Data Normalization
-
값의 범위를 0~1 사이로 변경하는 것, scale이 큰 feature의 영향이 너무 높아지는 것을 방지하기 위해서 사용, 학습 속도 향상 효과도 있음
-
데이터 정규화에는 Min-Max 정규화, Z-score 정규화 존재
데이터 정규화: Min-Max 정규화
-
최소값은 0으로 최대값은 1로 변환
-
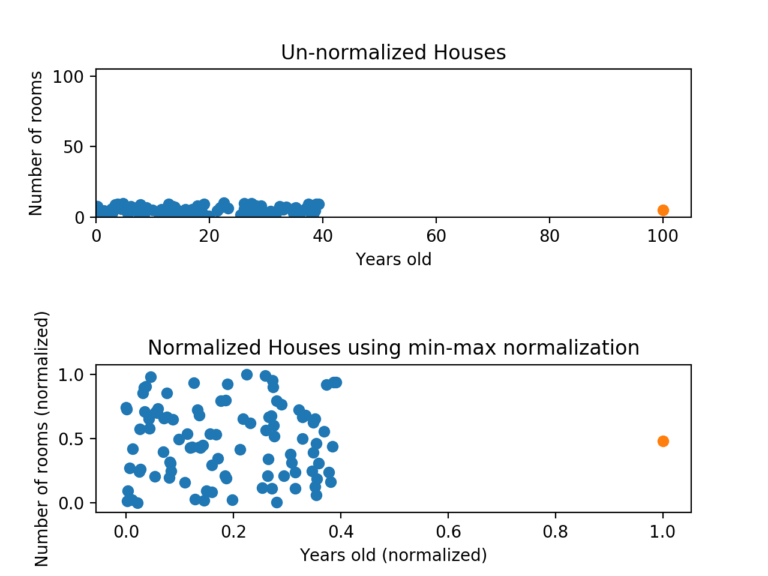
- 이상치에 영향을 너무 많이 받게 됨, 단점 보완을 위해 Z-score 정규화 사용
데이터 정규화: Z-score 정규화
-
이상치 문제를 피하는 데이터 정규화
-
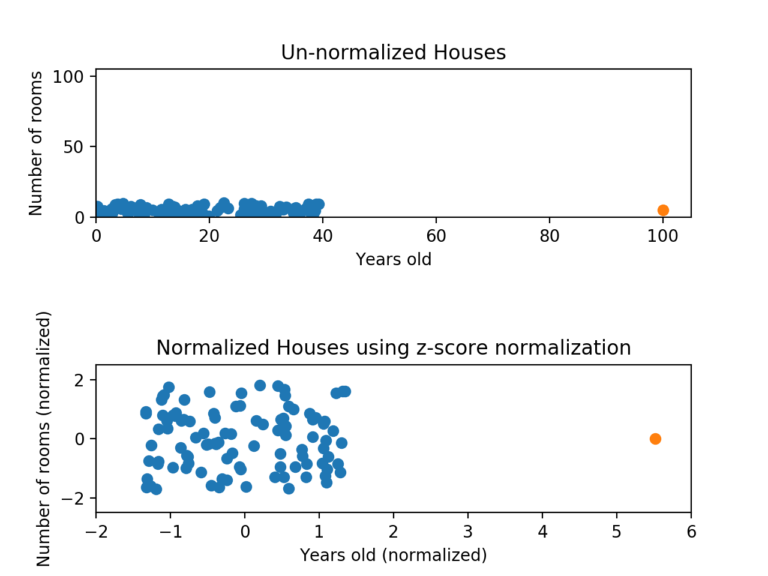
- 이상치가 존재해도 데이터 포인트들이 고루 퍼져 있게 정규화 됨
Standardization
- 표준화, 값의 범위를 평균 0, 분산 1이 되도록 변환, 정규 분포를 표준 정규 분포로 변환하는 것, Z-score 정규화와 동일한듯
Normalization
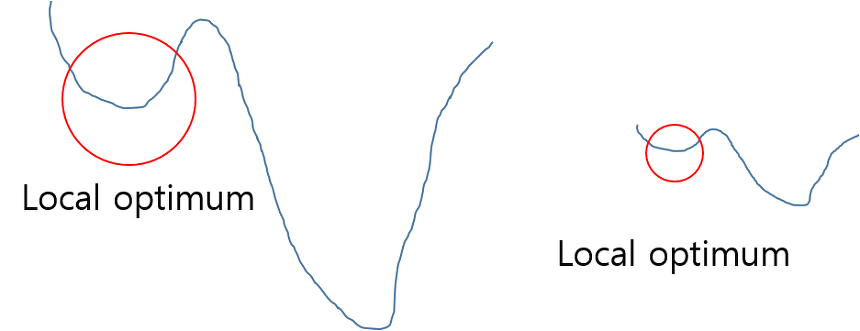
- 정규화란 왼쪽의 오차 함수 그래프를 오른쪽과 같이 만들어 Local optimum에 빠질 가능성을 낮추는 것
Batch Normalization
-
-
-
-
-
Mini-batch의 mean, variance를 구한 뒤 Z-score normalization 수행
-
마지막 단계의 는 각각 scale, shift를 위한 trainable, 비선형 성질을 유지하며 학습 가능하게 만듦
-
배치 정규화를 하는 이유는 local optimum에 빠지는 것을 방지하고 Gradient vanishing, exploding을 방지, 학습 과정 자체를 안정화하여 학습 속도를 가속화하기 위함
-
배치 정규화가 없을 때 학습이 불안정해지는 이유는 layer마다 입력 값의 분산이 달라지는 현상인 Internal Covariance Shift 때문이라 주장, 신경망이 깊어질 경우 학습이 어려워지는 원인
-
Inference 시에는 고정된 평균과 분산을 이용하여 정규화를 수행
Weight Normalization
-
layer의 가중치를 정규화
-
-
Batch normalization에서 입력 값을 표준 편차로 나누는 것과 비슷한 효과, 입력을 표준 편차로 나누거나 scale 재조정을 하지 않는 mean-only batch normalization과 함께 쓰는 것이 권장됨
Layer Normalization
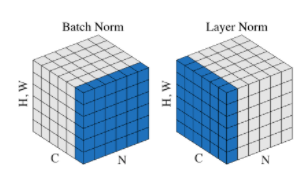
- BN과 유사, feature 차원에서의 정규화, RNN에서 매우 좋은 성능
Instance Normalization
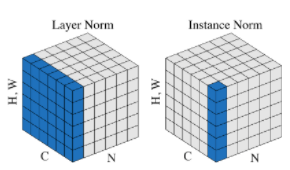
- 각 채널에 정규화, 이미지에 국한된 정규화
Group Normalization
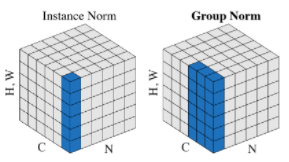
- 채널을 그룹으로 묶어 정규화
