
Recurrent Neural Network
-
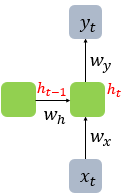
Hidden layer의 output을 출력층의 입력으로 사용할 뿐만 아니라 다음 time step의 hidden layer node의 입력으로도 사용하는 네트워크
-
hidden layer에서 activation function을 통해 결과를 내보내는 노드를 메모리 셀 또는 RNN 셀이라 표현
-
입력과 출력의 길이를 다르게 설계 까능, 1:N, N:1, N:N 가능
-
-
-
사용 이유: ReLU 사용 시 이전 값이 커짐에 따라 전체 출력이 발산하는 문제가 생길 수도 있음, sigmoid보다 나은 tanh를 사용
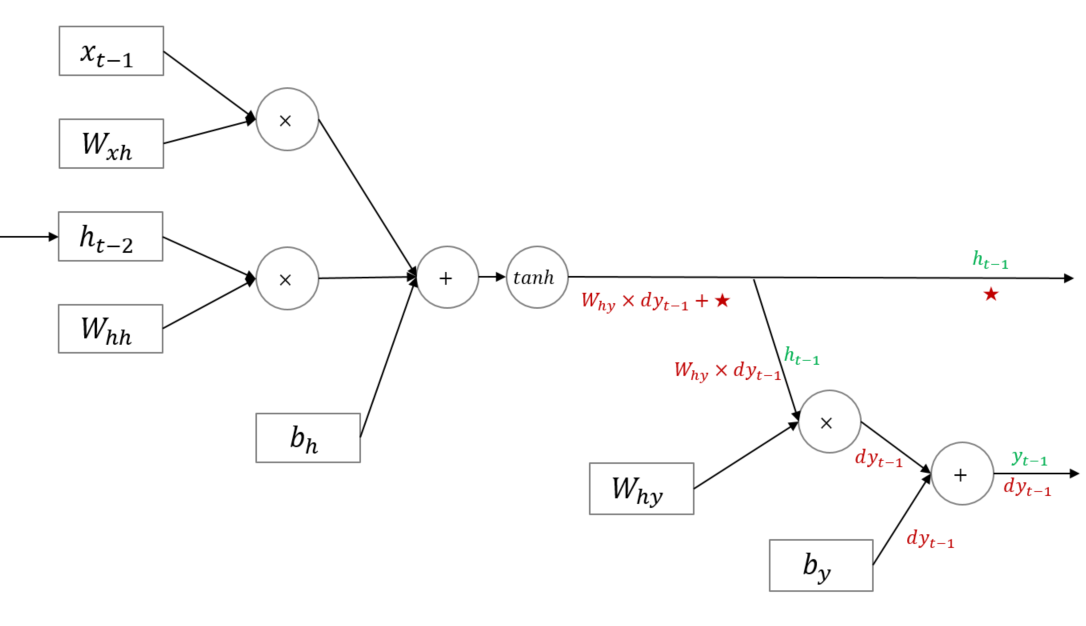
- 현재 이전 모든 시점의 gradient를 누적합하여 역전파
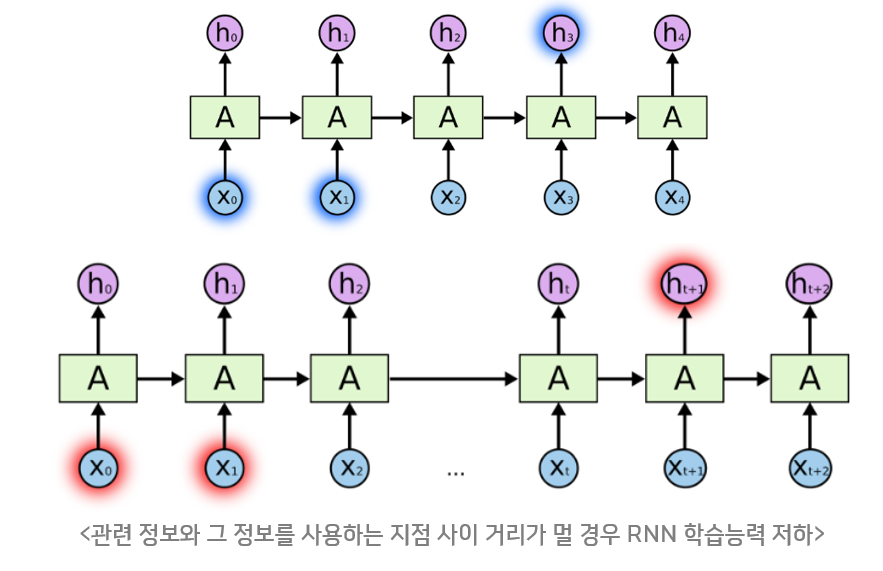
- 현재 시점에서 멀어질수록 기울기 소실 발생, 장기 정보 손실됨
LSTM
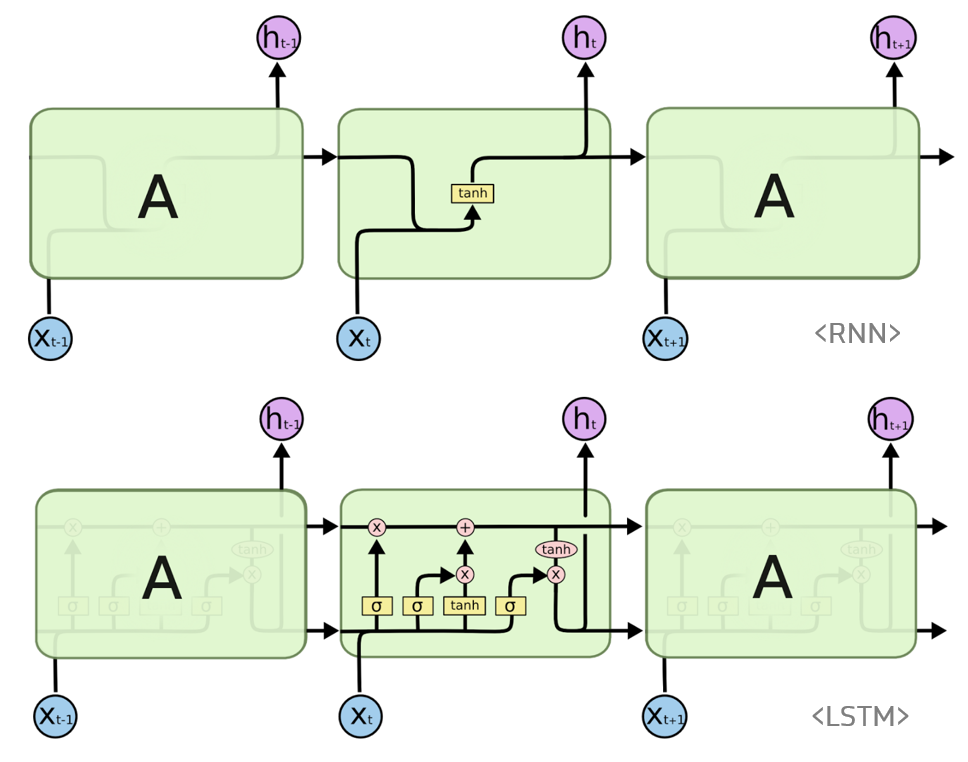
- RNN의 장기 정보 손실을 극복하기 위해 고안, Cell-state를 추가한 구조, 윗 검정 화살표가 Cell-state, 아랫 검정 화살표는 Hidden state

- forget gate : 과거 정보를 잊기 위한 게이트, cell-state에서 버릴 정보를 정함
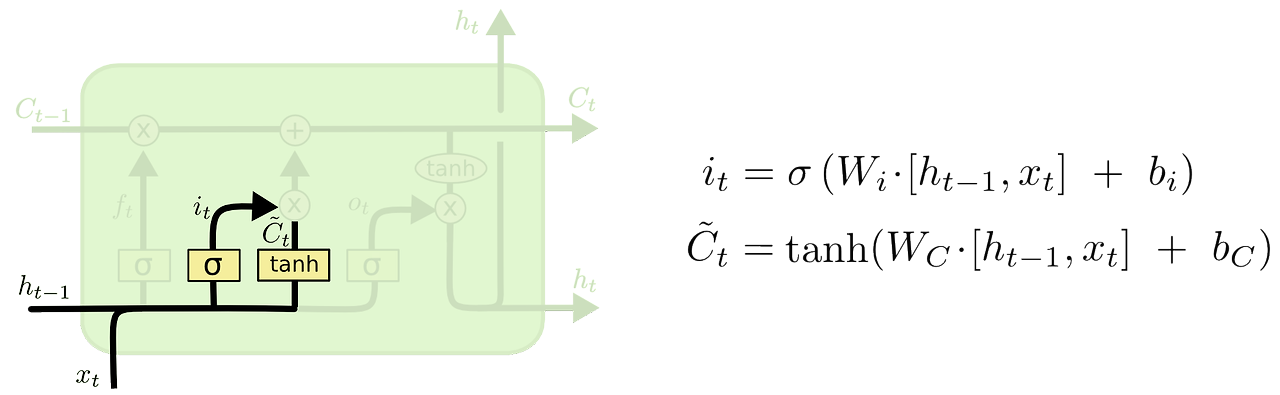
- input gate : 현재 정보를 기억하기 위한 게이트, cell-state에 저장할 정보를 정함
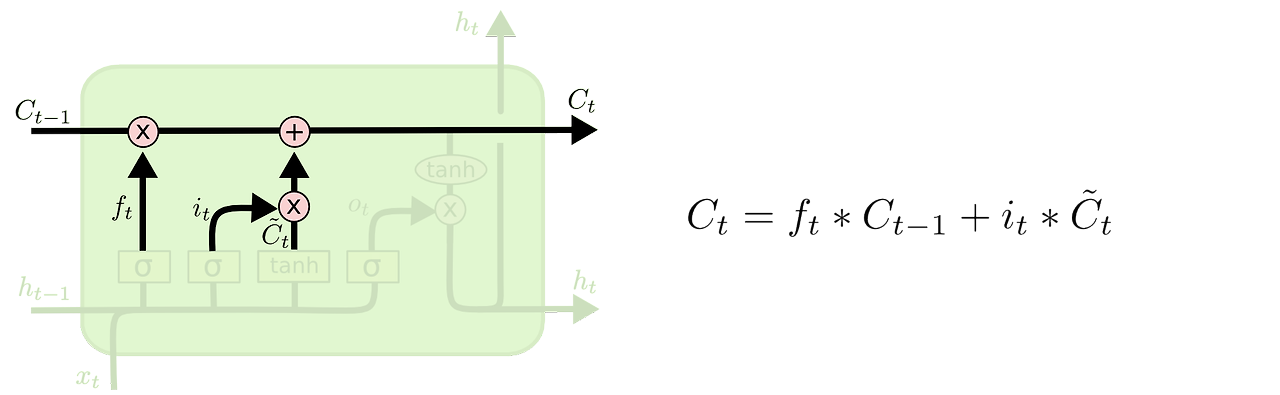
- 새로운 cell-state는 기존 cell-state에 망각 적용 후 새 정보를 더해서 구함
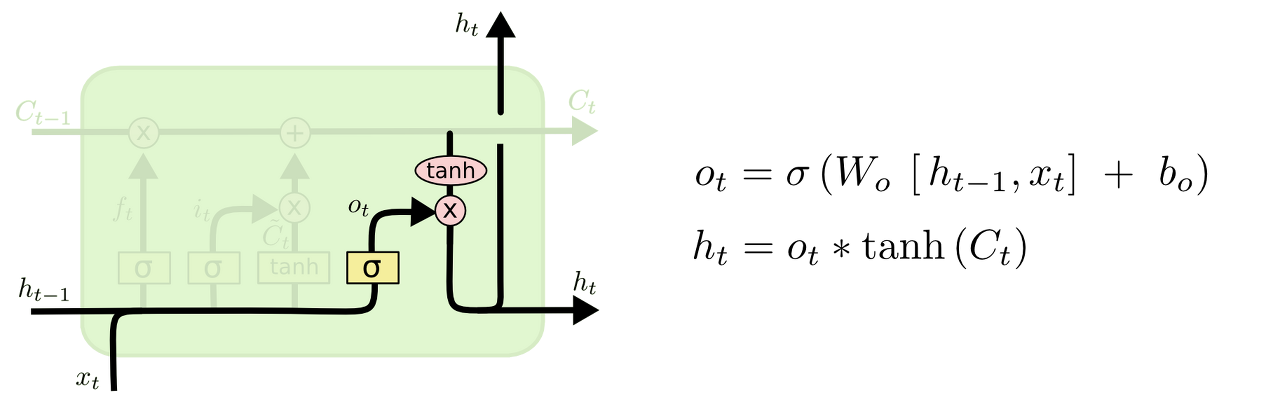
- output gate : 이전 hidden state와 입력과 새 cell-state를 사용하여 새 hidden state 반환
GRU

-
LSTM의 forget gate, input gate, output gate -> update gate, reset gate.
-
LSTM의 cell-state가 hidden state에 합쳐짐
-
LSTM에 비해 빠른 학습 시간, 낮은 계산 복잡성이 장점
-
reset gate : 지난 정보를 얼마나 버릴 지 결정, sigmoid 출력이기 때문에 (0,1)
-
-
update gate : 새 정보를 얼마나 반영할 지 결정, sigmoid 출력이기 때문에 (0,1)
-
-
: 현재 시점에 사용할 메모리의 정보
-
-
Questions
-
RNN, LSTM, GRU의 다른점은?
-
RNN은 이전 time step의 hidden state를 사용하여 다음 time step의 hidden state를 계산하는 데 사용하는 네트워크, 시간에 따라 누적된 정보를 처리할 수 있는 신경망
-
LSTM은 RNN의 장기 기억 손실 문제를 해결한 네트워크, cell-state와 gate들로 장기 기억을 모방한 신경망
-
GRU는 LSTM의 복잡한 구조를 개선하기 위한 네트워크, 아키텍처가 단순하고 매개변수가 적어서 계산이 더 효율적이며 학습 속도가 빠른 신경망
-
- RNN과 비교했을 때 LSTM의 장점은?
- 장기 의존 기억 모방을 통한 vanishing gradient 문제 해결
- LSTM과 비교했을 때 GRU의 장점은?
- 간단한 모델 구조를 통한 계산 효율성, 빠른 학습 속도
