추천 유튜브 채널
선형 변환(Linear Transformation) 개념에 대해 시각적이고 직관적으로 잘 다뤄주는 내가 좋아하는 채널: 3Blue1Brown
머신러닝이란 무엇인가
아이의 학습과정과 매우 유사한 머신러닝. 나무의 개념을 아직 이해하지 못한 아이가 있다고 가정해보자.
아이는 사물을 보고 그것이 뭔지 알아가는 과정에서 ‘나무’의 다양한 예시들을 더 많이 접하게 되며, 머릿속에서는 맨 처음 봤던 나무의 예시인 ‘갈색의 딱딱하고… 매달려 있는 대상’만이 존재하였던 상태에서, 나무의 예시들을 확장적으로 받아들이면서 동시에 ‘나무’라는 대상의 핵심이 되는 특질을 서서히 압축해 나간다. 즉, 나무의 핵심 특질이 압축된 결과물이 여러분의 머릿속에서 추상적인 형태로 자리잡아 나가며 데이터에 기반한 학습을 행하는 것이다.
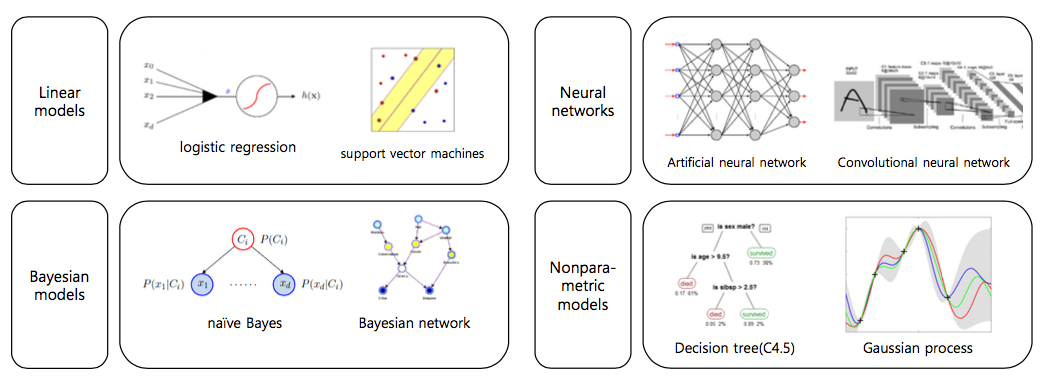
딥러닝이란 무엇인가
딥러닝 모델 3가지
완전 연결 신경망(fully-connected neural network): 다층 퍼셉트론의 일반적 구조에서와 같이 노드 간에 횡적/종적으로 2차원적 연결을 이루는 것.
컨볼루션 신경망(CNN: convolutional neural network): 이 모델에서 필터는 원본 입력층 상에서 일정 간격만큼 횡적/종적으로 이동하면서 가중합 및 활성함수 연산을 수행하고, 그 출력값을 현재 필터의 위치에 놓는다. 이러한 연산 방식은 컴퓨터 비전(computer vision) 분야에서 이미지에 대한 컨볼루션(convolution) 연산과 유사하여, 이러한 구조를 채택하는 심층 신경망을 특별히 컨볼루션 신경망이라고 부른다. 컨볼루션 연산 결과 생성되는 은닉층은 컨볼루션 층(convolutional layer)이며, 복수 개의 컨볼루션 층이 존재하면 심층 컨볼루션 신경망(DCNN: Deep convolutional neural network)이라고 부른다.
-> 이미지 등의 데이터에 대하여 효과적으로 적용된다. 특히, 이미지 인식(image recognition) 분아에서 많이 활용된다.
순환 신경망(RNN: recurrent neural network): 입력 데이터 중에서 선후 관계가 중요하게 취급되는 것들이 있다. 대표적으로, DNA 염기 서열에서는 하나의 예시의 길이가 가변적이며, 서두에 어떤 염기가 등장했는지에 따라 나중에 등장할 염기가 무엇이 될지 결정된다. 이와 같은 형태의 데이터를 시퀀스(sequence)라고 부른다.
-> 자연어 처리(natural language processing) 분야에서 특히 많이 적용된다. 사람들이 사용하는 언어를 텍스트 시퀀스 형태의 데이터로 변환하였을 때, 이 또한 길이 가변성과 선후 관계의 특징을 지니기 때문이다.
인상깊은 기사
1. 우리가 이해하지 못한다고 해서 '블랙박스'라는 단어를 갖다 붙여서는 안된다는 주장
https://blog.pabii.co.kr/aint-blackbox/
“블랙박스란 없습니다. 어떻게 계산되는지 모른다는건 자기가 몰라서 그런거에요. Neural net이 결국은 Logit을 여러개 엮어놓은건데, Logit이 학부시절 배우셨을 회귀분석 식이랑 생긴 형태가 같습니다. 곱하기 계산을 따라가기만하면 다 알 수 있는데, 자기들이 잘 모르는걸 감춘다고 블랙박스라는거에요.”
2. AI의 의사결정 과정을 우리가 다 이해할 수 없으므로, 결과 또한 설명할 수 없게 될 수도 있다는 주장. 카프카의 소설을 인용한 것이 매우 인상 깊음.
https://www.joongang.co.kr/article/22394025#home
이는 카프카의 소설 『심판』과 비슷한 상황이다. 은행원 K는 어느 날 영문도 모르고 체포된다. 무죄를 입증하려 백방으로 애쓰지만 관료적인 당국은 접촉조차 되지 않는다. 그는 죄목이 무엇인지도 모른 채 처형당한다. “하지만 나는 죄인이 아닙니다.” K가 말했다. “뭔가 잘못된 겁니다. 누군가가 유죄라는 게 도대체 가능한 일이기나 한가요?” 신부가 대답했다. “맞는 얘기야. 하지만 그게 죄인들이 하는 말이지.”
우리 모두 K가 되는 세상이 올 수도 있다. ‘인공지능이 번성하려면 자신을 스스로 설명해야만 한다.’ 지난주 영국 이코노미스트지에 실린 특집 기사 제목이다. 부제는 이렇다 ‘만일 그렇지 못하다면 누가 이것을 신뢰할 것인가?’
사람의 인지 영역을 넘어선 내부 구조 탓에 AI가 왜 그런 결과를 도출했는지는 개발자도 알 수 없다. 그래서 AI를 Black Box라고 부른다.
그래서 우리에게는 ...
XAI(eXplainable AI, 설명가능 인공지능)이 필요하다.
XAI는 사람이 AI의 동작과 최종결과를 이해하고 올바르게 해석할 수 있고, 결과물이 생성되는 과정을 설명 가능하도록 해주는 기술을 의미한다.
관련 영상: LIME 라이브러리
- Interpretable Machine Learning을 할 수 있도록 도와주는 라이브러리
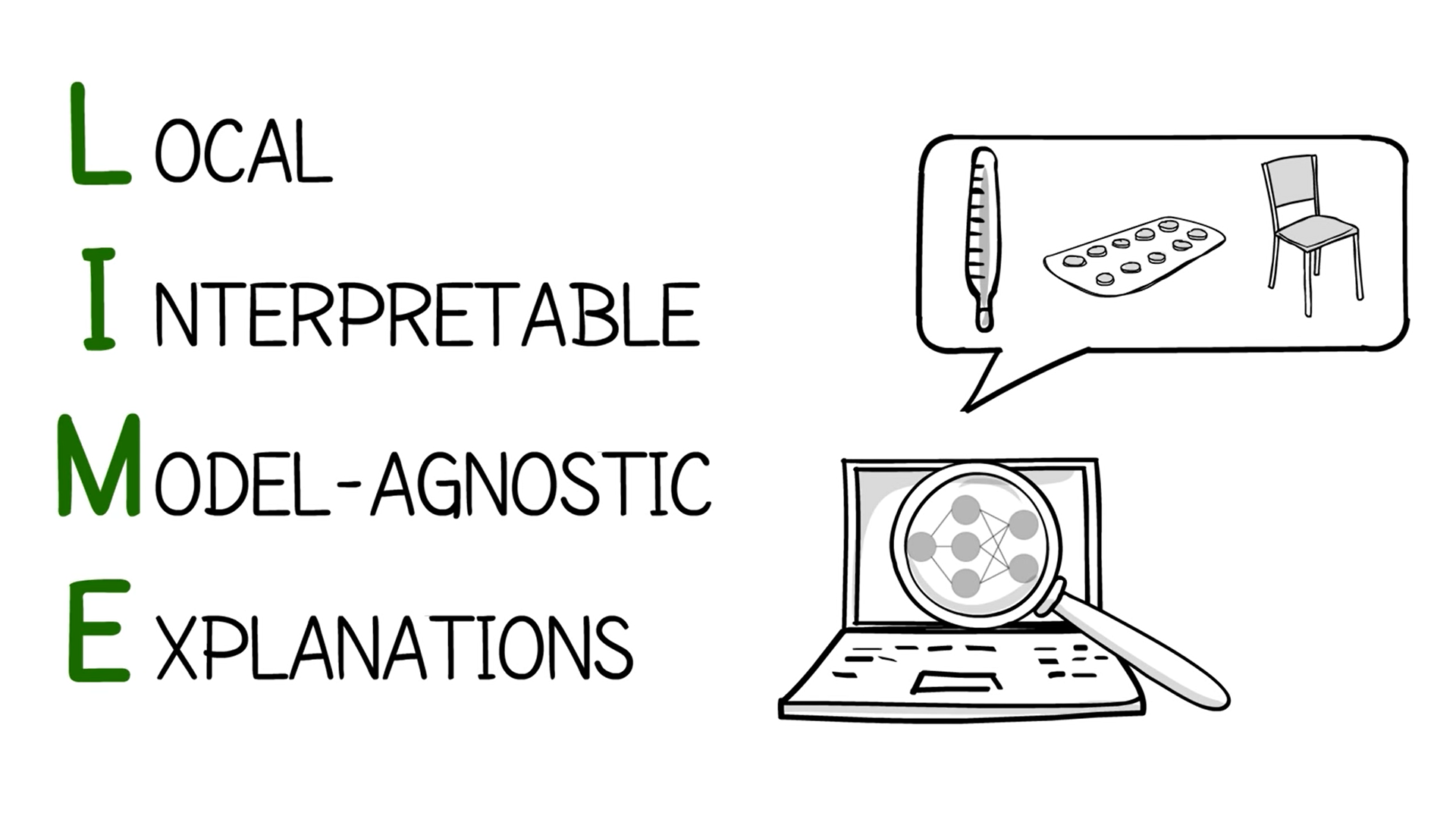 LIME을 사용하면 왜 이런 모델들이 이러한 예측을 하는 것인지 알 수 있다고 한다.
LIME을 사용하면 왜 이런 모델들이 이러한 예측을 하는 것인지 알 수 있다고 한다.
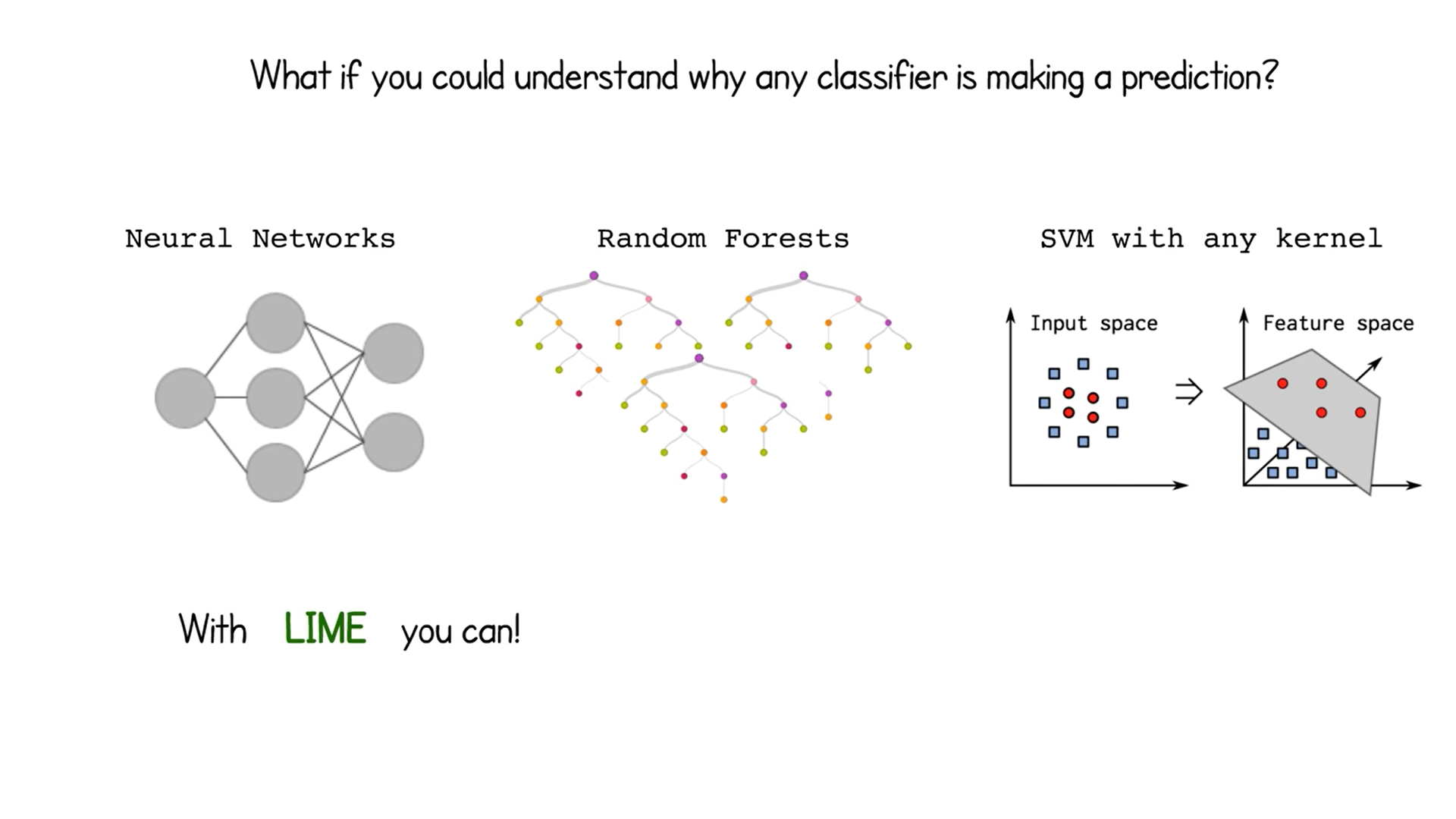 LIME의 핵심 아이디어는 '입력값을 조금 바꿨을 때 모델의 예측값이 크게 바뀌면, 그 변수는 중요한 변수이다.'라는 것이다. 즉, 이미지의 경우 이미지를 잘게 쪼개어 각 부분을 지운 상태로 넣었을 때 출력값이 크게 바뀌는지 아닌지를 확인하여 어떤 부분이 모델이 예측을 만들어 내는 데에 중요하게 작용했는지를 찾아낸다.
LIME의 핵심 아이디어는 '입력값을 조금 바꿨을 때 모델의 예측값이 크게 바뀌면, 그 변수는 중요한 변수이다.'라는 것이다. 즉, 이미지의 경우 이미지를 잘게 쪼개어 각 부분을 지운 상태로 넣었을 때 출력값이 크게 바뀌는지 아닌지를 확인하여 어떤 부분이 모델이 예측을 만들어 내는 데에 중요하게 작용했는지를 찾아낸다.
 궁극적으로 LIME은 딥러닝의 설명하기 어려운 부분을 조금이라도 설명 가능하게끔 해주는 라이브러리다.
궁극적으로 LIME은 딥러닝의 설명하기 어려운 부분을 조금이라도 설명 가능하게끔 해주는 라이브러리다.
여러분들은 어떤 입장에 가까운가?
딥러닝을 블랙박스라고 생각하는지 아닌지 궁금하다.
2020년 6월 초에 OpenAI에서 발표한 모델 GPT-3을 필두로 '강인공지능' 혹은 'Generalized AI'의 시대가 얼마 남지 않았음을 필자는 체감한다.
