Problems of Existing Seq2Seq models
-
RNN은 짧은 참조 윈도우로 긴 입력을 처리하는 데 문제가 있음
-
LSTM, GRU는 상대적으로 긴 윈도우를 가지고 있지만 무한하지 않기에 똑같은 문제가 있음
-
또한 Seq2Seq 모델은 순차적으로 입력을 처리해야해서 병렬화가 불가능, 학습 시간이 지나치게 길어지는 문제 존재
Attention
-
위 기존 Seq2Seq 모델의 두 가지 문제에 대한 해결책이 된 메커니즘
-
이론적으로 리소스가 충분하다면 무한한 크기의 윈도우를 가질 수 있고 전체 문맥을 반영할 수 있음
-
병렬화도 가능하고 Query와 모든 Key를 비교하기 때문에 장기 기억 손실을 해결할 수 있어서 빠른 학습 속도와 더 큰 데이터셋의 적용이 가능
-
입력의 길이와 상관 없이 중요한 모든 부분에 대해 Attend to 하는 메커니즘
Self-Attention
- 입력으로 들어온 시퀀스 안에서 단어들 간의 관계를 고려하는 것
Query, Key, Value
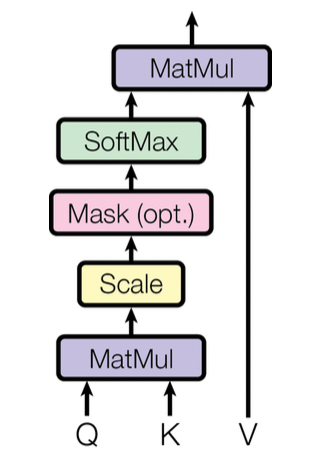
Scaled-dot Product Attention
-
-
Query: 물어볼 것, Key: 비교할 것, Value: 데이터의 값
-
: 키 벡터의 차원 수
-
를 통해 query와 key 사이의 유사도 계산, Value 벡터들을 가중합하여 셀프 어텐션 계산 수행
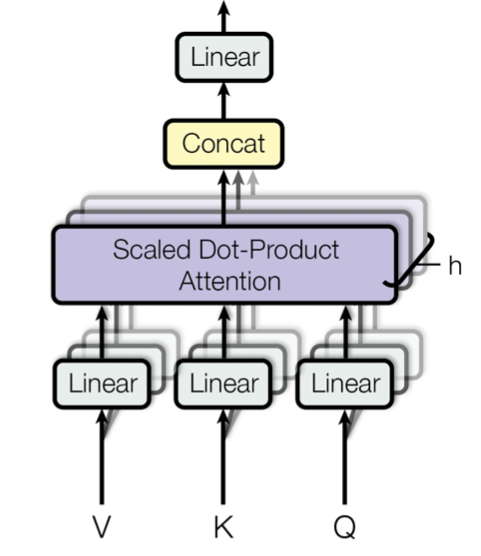
Multi-Head Attention
-
head가 여러 개, Q,K,V를 linear projection을 통해 중간에 매핑하여 여러 개의 attention function들을 만드는 것이 더 효율적이라고 함
-
Usage In Transformer
-
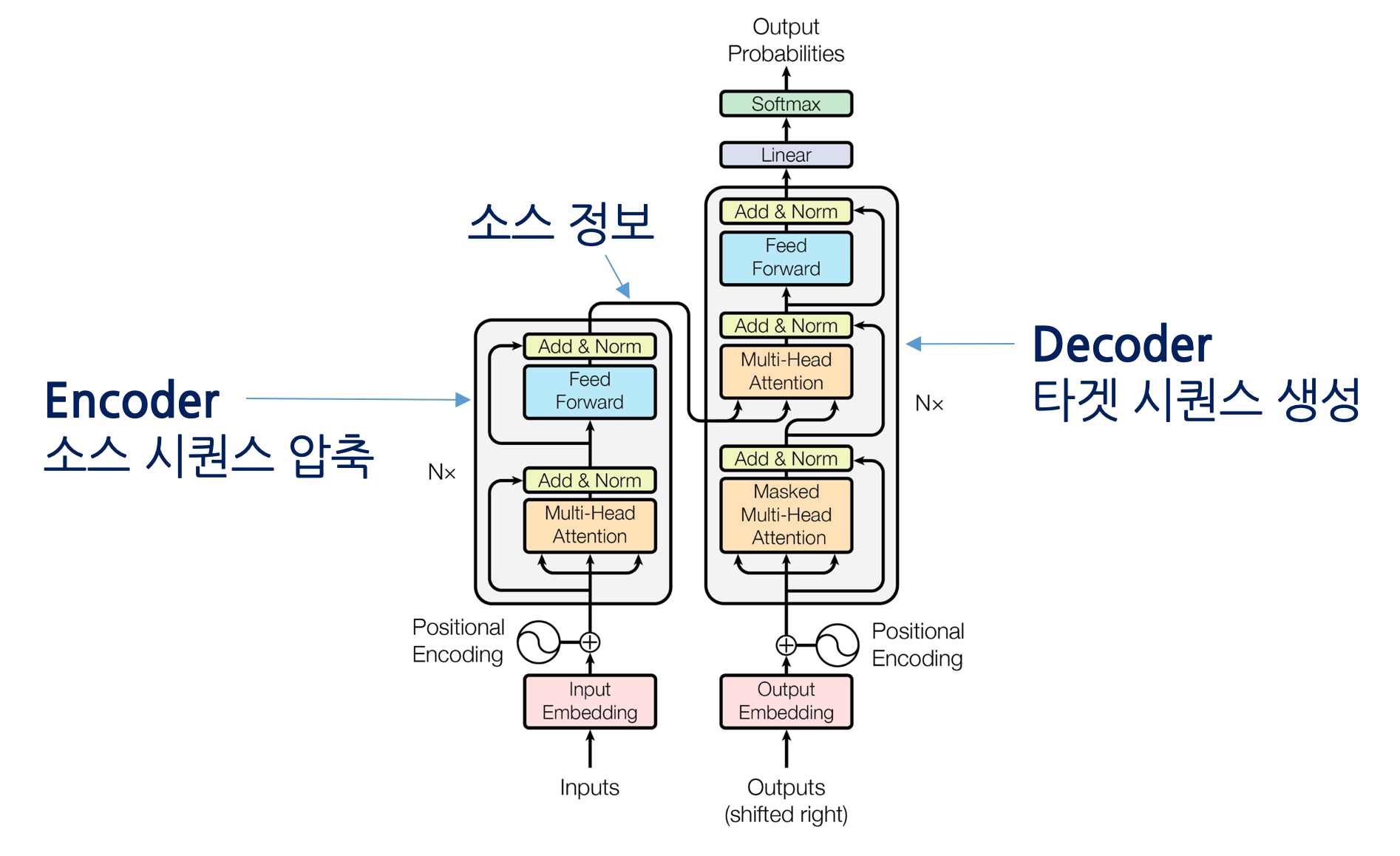
Encoder multi-head attention: Q,K,V 모두 encoder 출신, encoder의 position은 전 layer의 모든 position을 참조하여 해당 position과 모든 position 간의 correlation information을 더하여 사용.
-
Decoder masked multi-head attention: encoder와 비슷하지만 auto-regressive하기 위해 masking vector를 사용해 해당 position 이전의 벡터들만 참조
-
Encoder-decoder multi-head attention: Q는 decoder, K,V는 encoder 출신, decoder의 position들이 encoder의 모든 position을 참조하여 사용.
Why Self-Attention

computation complexity
-
보통 n(sequence length)<d(representation dimensionality)
-
RNN보다 self-attention이 complexity가 작음
parallel
- RNN은 Sequential operation이 n번, self-attention은 input의 모든 position 값들을 한 번에 처리 가능
Long-range dependencies
-
self-attention은 다른 모든 토큰들을 참조하여 correlation information을 더하여 사용하기 때문에 path length가 maximum O(1)
-
path length가 짧을수록 long dependency를 더 잘배움
Transformer
- Attention을 전적으로 이용해 구축한 구조, Embedding, Positional Encoding, Attention, FFNN, Add & Norm으로 구성
Positional Encoding
-
Transformer는 attention으로만 구성된 구조, sequence 정보를 사용하지 못하기 때문에 positional encoding을 통해 sequence 정보를 추가
-
위치의 representation을 벡터로 표현한 것, embedding에 더해 사용
이상적인 positional encoding의 조건
- 각 위치의 값은 Deterministic하게 결정되며 유일해야
- 데이터와 관계 없이 각 위치의 값은 동일해야
- 길이와 상관 없이 적용 가능해야
- 간격이 동일하다면 거리는 동일해야
- 데이터와 관계 없이 i,j 사이의 거리는 동일해야
방법1 - Normalize Indexing (Normalize Count)
-
시작에 0, 끝에 1, 중간은 interpolation
-
I want you: I-0, want-0.5, you-1
-
다른 데이터일 때 거리가 동일하지 않음
방법2 - Simple indexing (Count)
-
선형 숫자 할당
-
I want you: I-1, want-2, you-3
-
거리는 동일, 숫자가 매우 커질 수 있고 학습할 때보다 큰 입력이 들어오면 문제 발생 가능
방법3 - Sinusoidal Positional Encoding
-
-
주기가 미세하게 변경되는 sin, cos 함수를 활용하여 유일성 확보
-
를 의 linear function(회전 변환 행렬 활용)으로 나타낼 수 있기 때문에 모델이 쉽게 상대적인 위치를 참조할 수 있을 것이라 생각
-
학습 가능한 layer로도 만들어서 실험해 보았지만 결과는 다를 바 없었다
Position-wise Feed Forward Neural Network
-
-
Multi-head attention의 결과 x, 가중치 행렬 W들, ReLU 활성화 함수라 MAX,
Residual Connection, Layer Normalization
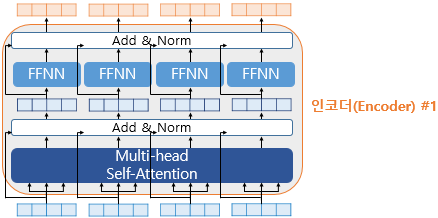
- Residuial Connection: 잔차 연결, 서브층의 입력과 출력을 더하는 것, 모델의 학습을 돕는 기법
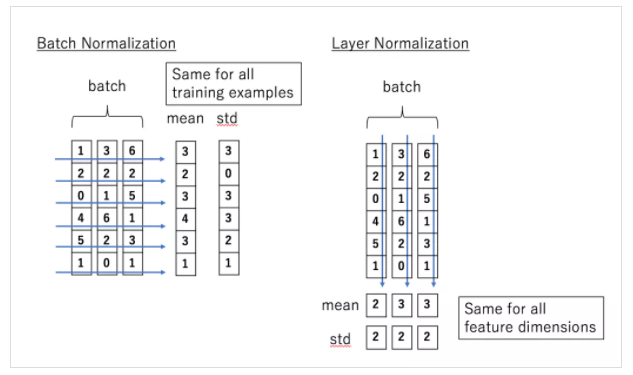
- Layer Normalization: 층 정규화, 텐서의 마지막 차원에 대해 평균,분산을 구해 정규화하여 학습 안정화, input을 기준으로 평균과 분산을 계산
Questions
- Attention이 뭔지?
- 입력의 중요한 부분에 가중치를 더 두고 보는 메커니즘이다.
- Self-attention과 Cross-attention의 차이점은?
- Self-attention은 transformer encoder에서 입력 시퀀스 내에서 단어들 간의 관계를 고려하는 것이기 때문에 Q,K,V가 같은 출처이고 Cross-attention은 decoder에서 encoder의 출력을 고려하는 것이기 때문에 Q/K,V가 다른 출처로 묶인다.
- Masked multi-head attention의 다른점은?
- transformer decoder에서 수행하는 어텐션으로 이후 position의 토큰들은 모두 마스킹하고 어텐션을 수행하는 것이다.
-
Attention이 개선한 점은 뭔지?
-
기존 Seq2Seq 모델인 RNN은 long dependency를 학습하는 데 어려움이 있었다. LSTM이나 GRU는 어느정도 해결하긴 했지만 문제가 있었고, 입력 sequence를 하나 씩 보며 학습을 진행해야 해서 병렬화를 할 수 없었다.
-
Attention은 Long dependency 학습 문제를 Query를 모든 Key와 비교함으로써 해결했고, 병렬화 또한 가능하게 만들었다.
-
- Transformer는 뭔지?
- Attention을 전적으로 사용해서 만든 구조이다. Attention만 사용했을 때에는 입력 sequence의 위치 정보를 사용하지 못한다. Transformer는 Positional Encoding을 통해 sequence 위치 정보를 임베딩에 추가하는 방식으로 사용했다.
- Transformer에서 사용한 Positional Encoding 방법은 무엇인가?
- 저자들은 단순 인덱싱과 interpolation, 사인 코사인 함수를 사용하는 방식을 시도했다. 다른 방법들은 문제가 있었지만 사인 코사인 함수를 사용하는 방식이 제일 이상적이다 판단하여 사용했다.
-
Transformer의 문제점?
-
sequence 길어지면 계산량 quadratic하게 증가
-
inference는 auto-regressive라 GPU 충분 이용 불가
-
