Kaggle Titanic 데이터 분석
https://www.kaggle.com/c/titanic/data 의 데이터를 사용
(2)에서 Feature Engineering을 한 이후 각각의 독립변수(Pclass,Sex,Fare,Embarked,AgeCategory(Age),Family) 와 Survived와 상관관계 확인을 위해서 p-value 검정을 해보았다.
특히(2)에서 FE를 거치면서, Age를 카테고리화 해서 구간으로 나누어 보면 어릴수록 더 생존률이 높다고 나타날 줄 알았는데 FE 이후 선형 상관관계가 줄어들었기 때문에 p-value 검정을 한 후 모델에 적용해보고 싶었다.
먼저, FE이후 결측값을 확인을 안했기 때문에, 다시 확인해보면
train.isnull().sum()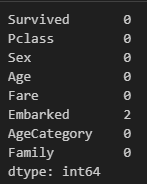
Embarked에도 결측값이 존재한다. 따라서 Embarked에 있는 결측값은 최빈값으로 대체해줬다.
most_frequent_value = train['Embarked'].mode()[0]
train['Embarked'] = train['Embarked'].fillna(most_frequent_value)이후 'Pclass', 'Sex', 'Fare','Age', 'AgeCategory', 'Family','Embarked'의 p-value 검정을 다음과 같은 코드로 해주었다.
from scipy.stats import chi2_contingency, pearsonr
# 독립 변수와 타겟 변수 정의
columns_to_test = ['Pclass', 'Sex', 'Fare','Age', 'AgeCategory', 'Family','Embarked']
target = 'Survived'
# 결과 저장을 위한 딕셔너리
p_values = {}
# 컬럼별 p-value 검정
for col in columns_to_test:
if train[col].dtype in ['int64', 'float64']: # 숫자형 변수
# 피어슨 상관관계 검정 사용
correlation, p_value = pearsonr(train[col], train[target])
p_values[col] = p_value
else: # 범주형 변수
# 카이제곱 검정 사용
contingency_table = pd.crosstab(train[col], train[target])
_, p_value, _, _ = chi2_contingency(contingency_table)
p_values[col] = p_value
# 결과 출력
for col, p_value in p_values.items():
print(f"{col}: p-value = {p_value:.5f}")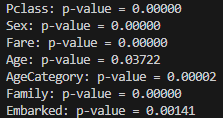
모두 p-value가 0.05 미만이므로 통계적으로 유의하다고 볼 수 있으며, Age보다는 AgeCategory 그대로 사용하는게 더 나아 보인다.
따라서 독립변수는 'Pclass','Sex','Fare','AgeCategory','Family','Embarked' 를 사용하여 모델에 적용하려고 한다.
여러 모델에 적용해 보면서 가장 정확도가 높은 것을 Kaggle에 제출 하는것이 목표이다.
모델에 적용하려는 도중 UnicodeEncodeError: 'ascii' codec can't encode characters in position 18-20: ordinal not in range(128) 라는 오류에 봉착했다.
간단히 인코딩 문제임으로 ascii라고 되있는 부분을 utf-8로 수정 후 정상적으로 작동했다.
KNN,
#입력과 타겟변수 만들기
train_input = train.drop('Survived', axis=1).values
train_target = train['Survived'].values
#모델링에 필요한 라이브러리 불러오기
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_validate
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
model = 적용할 모델
score = cross_validate(model, train_input, train_target,
return_train_score=True, n_jobs=1,
cv = StratifiedKFold())
#train 데이터 정확도, 검증 데이터 정확도 출력
print(np.mean(score['train_score']), np.mean(score['test_score']))
#KNN 0.8386647651165356 0.7531353963969619
#DecisionTreeClassifier 0.9393924232157209 0.8059004456719603
#RandomForestClassifier 0.9393924232157209 0.8047329106772958
#GradientBoostingClassifier 0.8959019493515294 0.8226978846274559
#GaussianNB(naive Bayes) 0.7797441574609578 0.7778293892411023
#SVC 0.6759348850402634 0.6667629150712447
#AdaBoostClassifier 0.8047153978284507 0.7755696440901387
#LogisticRegression 0.7881600926611722 0.7766681313163015GradientBoostingClassifier, DecisionTreeClassifier, RandomForestClassifier 가 적합학것으로 보이고 이 3개를 Kaggle에 제출해서 점수를 확인해보려고 한다.
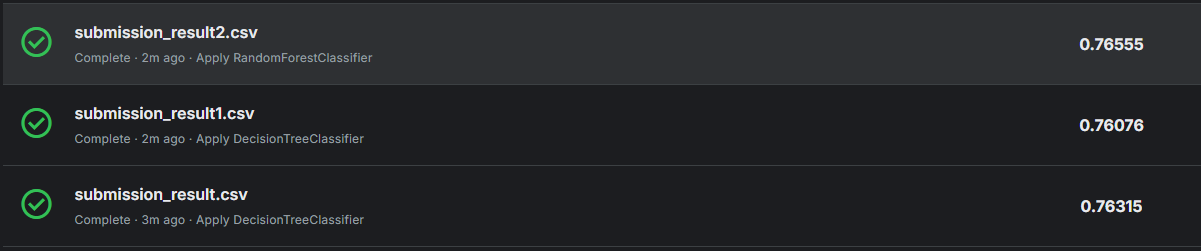
DecisionTreeClassifier가 가장 점수가 높은것으로 나타났다. 근데 혹시나 하고 다른것들도 적용해서 제출 해보았는데.
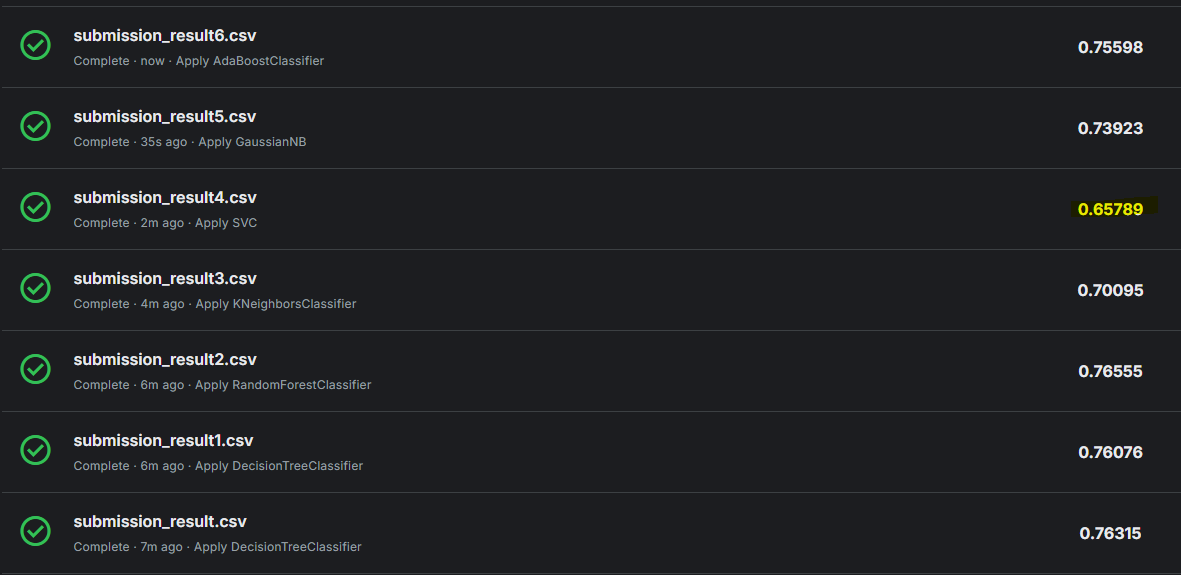
놀랍게도 SVC를 적용한것이 가장 점수가 높았다.
일단 이유를 분석해 보자면, GradientBoosting, RandomForest, DecisionTree는 비선형 모델이다. 하지만 DecisionTree 같은 경우는 과적합에 취약함으로 해당 모델에서 과적합이 일어났다고 볼 수 있으며, 교차 검증시에 SVC는 커널 트릭을 통해 고차원 공간에서 복잡한 경계를 학습하기 때문에 검증 데이터 자체에서 오류가 발생할 수 있고, 앙상블 모델인 RandomForest나 GradientBoosting는 교차 검증에서는 좀 더 일반적으로 높은 성능을 보일 수 있을것이다.
결론적으로, SVC가 데이터셋에 잘 맞는 모델일 가능성, 하이퍼파라미터 튜닝, 스케일링 문제, 그리고 모델의 특성이 중요하게 작용했을 것이다.
확실히 해당 모델들의 특성과 알고리즘에 대한 이해가 깊게 공부해볼 필요가 있을거 같다. 직감적으로는 SVC가 가장 성능이 좋지 않을까? 라고 했지만 데이터 정확도와 검증 데이터 정확도를 비교하여 순서대로 적용하였을때 해당 결과대로 점수가 높을것이라고 생각했지만, 실제로는 그렇지 않았다.
개선 해볼점을 생각해보면
1. 데이터 탐색 EDA를 좀 더 확실히 하고
2. Feature Engineering에서 범주화나, 결측값과 같은 문제를 여러 방안으로 적용해보고
3. 사용하지 않은 Column이나 직관적으로 연관이 없어 보이는 Column들을 적용하여
4. Modeling에서 파라미터 값을 수정
해당 과정을 통해서 Kaggle 득점을 올릴 수 있지 않을까 라고 생각한다.
