Word Embedding Model
-
단어를 vector representation으로 변환하는 모델
-
원-핫 벡터는 단어 벡터 간 유사도 비교를 못함, 단어의 의미를 수치화하는 방법을 사용
Word2Vec
-
단어 -> 벡터, 같은 문장에서 나타난 인접 단어들은 의미가 비슷할 거라는 가정 사용, 희소 표현이 아닌 분산 표현으로 단어의 의미를 여러 차원에 분산하여 표현하는 것을 학습
-
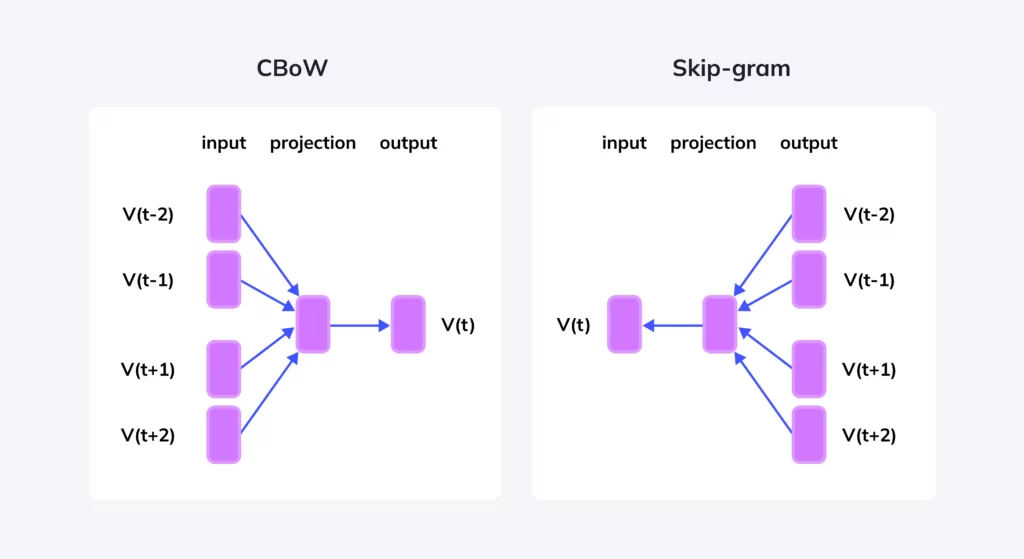
Continuous Bag of Words, Skip-Gram 사용
Continuous Bag of Words (CBoW)
-
주변 단어를 입력으로 중간 단어를 예측
-
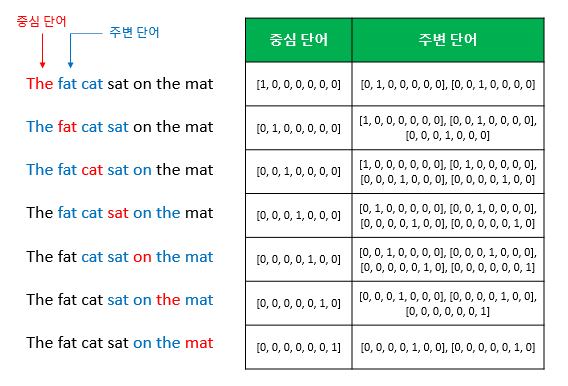
Sliding window를 사용하여 주변 단어와 중심 단어의 선택을 옮겨가며 학습 데이터셋 생성, Word2Vec의 입력은 원-핫 벡터
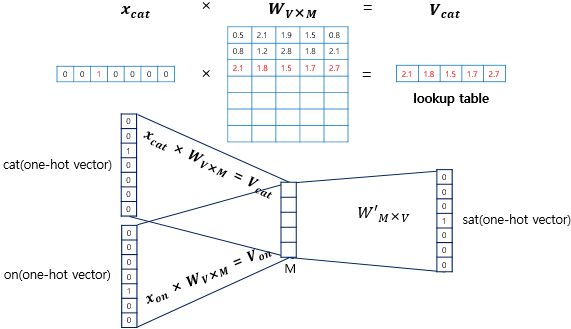
- 얕은 신경망 구조, 서로 다른 가중치 행렬인 W와 W'을 학습해가는 구조
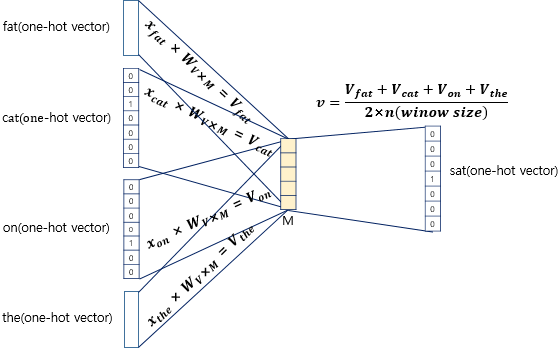
- projection layer에서 벡터 평균 구해서 사용
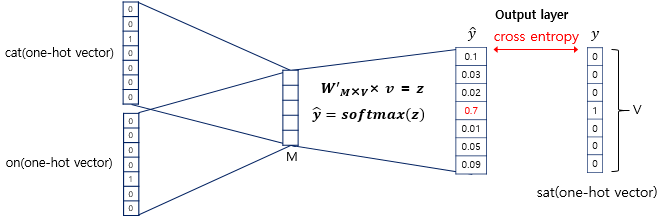
- softmax로 정답 단어 확률 반환
- 크로스 엔트로피 오차 사용해서 출력된 단어 확률 분포가 정답과 근사하도록 학습
Skip Gram
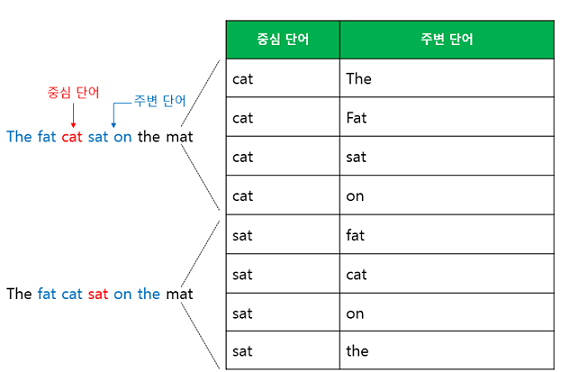
- 중간 단어를 입력으로 주변 단어를 예측
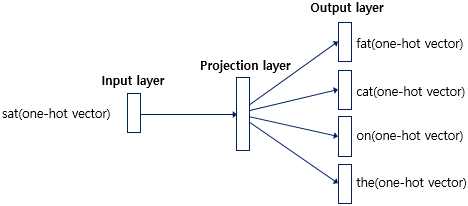
- 벡터 평균 없음, Skip-gram이 CBOW보다 성능이 좋다 알려져 있음
GloVe
-
카운트 기반의 LSA (Latent Semantic Analysis)와 예측 기반으로 작동하는 Word2Vec의 단점을 지적, 카운트 기반과 예측 기반을 모두 사용하는 방법론
-
LSA는 Document Term Matrix, TF-IDF와 같이 문서 내 단어 빈도수 카운트 행렬을 입력으로 사용해 차원 축소로 잠재 의미를 표현하는 카운트 기반 방법론
-
Word2Vec은 실제 값과 예측 값에 대한 오차 손실 함수를 줄이며 학습하는 예측 기반의 방법론
-
Word2Vec으로 임베딩된 두 단어벡터의 내적은 코사인 유사도가 되도록 설계됨
-
임베딩된 두 단어벡터의 내적은 전체 말뭉치의 동시등장확률이 되도록 설계
-
임베딩된 단어벡터 간 유사도 측정을 수월하게 하면서도 말뭉치 전체의 통계 정보를 좀 더 잘 반영해보자는 것이 아이디어
Questions
-
Word2Vec이 뭔가?
-
단어를 분산표현으로 임베딩하는 모델. 기존 원-핫 벡터로 표현되던 희소표현의 단점을 개선하기 위해 고안, 기존 방법은 벡터 간 유사도를 계산할 수 없었음.
-
CBOW와 Skip-Gram으로 학습되는 얕은 신경망.
-
-
CBOW와 Skip-Gram이 뭔가?
-
CBOW는 Continous Bag of Words로 주변 단어가 주어졌을 때 중심 단어를 예측하는 방식으로 학습하는 것.
-
Skip-Gram은 중심 단어가 주어졌을 때 주변 단어를 예측하는 방식으로 학습하는 것.
-
-
Word2Vec과 GloVe의 차이점은?
-
Word2Vec은 데이터셋 전체의 통계적 특징을 사용하지 않는다는 단점을, 기존 통계적 방법은 임베딩된 단어들 간 유사도를 측정하기 어렵다는 단점을 개선하고자 나온 것이 GloVe이다.
-
Word2Vec은 임베딩된 두 단어 벡터의 내적이 코사인 유사도가 되도록 설계되었지만 GloVe는 임베딩된 두 단어 벡터의 내적이 동시등장확률이 되도록 설계되었다.
-
