완벽주의를 내려놓고 블로그 작성을 시작해보고자 한다. 뭐든지 완벽하게 이해하고 나서 글로 남겨야한다는 강박이 있었는데 ... 지금으로썬 공부해가는 과정이니까 그럴 필요가 없는듯 하다 ?! 너무 늦게 깨달았나 싶지만 ... 아니다 지금부터 해야징 후후
이번 포스팅은 quora에서 누군가의 왜 요즘 인공지능이 hype(=excellent, cool)한지 질문한 것에 대한 답변을 공유해보고자 한다.
링크 연결 --> Why is artificial intelligence a hype?
엔비디아에서 딥러닝 솔루션을 구성 및 설계하는 Brent Oster라는 분의 답변이다.
Now, for the past 3 years I have been working on what comes next after DNNs and Deep Learning. I will cover both, showing how it is very difficult to scale DNNs to AGI, and what a better approach would be.
- DNN: Deep Neural Network 심층인공신경망
- AGI: Artificial General Intelligence 일반 인공지능
이 분은 3년동안 DNN, 딥러닝에 대해 연구를 했으며 DNN을 AGI로 scaling(=변수의 값과 범위를 일정한 수준으로 맞추는 작업)을 하는 것이 얼마나 어려운지와 어떤 접근 방식이 더 나은지에 대해 소개하고 있다.
What we usually think of as Artificial Intelligence (AI) today, when we see human-like robots and holograms in our fiction, talking and acting like real people and having human-level or even superhuman intelligence and capabilities, is actually called Artificial General Intelligence (AGI), and it does NOT exist anywhere on earth yet.
보통 인공지능하면 온갖 영화에서 살아있는 인간처럼 말하고 행동하는 로봇이나 홀로그램을 떠올리겠지만, 사실상 그 정도 수준으로 갈려면 아직 멀었다. 현재의 인공지능이라고 하면 narrow Deep Learning (DL) that can only do some very specific tasks better than people 정도라고 보면 된다.
so if that is our goal, we need to innovate and come up with better networks and better methods for shaping them into an artificial intelligence.
"그러나 becoming AGI !!!가 목표라면, 계속 연구에 정진하며 딥러닝 신경망들을 발전시켜나가야 하겠죠 ???"
간단한 개념 설명을 해보고자 한다.
Machine Learning - Fitting functions to data, and using the functions to group it or predict things about future data. (Sorry, greatly oversimplified)
머신러닝은 데이터에 적합하게 모델을 학습시킨 후, 모델을 활용하여 미래 데이터를 예측하는 것을 말합니다.
Deep Learning - Fitting functions to data as above, where those functions are layers of nodes that are connected (densely or otherwise) to the nodes before and after them, and the parameters being fitted are the weights of those connections.
Deep Learning is what what usually gets called AI today, but is really just very elaborate pattern recognition and statistical modelling. The most common techniques / algorithms are Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Reinforcement Learning (RL).
흔히 AI라고 불리는 딥러닝은, 노드로 연결된 층들이 쌓여가면서 학습이 되는 것을 말합니다. 일반적으로 쓰이는 것으로는 합성곱 신경망(CNN), 순환신경망(RNN), 강화학습(RL)이 있습니다.
Convolutional Neural Networks (CNNs) have a hierarchical structure (which is usually 2D for images), where an image is sampled by (trained) convolution filters into a lower resolution map that represents the value of the convolution operation at each point. In images it goes from high-res pixels, to fine features (edges, circles,….) to coarse features (noses, eyes, lips, … on faces), then to the fully connected layers that can identify what is in the image.
계층적인 구조로 이루어져 있는 합성곱 신경망은 이미지를 인식할 때 가중치 파라미터에 해당하는 필터를 찾도록 학습합니다. 필터와 유사한 이미지의 영역을 강조하는 특성맵(feature map)을 출력하여 다음 층(layer)으로 전달합니다. 출력층은 풀링층의 모든 유닛과 연결된 완전연결층(fully-connected layer)을 형성하여 이미지를 인식합니다.
텐서플로우 튜토리얼 링크
CNN 모델이 더 궁금하시다면 위 링크를 참고하여 실제로 사용해보셔도 좋습니다!- 이 튜토리얼은 keras Sequential API를 사용하기 때문에 아래와 같이 간단한 코드만으로도 모델을 만들고 학습시킬 수 있습니다.
model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu'))
Recurrent Neural Networks (RNNs) work well for short sequential or time series data. Basically each 'neural' node in an RNN is kind of a memory gate, often an LSTM or Long Short Term Memory cell. RNNs are good for time sequential operations like language processing or translation, as well as signal processing, Text To Speech, Speech To Text,…and so on.
순환신경망은 시계열 데이터와 같이 시간의 흐름에 따라 변화하는 데이터를 학습하기 위한 인공신경망입니다. RNN은 layer가 많아지는 경우, 학습의 어려움이 있어 이를 극복하기 위해 사용하는 LSTM(Long Short Term Memory)도 해당합니다. 자연어처리, 기계번역, 신호처리, 음성인식, 텍스트 인식 등에 활용할 수 있습니다.
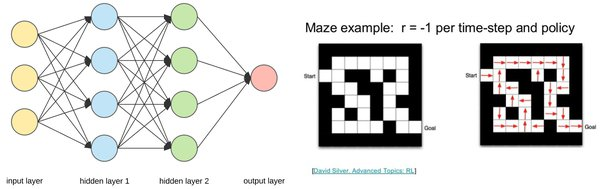
Reinforcement Learning is a third main ML method, where you train a learning agent to solve a complex problem by simply taking the best actions given a state, with the probability of taking each action at each state defined by a policy. An example is running a maze, where the position of each cell is the ‘state’, the 4 possible directions to move are the actions, and the probability of moving each direction, at each cell (state) forms the policy.
강화학습은 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태(state)를 관찰하여 선택할 수 있는 행동(action)들 중에서 가장 최대의 보상을 가져다주는 정책(policy)이 무엇인지를 학습하는 것입니다. 여기서 정책이란 현재 상태와 보상을 입력받았을 때 다음 행동을 결정하는 것인데, 예시로 미로를 달릴 때 어떤 방향으로 갈지에 대한 확률을 말합니다.
But all these methods just find a statistical fit of a simplistic model to data. DNNs find a narrow fit of outputs to inputs that does not usually extrapolate outside the training data set. Reinforcement learning finds a pattern that works for the specific problem (as we all did vs 1980s Atari games), but not beyond it. With today's ML and deep learning, the problem is there is no true perception, memory, prediction, cognition, or complex planning involved. There is no actual intelligence in today's AI.
그러나 이 모델들은 모두 단순한 모델에 적합하도록 통계적으로 접근하였습니다. 심층인공신경망(DNN)은 훈련 데이터가 아닌 외부 데이터에 외삽하기가 어렵습니다. 강화학습은 특정 문제를 해결하는데만 사용할 수 있는 패턴을 발견합니다. 오늘날의 ML과 딥 러닝으로는 인식, 기억, 예측, 인지 또는 복잡한 계획이 불가능합니다. 아직까지는 AI에 실제 지능이 없습니다.
Here is a video of how deep learning could be overtaken by methods based on more flexible spiking neural networks (flexible analog neural computers), shaped by genetic algorithms, architected into an AGI, and evolved over the next decade into a superintelligence.
아래 영상은 생물학적 신경망을 모방한 스파이킹 신경망(SNN)을 기반으로 하는 방법으로 딥 러닝을 넘어서 유전 알고리즘과 AGI로 설계하여 향후 10년 동안 초지능으로 진화하는 방법에 대한 비디오입니다.
Artificial General Intelligence Eta -> 한번씩 보셔도 좋습니다.
And that is how you design a core AGI that can do speech, vision, and motion control. Each function will use similar systems derived from the core design, but will be trained and evolved to function optimally for their purpose.
이후에는 쭉 ORBAI: Artificial General Intelligence에서 구현해낸 일반인공지능(AGI)에 대해 설명해주고 있다.
그러니 나머지는 알아서 한번씩 꼭 읽어보시기를 권한다 😘
