Data Parallel
-
학습에 사용할 데이터를 병렬화 하는 것
-
Single node, multi-GPU에서 동작하는 multi-thread 모듈
Forward Pass
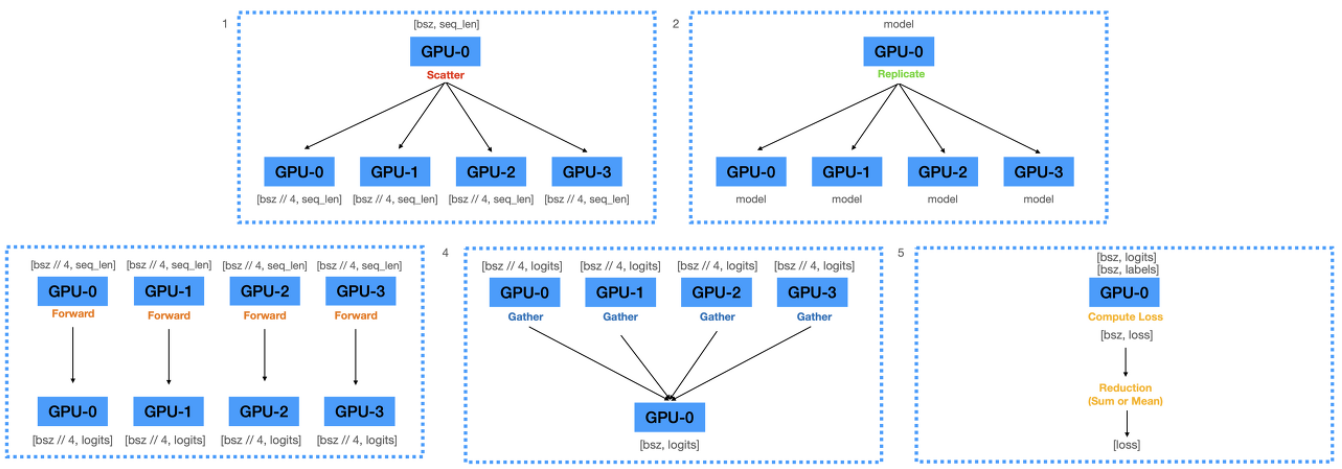
- gpu_num=4, master_gpu=0
-
전체 batch GPU0에 올리고 그 후 batch를 4등분하여 각 GPU에 전송
-
GPU0에 올라와 있는 모델 파라미터를 다른 GPU에 복제
-
각 디바이스에서 forward 연산 수행, 모델 출력 계산
-
출력값들을 GPU0으로 gather
-
loss 계산
Backward Pass
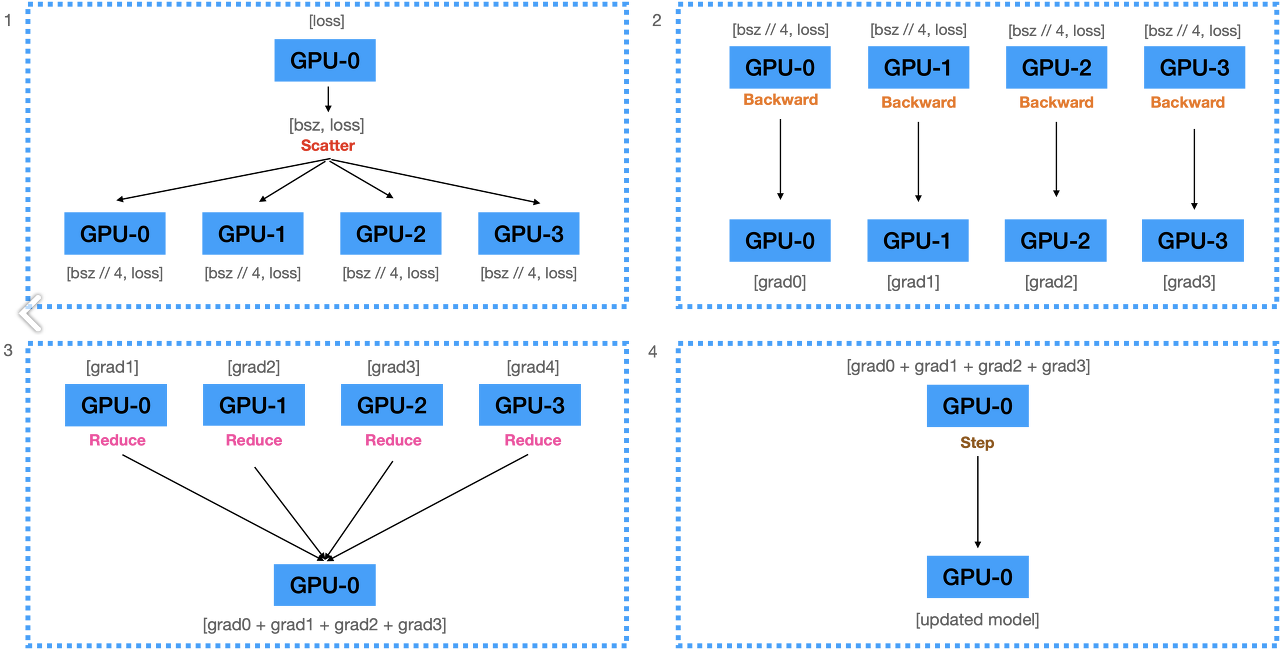
-
계산된 Loss를 scatter
-
backward를 수행하여 gradient 계산
-
gather
-
model 갱신
Forward Pass 개선판
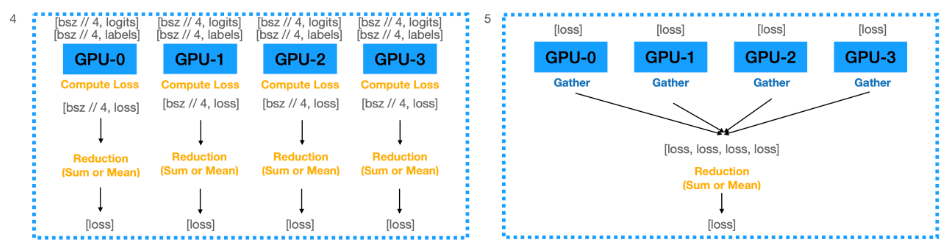
-
기존 방법은 logits를 하나의 GPU에 모으고 loss를 계산하기 때문에 master_gpu의 메모리 사용이 더 많게 된다.
-
각 GPU에서 loss를 구한 뒤 하나의 GPU에 gather 한다면 어느 정도 완화 가능
장점
-
배치 사이즈를 크게 할 수 있다.
-
n개의 gpu에 동일 모델을 복제하기 때문에 학습 속도가 빠르다.
단점
-
Multi-thread module이기 때문에 python에서 비효율적이다.
- 파이썬은 Global Interpreter Lock에 의해 하나의 process에서 동시에 여러 개의 thread가 작동할 수 없다. Multi process 프로그램으로 만들어야 파이썬에게 유리하다.
-
매 step마다 업데이트된 모델이 복제되어야 한다.
- All-reduce로 완화 가능: 복제는 매우 비싼 과정, reduce를 수행하여 gradient를 모은 뒤 계산 결과를 모든 디바이스테 복제하는 방법으로 완화, 업데이트 -> 복제가 아니라 모든 곳에서 업데이트
All-reduce
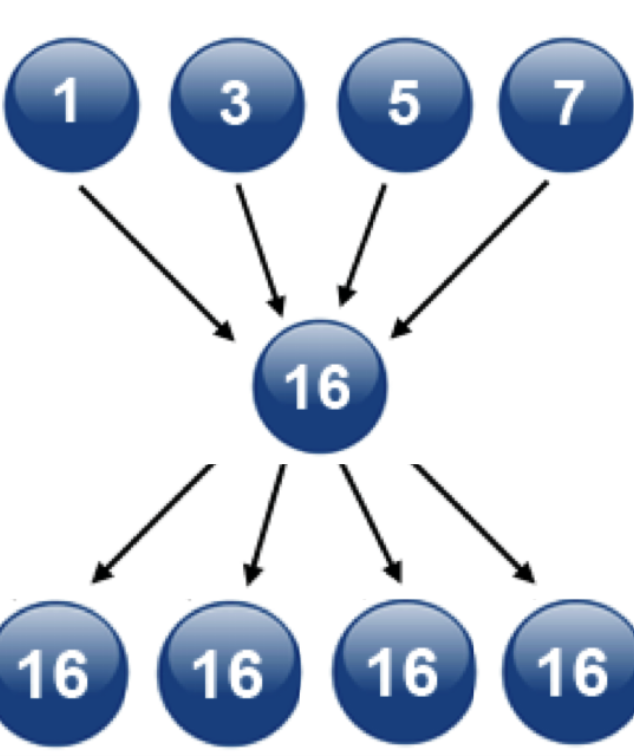
- Reduce + Broadcast 방식: 마스터 프로세스 부하 심함
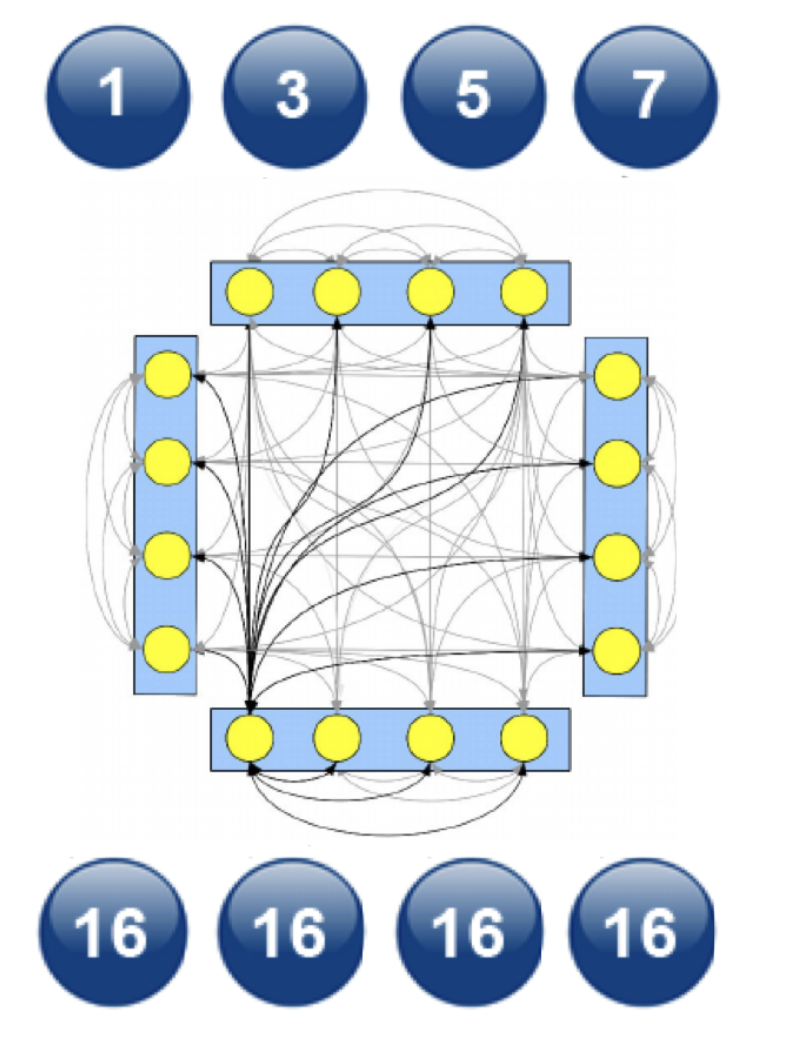
- All to All 방식: 연산량

- Ring All-reduce 방식: 마스터 프로세스 부하 쏠리지 않음, 효율적 연산
Distributed Data Parallel
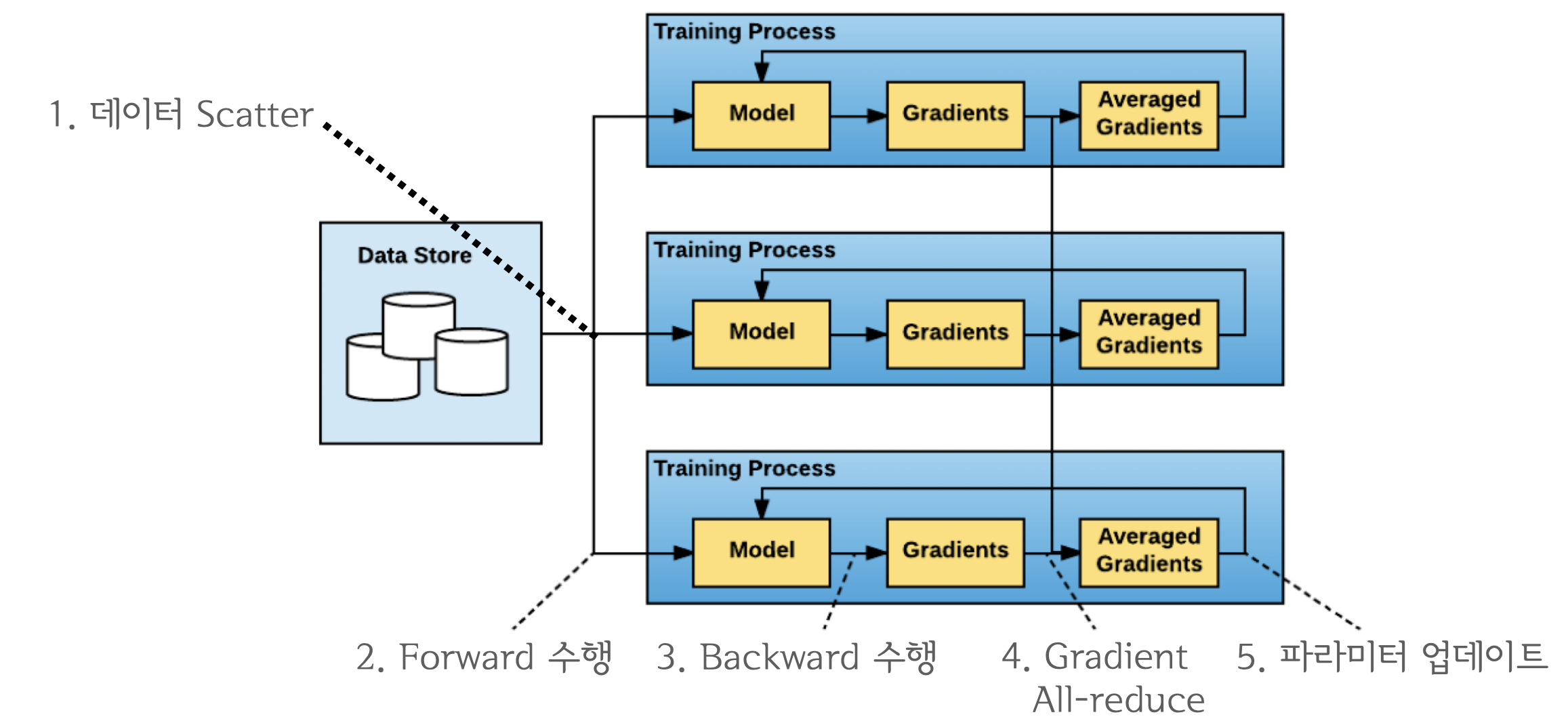
-
DP 개선판, single/multi node && multi GPU에서 동작하는 multi-process 모듈
-
All-reduce를 활용하며 마스터 프로세스 개념이 사라져 학습 과정이 심플해짐
장점
-
multi node 학습 가능
-
DP 장점: 빠른 학습 속도, 큰 배치 사이즈
단점
- multi node 학습 불안정
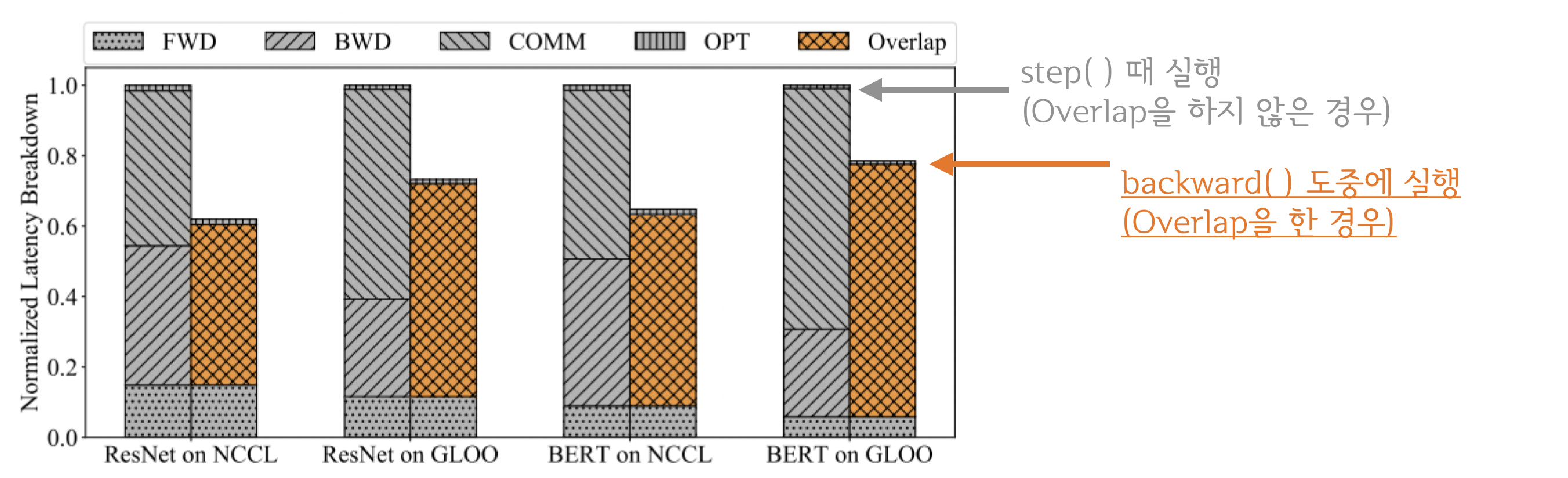
- All-reduce는 네트워크 통신, backward/step은 GPU 연산이라 동시 처리 가능
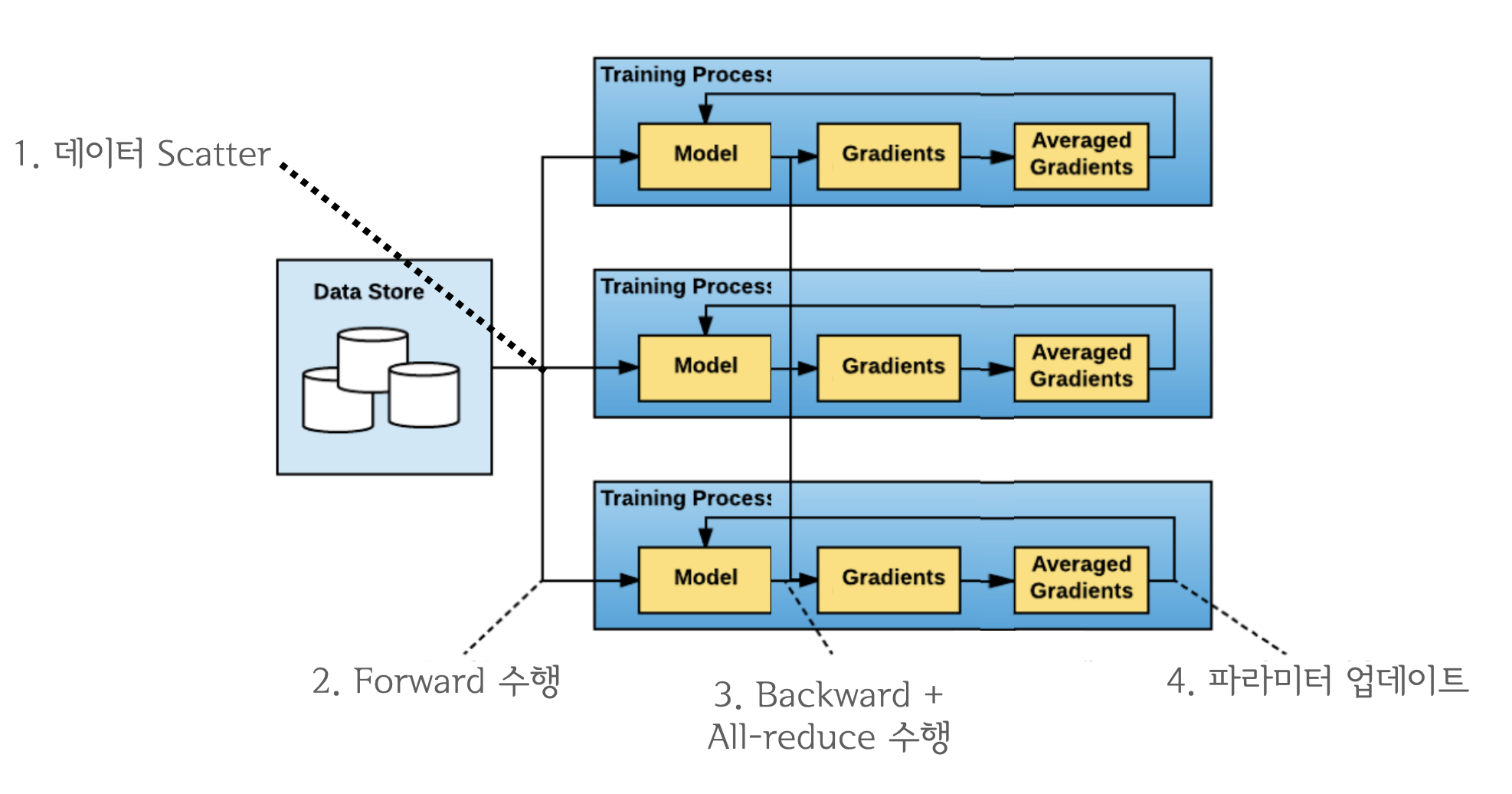
-
backward와 All-reduce 동시 수행 시 overlap 구간이 늘어나서 연산 효율 증대
-
backward 연산은 뒤쪽 레이어부터 순차적으로 이루어지기 때문에 계산이 끝난 레이어를 먼저 전송하면 됨
-
Gradient Bucketing을 통해 Bucket이 가득 차면 All-reduce를 수행
Gradient Bucketing
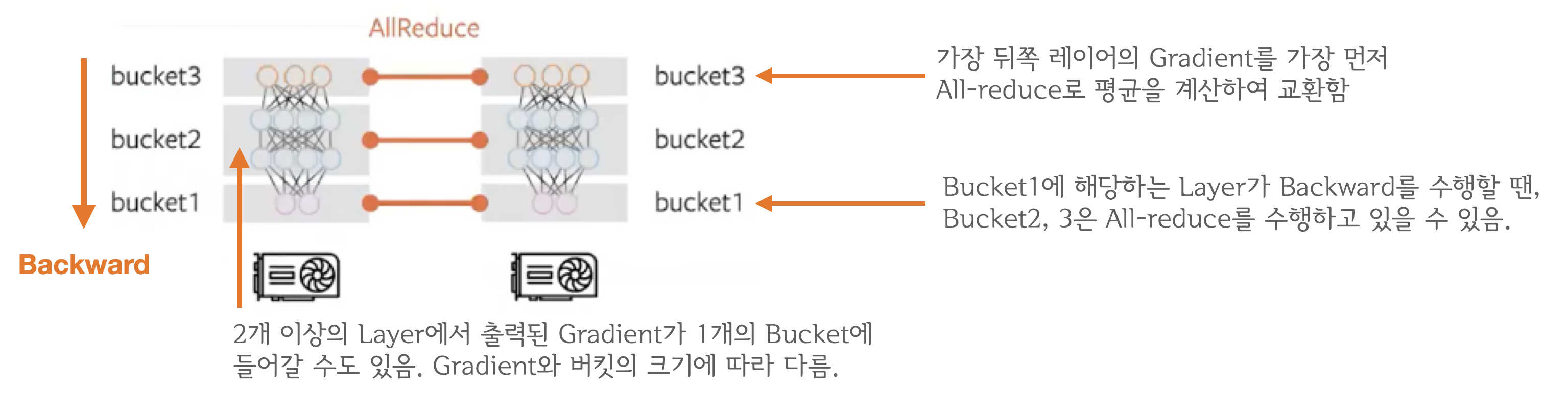
- 일정 사이즈의 bucket에 gradient를 저장하고 가득차면 다른 프로세스로 전송하여 All-reduce 수행
Questions
-
DP란?
- Single node Multi GPU에서 동작하는 학습 데이터를 병렬화하는 모듈로 학습 속도를 가속화한다.
-
DP의 문제점은?
-
Master GPU에 과도한 메모리 부담이 생긴다. 완화가 가능하지만 더 많은 메모리 사용은 필연적
-
매 step마다 가중치가 갱신된 모델을 복제해야하기 때문에 오래 걸린다.
-
-
DDP란?
- DP의 문제점을 개선하기위한 모듈, All-reduce라는 개념을 활용하여 master 개념 사라짐
