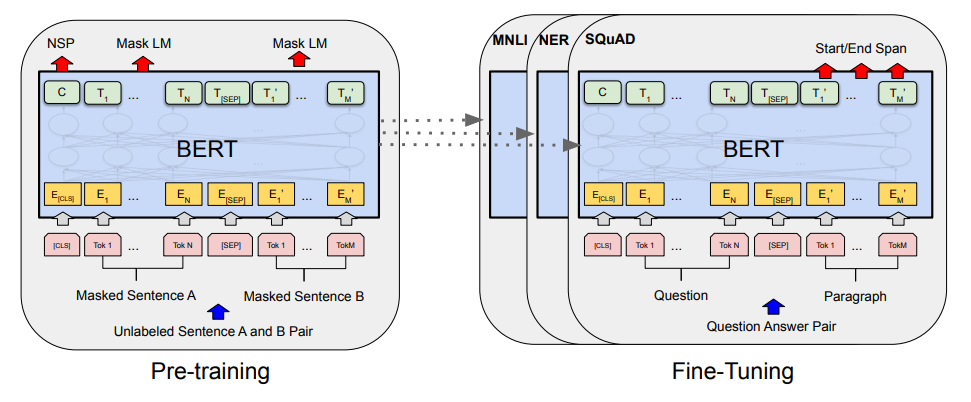
BERT (Bidirectional Encoder Representations from Transformers)
Architecture
- BERT base: Transformer Encoder 12 layer
Pre-training
-
MLM 중 하나, 문장 중간에 빈 칸을 만들고 단어 예측, 두 문장이 이어지는 지 예측하는 과정에서 사전학습
-
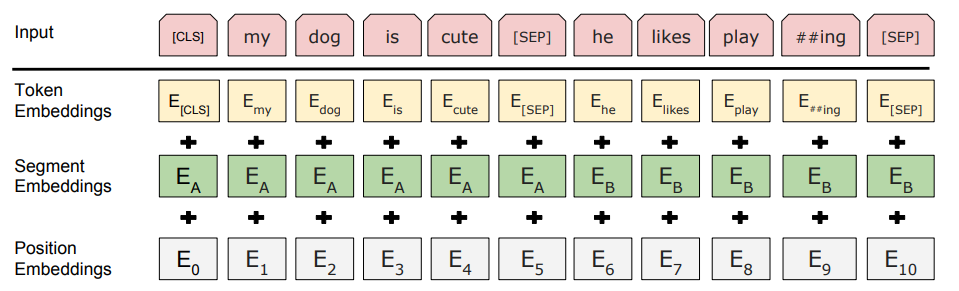
Corpus에서 이어진 문장 두 개를 sequence로 만들고 A,B를 Segment Embedding 부여, 50% 확률로 IsNext, 50% 확률로 이어지지 않는 문장, 각 문장의 토큰 중 15%를 MASK 대상으로 설정, 그 중 80%는 실제 [MASK] 토큰으로 변경, 10%는 그대로, 10%는 랜덤 토큰으로 변경하여 사전학습과 미세조정 간 괴리 줄이기 시도
-
Wikipedia와 BooksCorpus 데이터셋 활용하여 학습 데이터 구축
Contribution
-
기존 사전학습 방법들은 사전학습 시 양방향 정보를 고려하지 못함, 양방향 문맥 정보가 모두 중요한 token level task에서 부진.
-
Masked Language Model을 사용해 양방향 문맥도 담을 수 있는 모델을 제시, masking을 통해 bidirectional context를 학습할 수 있게 함.
-
BERT는 사전학습을 통해 language 자체에 대한 학습을 한 뒤 task에 맞게 미세조정되는 방식
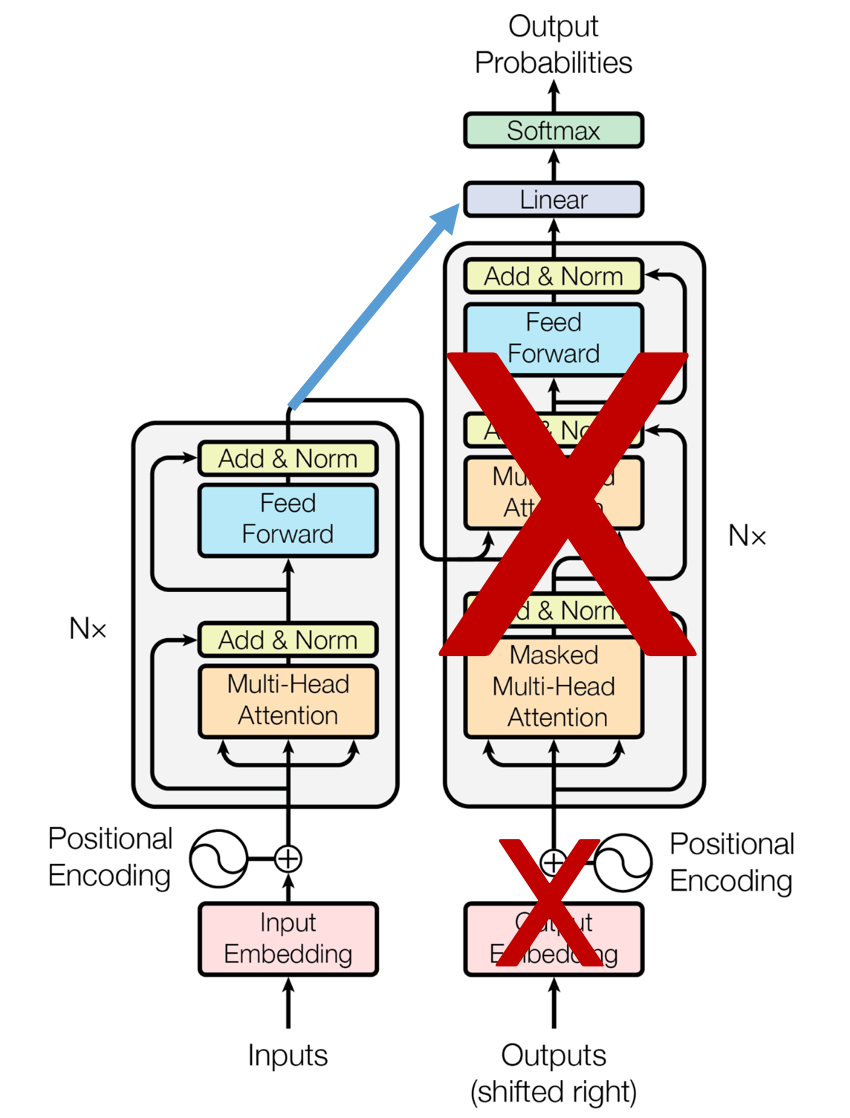
GPT (Generative Pre-trained Transformers)
Architecture
-
LM 중 하나, 이전 단어들이 주어졌을 때 다음 단어를 맞추는 과정에서 사전학습 됨
-
문장 시작부터 순차 계산이기에 일방향적
-
Transformer Decoder만 사용
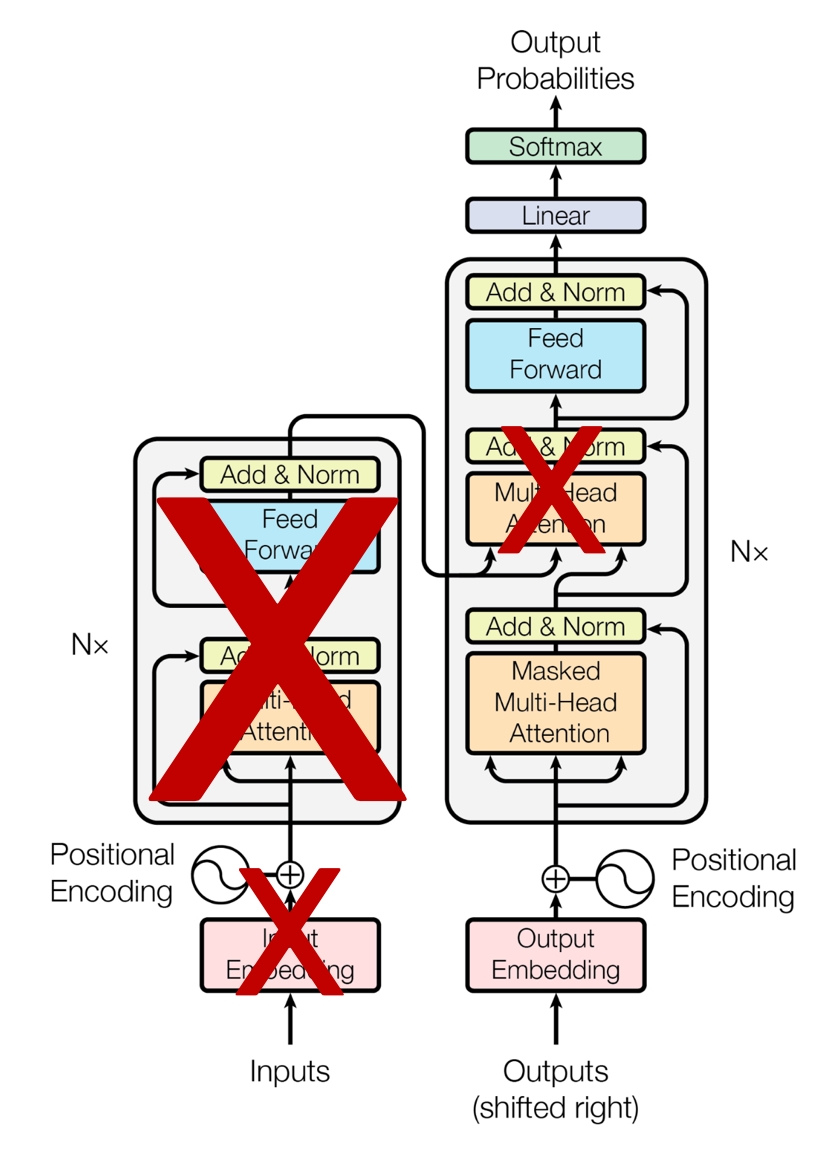
- Encoder 없음, Encoder cross attention도 없음, Decoder Masked Self Attention만 수행, Look ahead mask 적용
Pre-training
- 다음 단어 맞추기로 사전학습, Unlabeled data로 unupservised 학습 진행 후 downstream task에 대해 적은 양의 데이터로 finetuning 진행
Contribution
-
Transformer 기반 생성 모델의 제안
-
언어 모델의 사전학습과 파인튜닝의 효과 입증
-
GPT-2 부터 Zero-shot performance가 가능해짐
Questions
-
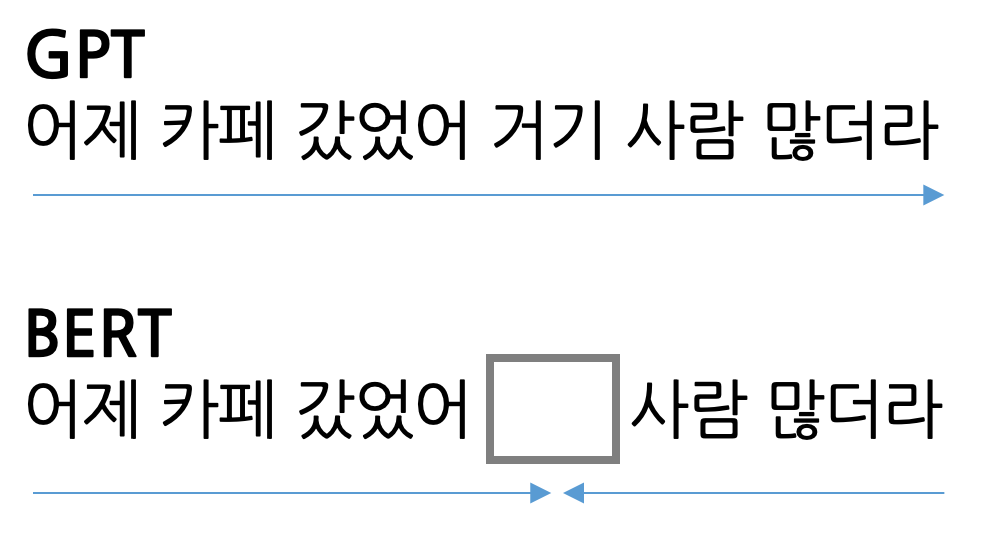
BERT와 GPT의 차이점?
-
BERT는 Transformer Encoder Block을 사용한 구조, GPT는 Decoder Block을 사용한 구조
-
사전학습 시 BERT는 MLM 방식을 채택했기에 양방향 정보를 고려, GPT는 LM 방식을 채택했기에 Uni directional 정보를 고려하여 생성
-
-
BERT의 주된 기여?
-
MLM 방식의 사전 학습 방법론 제안
-
기존 사전학습 방법들은 양방향 정보를 고려하지 않게 모델이 훈련되어 token level task에서 약세
-
BERT는 Masked Language Model 방식의 사전 학습을 진행, 두 문장에 빈 칸을 뚫고 두 문장이 이어지는지를 예측하며 학습하기 때문에 양방향 정보를 고려한 Language 자체를 학습할 수 있음
-
-
GPT의 주된 기여?
- 생성형 사전 학습을 통해 Generative 언어 지능을 가진 LM 제작, Fine-tuning을 통해 여러 task에 적용 가능
