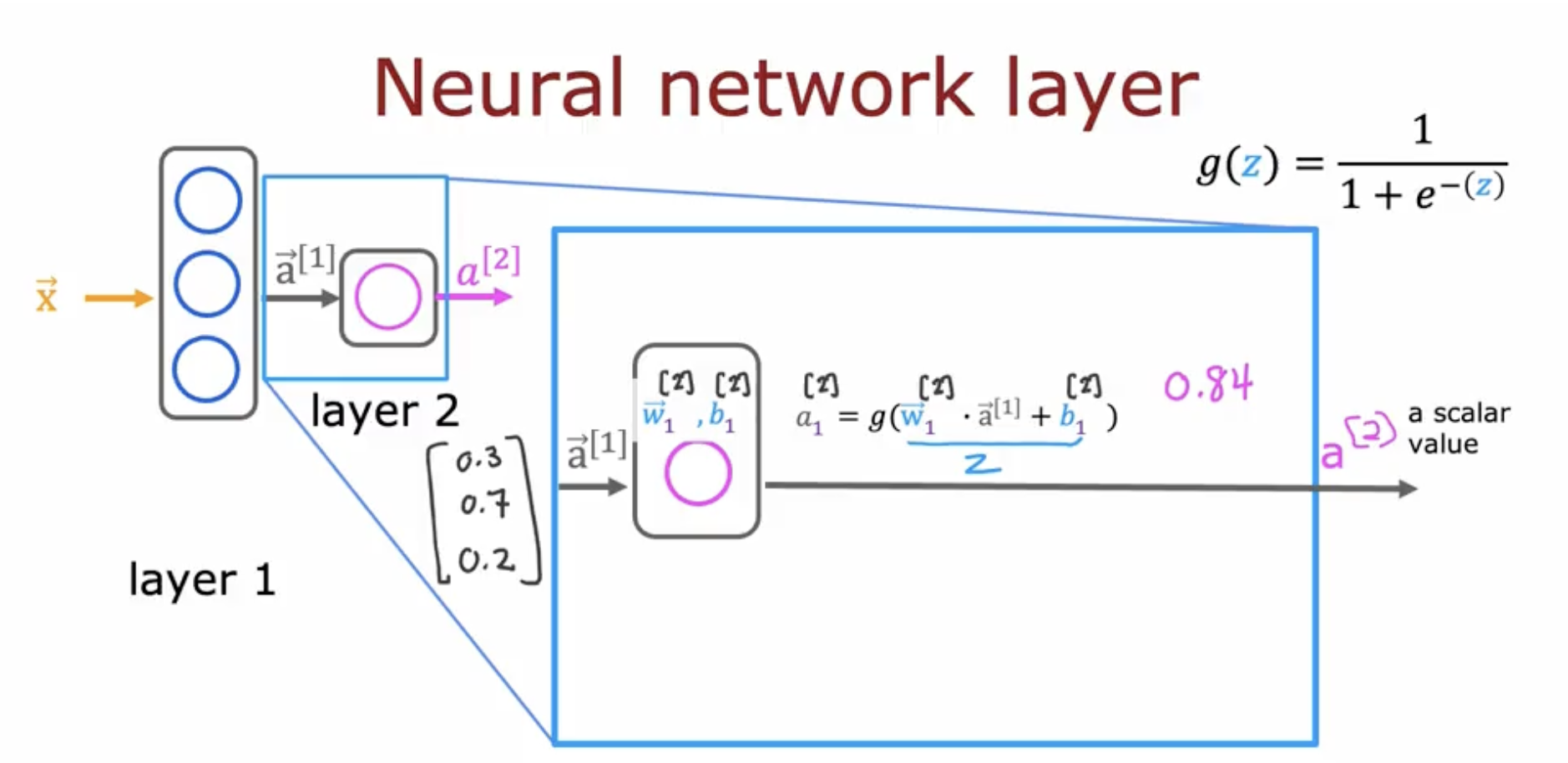
hidden layer을 살펴보았으니, 이번에는 output layer에 대해서 보면, hidden layer에서 나온 vector 값들에 가중치를 부여하고 똑같이 값을 구한다. 여기서 다른 점은
activation function은 우리가 어떤 output을 뽑느냐에 따라 달라진다. (sigmoid function은 0과 1 사이의 확률로 나타내고 그걸 이용해서 분류하려고 사용하는 경우가 있고, softmax는 각 결과값이 나올 확률을 구해내서 다중 클래스 분류에 사용된다.)
결국, 우리는 한 계층에서 결과값을 이러한 수식으로 나타낼 수 있다.
- l: l번째 계층, j: j번째 뉴런
- 입력 값()은 라고 생각하면 좀 더 일반적으로 볼 수 있다.
그래서 코드 부분으로 구현할 때(만약 분류 문제라고 한다면)
output layer 이전의 layer에서 나온 값은
layer_2 = Dense(units=1, activation='sigmoid')
a2 = layer_2(a1)
if a2>threshold:
y_hat = 1
else:
y_hat = 0이런 식으로 볼 수 있다.
Data in Tensorflow
사실 난 pytorch를 더 자주 쓰긴 하지만, 인공지능 데이터를 형태를 아는 것은 정말 중요하기에 정리한다.
x = np.array([[1,2,3],[4,5,6]])이러한 코드가 있을 때, 간단하게 [[...]] 이 대괄호는 행을 나타내고, 그 안에 하나의 원소는 열을 나타낸다고 보면된다.
x = np.array([200,17])그럼 이렇게 하나의 대괄호로 되어있으면, 이건 matrix가 아닌 그냥 하나의 vector로 보면 편하다.
그렇다면 이제 대괄호가 3개이상인 경우도 생각해봐야하는데, 이건 tensor라고 부른다(3차원 이상 행렬)
Building a neural network
간단하게 구현 코드를 넣어보겠다.
layer_1 = Dense(units=3, activation="sigmoid") #units: 뉴런의 개수, activation: 활성화 함수
layer_2 = Dense(units=1, activation="sigmoid")
model = Sequential([layer_1, layer_2])
# ==> 한번에 나타내고 싶으면
model = Sequential([
Dense(units=3, activation="sigmoid"),
Dense(units=1, activation="sigmoid")
])
model.compile(...) # loss function이나 optimizer 선언하는 부분
model.fit(x,y) # x는 입력값(feature), y는 label값(0 or 1)
model.predict(x_new) # 이런 식으로 추론을 진행한다.Dense 함수를 코드로 적어본다면,
def Dense(a_in, W, b):
units = W.shape[1]
a_aout = np.zeros(units)
for j in range(units):
w = W[:,j]
z = np.dot(a_in, w)+b
a_out[j] = g(z) #g: activation function
return a_out이런 식으로 우리는 간단하게 neural network를 코드로 나타낼 수 있다.
