Kaggle Titanic 데이터 분석
https://www.kaggle.com/c/titanic/data 의 데이터를 사용
(1)에서 데이터 값을 충분히 살펴봤음으로 Feature Engineering을 하려고 한다.
먼저, Sex에 포함된 male과 female을 0과 1로 매핑하였다.
train['Sex'] = train['Sex'].map({'male': 0, 'female': 1})Age에 있는 결측값을 대체하기 위해 다음과 같은 방안을 생각했다.
1. 특정 값(평균)으로 대체 2. 예측 모델을 사용한 대체 3. 확률적 대체
이중 평균값으로 대체하기를 택하였고 Age의 결측값에는 Age의 평균값을 채웠다.
train['Age'] = train['Age'].fillna(train['Age'].mean())그리고 해당 Age의 값들을 범주화 하기 위해서 pd.cut을 사용하면
train['AgeCategory'] = pd.cut(train['Age'], 5)
train[['AgeCategory', 'Survived']].groupby(['AgeCategory']).mean()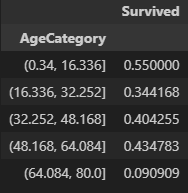
이러한 결과를 얻을 수 있고, 해당 값을 토대로 0~16 / 16 ~ 32 / 32 ~ 48 / 48 ~ 64 / 64+ 로 각각 1,2,3,4,5 라는 값으로 범주화 해주었다.
bins = [0, 16, 32, 48, 64, float('inf')] # 각 구간의 상한선 정의
labels = [1, 2, 3, 4, 5] # 각 구간에 매핑할 숫자 레이블
train['AgeCategory'] = pd.cut(train['Age'], bins=bins, labels=labels, right=False)
이후 (1)편에서 Sibsp와 Parch를 유무 관계로 0과 1로 나눴었는데, 아예 가족이라는 Column을 만들어 Sibsp,Parch의 값을 토대로 합쳐주었다.
train['Family'] = (train['SibSp'] + train['Parch']).apply(lambda x: 1 if x >= 1 else 0)
Embarked(탑승항구) S,C,Q의 값을 각각 1,2,3으로 매핑해주었다.
train['Embarked'] = train['Embarked'].map({'S': 1, 'C': 2, 'Q': 3})Fare의 결측값은 평균으로 대체해주었다.
train['Fare'] = train['Fare'].fillna(train['Fare'].mean())'Cabin', 'SibSp','Ticket', 'PassengerId','Parch','Name' Column을 제거한다.
columns_to_drop = ['Cabin', 'SibSp','Ticket', 'PassengerId','Parch','Name']
train = train.drop(columns=columns_to_drop)생존률에 영향을 미치는것으로 보이는 Pclass,Age,Sex,Fare,Embarked,AgeCategory,Family의 상관계수를 확인해보려고 한다.
default값은 피어슨(선형) 상관계수이므로 스피어만(비선형) 상관계수도 함께 확인해보았다.
train.corr()
train.corr(method='spearman')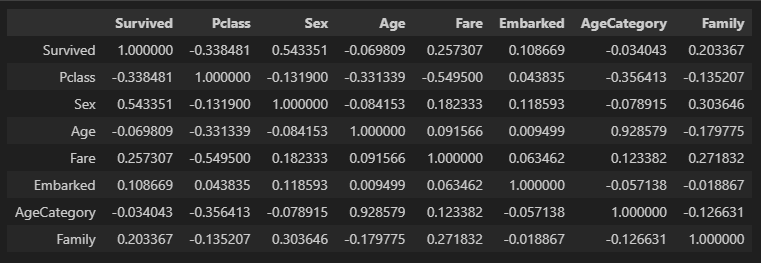
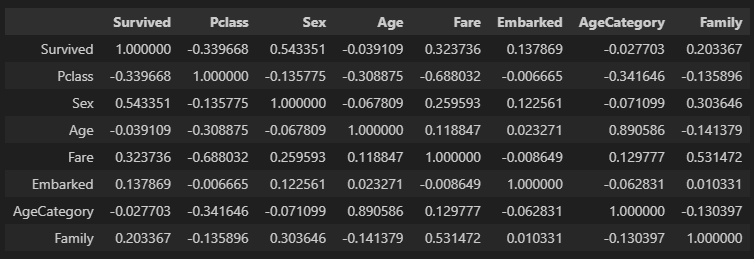
(위 피어슨, 아래 스피어만)
기본 데이터의 상관계수를 보면
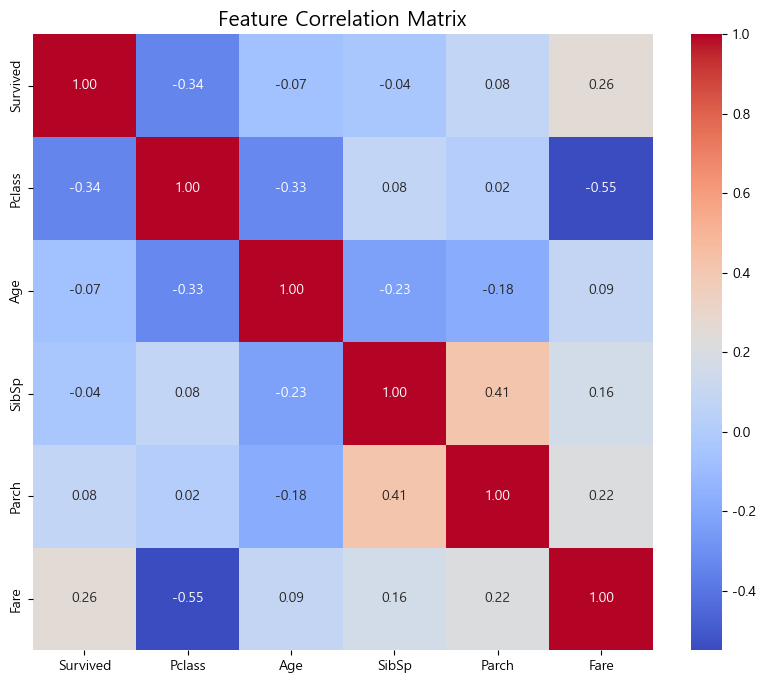
Feature Engineering 후와 꽤 차이가 있음을 볼 수 있다.
다음은 모델링에 대해서 진행해 볼 예정이다.
