인공지능, 머신러닝, 딥러닝이란?
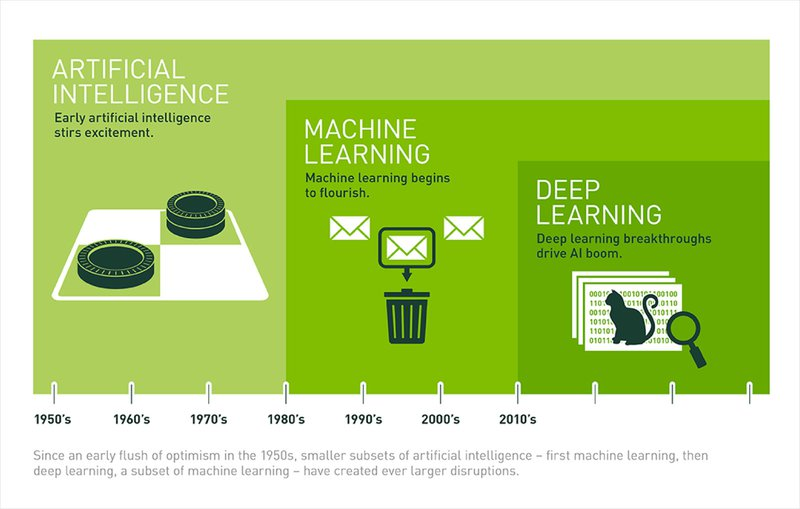
출처: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
위 사진에서 알 수 있듯이, 인공지능이 가장 큰 개념이고 그 아래에 머신러닝, 그리고 딥러닝이 있다.
- 인공지능(AI; Aritificial Intelligence): 사람이 직접 프로그래밍 한 내용이 아니라 기계가 자체 규칙 시스템을 구축하는 과학을 말한다.
- 머신러닝(Machine Learning): 데이터를 통해 스스로 학습하는 방법론(알고리즘)을 말한다. 데이터를 분석하고, 데이터 안에 있는 패턴을 학습하며, 학습한 내용을 토대로 판단이나 예측을 한다.
- 딥러닝(Deep Learning): 머신러닝의 하위 개념으로 학습하는 모델의 형태가 신경망인 방법론을 말한다. 즉, 딥 러닝은 인공신경망에서 발전한 형태의 인공 지능으로, 뇌의 뉴런과 유사한 정보 입출력 계층을 활용하여 데이터를 학습한다.
참고: 웬디의 기묘한 이야기
딥러닝에 대해 조금 더 알아보자
딥러닝은 이미지를 분류하는 대회인 ILSVRC에서 2012년 CNN을 활용한 신경망 모델이 우승한 이후 갑자기 엄청난 유명세와 인기를 얻었다. 또한, 병렬 연산에 최적화된 GPU의 등장은 신경망의 연산 속도를 획기적으로 가속하며 진정한 딥 러닝 기반 인공 지능이 등장했다.
그런데 애초에 딥러닝이 왜 생겨났으며, 머신러닝이 있음에도 불구하고 사용되는 이유가 뭘까?
딥러닝은 분류에 사용할 데이터를 스스로 학습할 수 있는 반면 머신 러닝은 학습 데이터를 수동으로 제공해야 한다. 머신러닝에서 발전된 형태이므로 사람이 학습할 데이터를 입력하지 않아도 스스로 학습하고 예측한다. 즉, 딥러닝을 하면 특성(feature)는 스스로 학습되기 때문에 객체의 어떤 특성을 사용할 것인지를 결정할 필요가 없어진다.
 딥러닝의 대가 중 한 명이라고 불리는 조슈아 벤지오(Yoshua Bengio)는 "Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions." 이렇게 정의하고 있다.
딥러닝의 대가 중 한 명이라고 불리는 조슈아 벤지오(Yoshua Bengio)는 "Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions." 이렇게 정의하고 있다.
= 뇌의 신경 구조로부터 영감을 받아 신경망 형태로 설계된 딥러닝의 목표는, "합성된 함수를 학습시켜서 풍부하면서도 유용한 '내재적 표현'을 찾아내는 machine을 구축하는 것"이다.
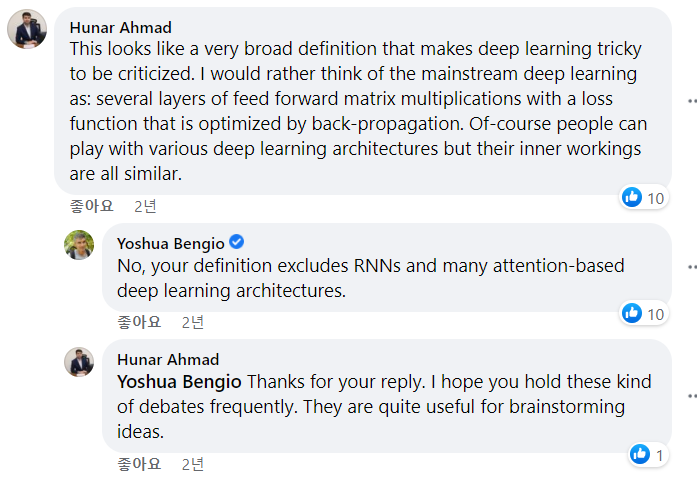 그 밑에 달린 댓글 중 Hunar Ahmad라는 사람은 "이러한 정의는 비판을 피하기 위한 아주 일반적인 정의로밖에 보이지 않는다. 나는 딥러닝을 그저 'several layers of feed forward matrix multiplications with a loss function that is optimized by back-propagation (손실함수와 역전파로 최적화시키는 순방향 행렬 연산)' 일 뿐이라고 생각한다." 라고 반박하였다.
그 밑에 달린 댓글 중 Hunar Ahmad라는 사람은 "이러한 정의는 비판을 피하기 위한 아주 일반적인 정의로밖에 보이지 않는다. 나는 딥러닝을 그저 'several layers of feed forward matrix multiplications with a loss function that is optimized by back-propagation (손실함수와 역전파로 최적화시키는 순방향 행렬 연산)' 일 뿐이라고 생각한다." 라고 반박하였다.
이에 대한 조슈아 벤지오의 답변은?
해당 정의는 딥러닝의 하위 방법론 중 하나인 RNN과 attention-based 를 배제한다고 답했다. 두 가지 모두 단순한 '순방향 행렬 연산'만으로 이루어지지는 않으며, 그 성능을 인정받아 활발하게 응용되고 있는 방법론들이다.
딥러닝의 궁극적인 목표
딥러닝의 목표는 학습된 함수를 사용하여 유용한 internal representations, 즉 내재적 표현을 뽑아내는 것이라고 한다. '표'나 '카테고리'와 같은 추상적이고 내재적인 표현들을 사람의 개입 없이 딥러닝만으로 나타낼 수 있는 모델을 학습시키는 것이 궁극적인 목표라고 할 수 있다.
아래 이미지는 이미지 처리에 많이 쓰이는 VGG16이라는 모델이 이미지를 입력받아 처리하는 과정을 나타낸 그림이다.
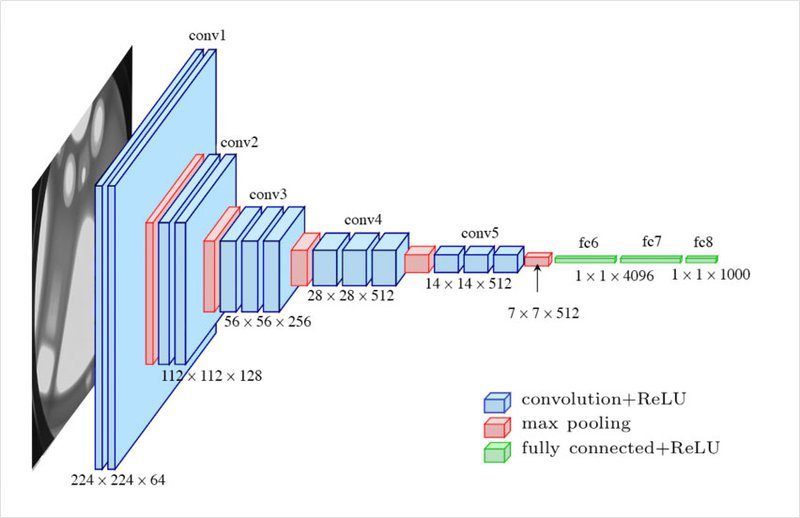 VGG16 모델은 얇은 이미지 한 장을 입력받으면 내부 연산을 거치면서 데이터를 각기 다른 크기의 3차원 배열 형태로 표현하다가, 최종적으로 (1x1x1000)과 같이 1,000개의 숫자로 이루어진 1차원 형태의 벡터를 출력한다. 만약 입력되는 이미지의 크기가 (224x224x3)이었다면 약 15만 개의 숫자로 데이터가 표현된다. 이를 잘 학습된 딥러닝 네트워크에 먹이면 단 1,000개의 숫자만으로 그 이미지의 내재된 특성들을 모두 표현할 수 있게 되는 것이다.
VGG16 모델은 얇은 이미지 한 장을 입력받으면 내부 연산을 거치면서 데이터를 각기 다른 크기의 3차원 배열 형태로 표현하다가, 최종적으로 (1x1x1000)과 같이 1,000개의 숫자로 이루어진 1차원 형태의 벡터를 출력한다. 만약 입력되는 이미지의 크기가 (224x224x3)이었다면 약 15만 개의 숫자로 데이터가 표현된다. 이를 잘 학습된 딥러닝 네트워크에 먹이면 단 1,000개의 숫자만으로 그 이미지의 내재된 특성들을 모두 표현할 수 있게 되는 것이다.
정리하자면, 이러한 맥락에 의해 딥러닝을 'Representation Learning'이라고 칭하기도 한다. 데이터의 표현을 학습한다는 것, 특히 사람이 가공하지 않은, 이미지나 자연어 같은 '날 것의' 데이터를 입력하면 알아서 그 안에 내재된 표현을 추출한다는 것, 이것이 바로 딥러닝이 추구하는 목표의 본질이다.
딥러닝이 사용하는 신경망 모델의 본질
 딥러닝은 연결주의 모형에 따라, 블랙박스에는 뇌와 닮은 신경망 모형이 들어간다.
딥러닝은 연결주의 모형에 따라, 블랙박스에는 뇌와 닮은 신경망 모형이 들어간다.
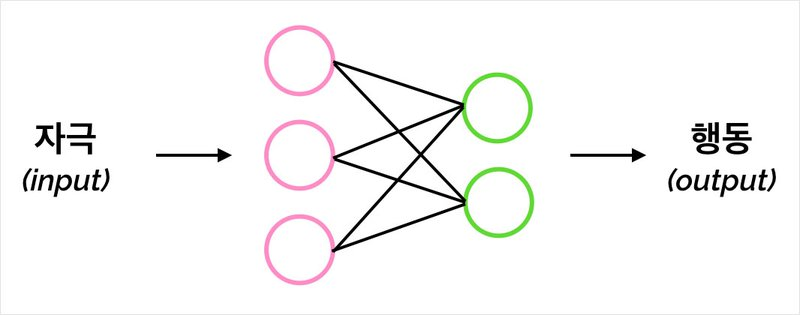 신경망을 다른 이름으로 말하자면 함수이다. f는 입력을 받은 후 내부에서 일련의 연산 과정을 거쳐 출력을 내는 거대한 함수이다.
신경망을 다른 이름으로 말하자면 함수이다. f는 입력을 받은 후 내부에서 일련의 연산 과정을 거쳐 출력을 내는 거대한 함수이다.

