비지도학습이란?
지도학습과 달리 training data로 정답(label)이 없는 데이터가 주어지는 학습방법이다.
🪂 군집화(클러스터링, clustering)
라벨링이 되어있지 않은 데이터셋이 많은 경우, 각각 라벨을 달아주는 인간의 수고를 덜기 위해 제시된 비지도학습의 대표적인 방법론인 클러스터링. 라벨링이 되어 있지 않은 데이터들 내에서 비슷한 특징이나 패턴을 가진 데이터들끼리 군집화한 후, 새로운 데이터가 어떤 군집에 속하는지를 추론한다.
비지도학습이라는 용어는 정답이 없는 데이터를 이용한 학습 전체를 포괄하는 용어이기 때문에 클러스터링 외에도 차원 축소(dimensionality reduction) 및 이를 이용한 데이터 시각화, 생성 모델(generative model) 등 다양한 task를 포괄하는 개념이다.
- 클러스터링의 대표적인 알고리즘: K-means와 DBSCAN 알고리즘
- 차원 축소의 대표적인 방법: PCA(Principal Component Analysis), T-SNE
클러스터링(1) K-means
K-means 알고리즘은 k 값이 주어져 있을 때, 주어진 데이터들을 k 개의 클러스터로 묶는 알고리즘으로 대표적인 클러스터링 기법 중 하나이다. 단, 아무렇게나 뭉치진 말고 k개의 기준점을 중심으로 가장 가까운 데이터들을 뭉쳐 보는 방식이다.
🪂 예제 코드들을 통해 K-means 알고리즘의 동작원리를 살펴보자. 🪂
1. 데이터 생성
모듈을 import하고 5개의 중심점을 기준으로 무작위 점 데이터 100개를 생성한다.
%matplotlib inline
from sklearn.datasets import make_blobs
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
# 중심점이 5개인 100개의 점 데이터를 무작위로 생성합니다.
points, labels = make_blobs(n_samples=100, centers=5, n_features=2, random_state=135)
print(points.shape, points[:10]) # 무작위로 생성된 점의 좌표 10개 출력
print(labels.shape, labels[:10]) # 10개의 점들이 각각 대응하는 중심점(label) 값 출력scikit-learn의 make_blob()을 활용하면 중심점이 5개인 무작위의 점 데이터 100개를 생성할 수 있다. 참고로, 비지도학습에는 label이 없다고 했었는데 K-means에서는 임의로 지정한 k개의 중심점이 새로운 label 역할을 한다는 점 주목 !!
# 축 그리기
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 위에서 생성한 점 데이터들을 pandas DataFrame 형태로 변환하기
points_df = pd.DataFrame(points, columns=['X', 'Y'])
display(points_df.head())
# 점 데이터를 X-Y grid에 시각화하기
ax.scatter(points[:, 0], points[:, 1], c='black', label='random generated data')
# 축 이름을 라벨에 달고, 점 데이터 그리기
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()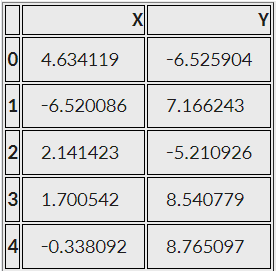
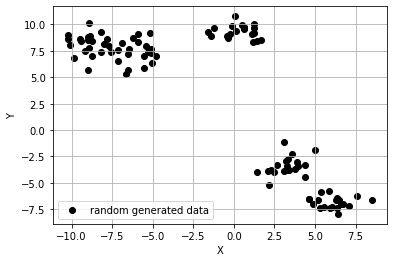 이렇게 생성한 데이터를 좌표에 그려보았다. 한눈에 보기에도 위의 데이터들은 5개의 군집을 이루고 있는 것처럼 보인다. 과연 k-means 알고리즘을 적용하여 위 데이터들을 올바르게 군집화할 수 있을까?
이렇게 생성한 데이터를 좌표에 그려보았다. 한눈에 보기에도 위의 데이터들은 5개의 군집을 이루고 있는 것처럼 보인다. 과연 k-means 알고리즘을 적용하여 위 데이터들을 올바르게 군집화할 수 있을까?
2. 생성한 데이터에 K-means 알고리즘 적용
데이터를 X-Y 좌표축 위에 생성되어 있기 때문에 데이터들 사이의 거리는 쉽게 계산해낼 수 있다. 피타고라스 정리를 응용하여 좌표축 사이의 두 점 사이의 직선거리를 계산할 수 있는데 이를 유클리드 거리(Eucledian distance) 또는 L2 Distance라고 부른다.
🪂 자세한 설명은 '유클리디안 거리' 여기에 나와있다.
K-means 알고리즘 순서
- 원하는 클러스터의 수(K)를 결정한다.
- 무작위로 클러스터의 수와 같은 K개의 중심점(centroid)을 선정한다.
🔶 이들은 각각의 클러스터를 대표함. - 나머지 점들과 모든 중심점 간의 유클리드 거리를 계산한 후, 가장 가까운 거리를 가지는 중심점의 클러스터에 속하도록 한다.
- 각 K개의 클러스터의 중심점을 재조정한다. 특정 클러스터에 속하는 모든 점들의 평균값이 해당 클러스터 다음 iteration의 중심점이 된다.
🔶 이 중심점은 실제로 존재하는 데이터가 아니어도 상관없음. - 재조정된 중심점을 바탕으로 모든 점들과 새로 조정된 중심점 간의 유클리드 거리를 다시 계산한 후, 가장 가까운 거리를 가지는 클러스터에 해당 점을 재배정한다.
- 4.번과 5.번을 반복 수행한다. 반복의 횟수는 사용자가 적절히 조절하면 되고, 특정 iteration 이상이 되면 수렴(중심점이 더 이상 바뀌지 않음)하게 된다.
from sklearn.cluster import KMeans
# 1), 2) 위에서 생성한 무작위 점 데이터(points)에 클러스터의 수(K)가 5인 K-means 알고리즘을 적용
kmeans_cluster = KMeans(n_clusters=5)
# 3) ~ 6) 과정이 전부 함축되어 있는 코드. points에 대하여 K가 5일 때의 K-means iteration을 수행
kmeans_cluster.fit(points)
print(type(kmeans_cluster.labels_))
print(np.shape(kmeans_cluster.labels_))
print(np.unique(kmeans_cluster.labels_))<class 'numpy.ndarray'>
shape: (100,)
labels: [0 1 2 3 4]
K-means 결과 시각화하기
: 중심점 5개인 무작위 데이터를 생성하고 나서, 이를 K-means 알고리즘을 활용해 5개의 군집으로 분류한 결과
# n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정하는 color dictionary
color_dict = {0: 'red', 1: 'blue', 2:'green', 3:'brown', 4:'indigo'}
# 점 데이터를 X-Y grid에 시각화합니다.
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# K-means clustering의 결과대로 색깔별로 구분하여 점에 색칠한 후 도식
for cluster in range(5):
cluster_sub_points = points[kmeans_cluster.labels_ == cluster] # 전체 무작위 점 데이터에서 K-means 알고리즘에 의해 군집화된 sub data를 분리합니다.
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster)) # 해당 sub data를 plot합니다.
# 축 이름을 라벨에 달고, 점 데이터 그리기
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()처음에 예상했던 것처럼 5개의 그룹이 잘 분리된 것으로 보아 K-means 알고리즘은 군집의 수만 주어진다면, 데이터의 군집화를 매우 잘 수행한다.
🪂 그러나, K-means 알고리즘이 만능은 아니라는 점!
주어진 데이터의 분포에 따라 우리가 의도하지 않은 결과를 초래하기도 하는데 ... 3가지 예시를 살펴보자.
1. '가운데 작은 원'과 '바깥쪽 큰 원' 두 개의 군집으로 분류 실패
: K-means 알고리즘은 이 데이터들을 마치 케잌을 칼로 자르듯이 반으로 나눴다.
# K-means algorithm이 잘 동작하지 않는 예시 (1) 원형 분포
from sklearn.datasets import make_circles
# 원형 분포 데이터 생성
circle_points, circle_labels = make_circles(n_samples=100, factor=0.5, noise=0.01) # 원형 분포를 가지는 점 데이터 100개를 생성합니다.
# 캔버스 생성
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 원형 분포에 대해 K-means 수행
circle_kmeans = KMeans(n_clusters=2)
circle_kmeans.fit(circle_points)
color_dict = {0: 'red', 1: 'blue'}
for cluster in range(2):
cluster_sub_points = circle_points[circle_kmeans.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('K-means on circle data, K=2')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()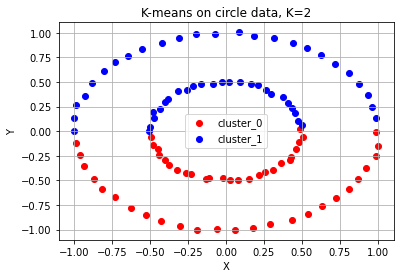
2. 두 개의 초승달 형태를 분리해서 군집화 실패
: 중간에 칼로 자른 형태로 나누어져 있다.
# K-means algorithm이 잘 동작하지 않는 예시 (2) 달 모양 분포
from sklearn.datasets import make_moons
# 달 모양 분포의 데이터 생성
moon_points, moon_labels = make_moons(n_samples=100, noise=0.01) # 달 모양 분포를 가지는 점 데이터 100개를 생성합니다.
# 캔버스 생성
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 달 모양 분포 데이터 plot
moon_kmeans = KMeans(n_clusters=2)
moon_kmeans.fit(moon_points)
color_dict = {0: 'red', 1: 'blue'}
for cluster in range(2):
cluster_sub_points = moon_points[moon_kmeans.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('K-means on moon-shaped data, K=2')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()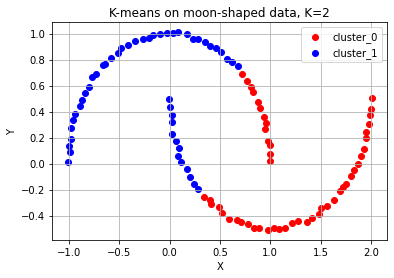
3. 크게 3개의 대각선 방향으로 나열되어 있는 데이터 예상대로 군집화 실패
# K-means algorithm이 잘 동작하지 않는 예시 (3) 대각선 모양 분포
from sklearn.datasets import make_circles, make_moons, make_blobs
# 대각선 모양 분포의 데이터 생성
diag_points, _ = make_blobs(n_samples=100, random_state=170) #대각선 분포를 가지는 점 데이터 100개를 생성합니다.(현재는 무작위 분포)
transformation = [[0.6, -0.6], [-0.4, 0.8]] #대각선 변환을 위한 대각 행렬
diag_points = np.dot(diag_points, transformation) #본 과정을 통해 무작위 분포의 점 데이터를 대각선 분포로 변환합니다.
# 캔버스 생성
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 대각선 모양 분포 데이터 plot
diag_kmeans = KMeans(n_clusters=3)
diag_kmeans.fit(diag_points)
color_dict = {0: 'red', 1: 'blue', 2: 'green'}
for cluster in range(3):
cluster_sub_points = diag_points[diag_kmeans.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('K-means on diagonal-shaped data, K=2')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()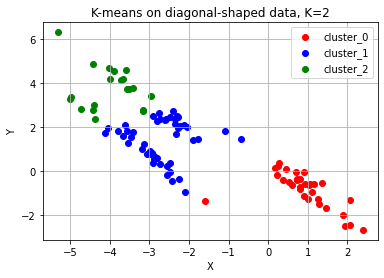
🪂 결론적으로, K-means 알고리즘은......
- 군집의 개수(K 값)를 미리 지정해야 하기 때문에 이를 알거나 예측하기 어려운 경우에는 사용하기 어렵다.
- 유클리드 거리가 가까운 데이터끼리 군집이 형성되기 때문에 데이터의 분포에 따라 유클리드 거리가 멀면서 밀접하게 연관되어 있는 데이터들의 군집화를 성공적으로 수행하지 못할 수 있다.
다음 포스팅은 이 경우처럼 군집의 개수를 명시하지 않으면서, 밀도 기반으로 군집을 예측하는 방법에 대한 것입니다.
