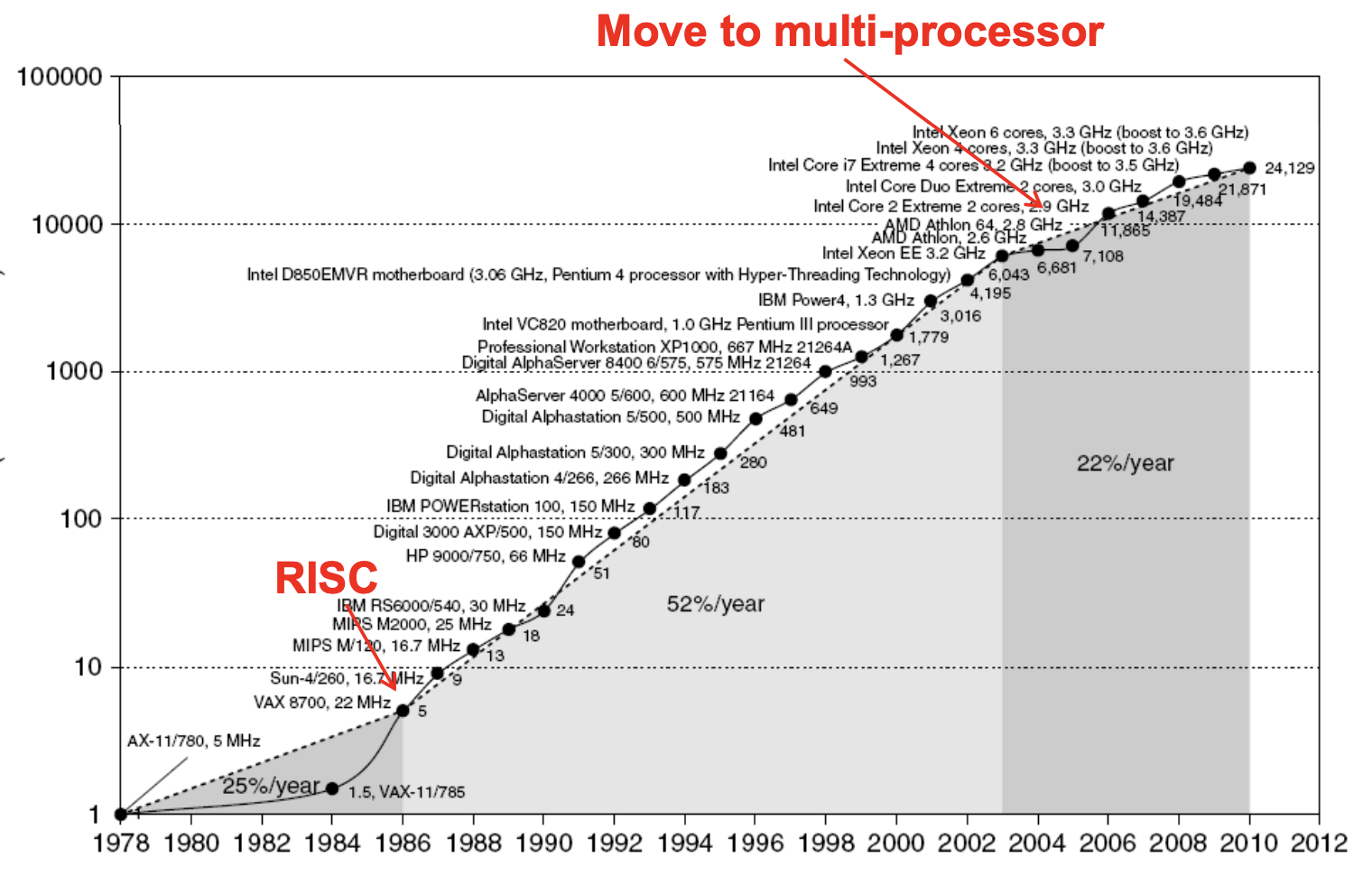
1. What drove performance? (성능 향상의 원동력)
무어의 법칙(Moore's Law)에 따라 트랜지스터 수가 늘어나는 동안, 아키텍처는 다음 기술들로 성능을 높여왔습니다.
A. RISC for Pipeline: 명령어를 단순화하여 파이프라인 효율을 극대화 (CPI를 낮춤).
B. Cache: CPU와 메모리 속도 차이(Memory Wall) 극복.
C. ILP (Instruction Level Parallelism): 명령어 여러 개를 동시에 실행 (Pipelining, Superscalar, OoO).
-
Power Density 문제 발생: 칩 집적도가 높아지면서 단위 면적당 발열이 감당 불가능해짐.
-
결과: "CPU Frequency를 낮춰야 한다" → 클럭 속도 경쟁(Frequency scaling)이 끝나고 멀티코어 시대로 전환.
D. TLP (Thread Level Parallelism): 싱글 코어 성능 향상이 한계에 부딪히자, 코어 수(Core)를 늘려 스레드를 병렬 처리.
E. Domain Specific Architecture (DSA): 범용 CPU의 한계 극복.
- Heterogeneous Design: CPU + GPU + NPU 등 서로 다른 프로세서를 섞어 쓰는 이기종 컴퓨팅. (반대말: Homogeneous - 똑같은 코어만 쓰는 것)
2. Classes of Computers (컴퓨터의 분류)
각 분야마다 최적화 목표(Design Goal)가 다릅니다.
-
PMD (Personal Mobile Device): 스마트폰 등. Energy efficiency(배터리 수명)와 Real-time(터치 반응 속도)이 중요.
-
Desktop: 가격 대비 성능(Price-performance) 중시.
-
Servers:
- Availability: 24시간 꺼지면 안 됨 (가용성).
- Scalability: 사용자가 늘면 서버만 추가해서 성능 확장이 가능해야 함 (확장성).
- Throughput: 단위 시간당 얼마나 많은 요청을 처리하느냐 (처리량). -
WSC (Warehouse Scale Computers): 구글/아마존 데이터센터. 전력 비용(Power)과 가용성(Availability)이 핵심.
-
Embedded: 최소 비용(Min price)으로 요구 성능만 딱 맞추는 것이 목표.
Parallelism
• Classes of parallelism in applications:
– Data-Level Parallelism (DLP)
– Task-Level Parallelism (TLP)
• Classes of architectural parallelism:
– Instruction-Level Parallelism (ILP)
– Vector architectures/Graphic Processor Units
(GPUs)
– Thread-Level Parallelism
– Request-Level Parallelism
3. Flynn's Taxonomy (플린의 분류법)
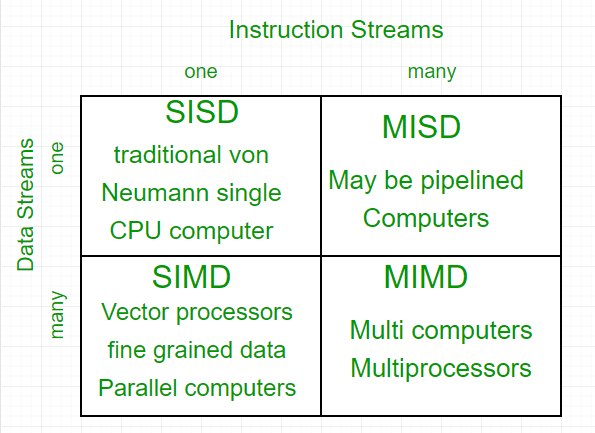
컴퓨터 구조를 명령어(Instruction)와 데이터(Data) 흐름의 개수에 따라 4가지로 나눈 아주 유명한 분류법입니다.
A. SISD (Single Instruction, Single Data): 전통적인 단일 코어 PC.
B. SIMD (Single Instruction, Multiple Data): GPU의 핵심 원리.
- 명령어 ADD 하나를 던지면, 16개의 데이터(R1[0]~R1[15])가 동시에 덧셈을 수행.
ADD R1[16],R2[16],R3[16]
it's vector, you'll do same job 16 times
same opperation with different number
Vector architectures
– Graphics processor unitsC. MISD: 실제로는 거의 안 쓰임 (우주선 등 특수 목적).
D. MIMD (Multiple Instruction, Multiple Data): 멀티 코어 CPU, 클러스터 컴퓨터.
-
CMP (Chip Multi-Processor): 칩 하나에 여러 코어 (우리가 쓰는 멀티코어 CPU).
-
SMT (Simultaneous Multi-Threading): 인텔의 'Hyper-Threading'. 물리적 코어는 1개인데 논리적으로 2개인 척 스레드를 동시에 돌림.
4. Computer Hierarchy & Bandwidth
Micro-RISC: 인텔 x86은 껍데기는 CISC지만, 내부 하드웨어는 복잡한 명령어를 잘게 쪼개서(u-op) RISC처럼 실행합니다.
Bandwidth vs Latency:
-
Bandwidth (대역폭): 고속도로 차선 수. 기술 발전에 따라 매우 빠르게 좋아짐.
-
Latency (지연 시간): 서울에서 부산까지 걸리는 시간. 물리적 한계로 더디게 좋아짐. (이 차이 때문에 캐시가 필수)
intel x86: cisc
- but they changed to micro risc
Arm: risc for mobile device
5. Power and Energy (⭐⭐⭐)
이 부분 수식이 꼬이면 시험 때 고생합니다. 정확히 정리해 드릴게요.
1) 수식 정리 (Dynamic Power)
CMOS 회로의 전력 소모 공식
: Power (전력, Watt): Capacitive Load (용량성 부하)
: Voltage (전압)
: Frequency (클럭 주파수)
2)"Power를 낮추려면 v나 f를 낮춰야 함"
가 제곱()으로 비례하므로 전압을 낮추는 게 효과가 제일 큽니다.
Threshold Voltage () 한계:
설명: 전압()을 낮추면 좋지만, 트랜지스터가 켜지는 최소 전압인 (약 0.7V 근처) 밑으로 내리면 0과 1 구분이 안 되어 누설 전류(Leakage)가 폭발합니다. 그래서 더 이상 전압을 못 낮추고(Dennard Scaling 종료), 결과적으로 클럭()도 못 올리게 된 것입니다.
"Reducing clock rate reduces power, not energy" (이 문장 매우 중요!)
- Power (일률): 초당 쓰는 전기량. 클럭()을 반으로 줄이면 Power도 반으로 줍니다. (발열이 줄어듦)
- Energy (일의 양): . 클럭을 반으로 줄이면 Power는 줄지만, 계산 끝나는 시간()이 2배로 늘어납니다.
- 결국 . 총 소모 에너지는 같습니다. (배터리 수명은 그대로)
- 배터리를 아끼려면 만 줄이는 게 아니라 전압()까지 같이 줄여야(DVFS) 합니다.
3) Thermal Design Power (TDP)
쿨링 시스템(팬, 방열판)을 설계할 때 기준이 되는 전력량입니다. "이 CPU는 최대 이만큼 열이 나니까 이 정도 쿨러를 달아라"라는 뜻입니다.
① Characterizes sustained power consumption (지속적인 전력 소비 특성)
의미: CPU가 1초 동안 낼 수 있는 최대 힘이 아니라, "장시간 무거운 작업을 돌렸을 때(Sustained)" 유지되는 전력 소비량입니다.
비유: 마라톤 선수가 전력 질주(Sprint)를 할 때는 심박수가 200까지 가지만, 2시간 내내 그렇게 뛸 수는 없죠? TDP는 전력 질주가 아니라, "계속 유지할 수 있는 가장 빠른 속도"에서의 열 발생량입니다.
② Used as target for power supply and cooling system (설계 목표치)
Cooling (쿨링): 만약 CPU의 TDP가 125W라면, 당신은 최소한 125W 이상의 열을 식힐 수 있는 쿨러를 장착해야 합니다. 만약 65W짜리 쿨러를 달면? CPU는 열을 식히지 못해 스스로 속도를 늦추는 스로틀링(Throttling)에 걸려 성능이 급격히 떨어집니다.
Power Supply (전원): 파워 서플라이를 고를 때도 이 TDP를 기준으로, 다른 부품들의 전력을 합산하여 용량을 결정합니다.
③ Lower than peak power, higher than average (피크보다는 낮고, 평균보다는 높다)
이 부분이 시험에 나오기 가장 좋은, 헷갈리는 개념입니다.
왜 Peak Power(최대 전력)보다 낮은가? (Turbo Boost의 비밀)
현대 CPU(인텔, AMD)는 작업을 시작하자마자 터보 부스트(Turbo Boost)를 켭니다. 이때는 TDP를 무시하고 순간적으로 Peak Power (예: 200W)까지 전력을 끌어다 씁니다.
"그럼 쿨러가 못 버티지 않나요?"
괜찮습니다. 쿨러의 금속 덩어리(히트싱크)가 달궈지는 데 시간이 걸리기 때문입니다. 약 10~50초 정도의 짧은 시간(Tau) 동안은 TDP를 초과해서 전력을 써도 쿨러가 버텨줍니다.
하지만 쿨러가 완전히 뜨거워지면, CPU는 다시 TDP 수준(예: 125W)으로 전력을 낮춥니다.
결론: TDP는 순간적인 최대치(Peak)가 아니라, 결국 돌아오게 되는 안정화된 수치이므로 Peak보다 낮습니다.
왜 Average Power(평균 전력)보다는 높은가?
우리가 웹 서핑을 하거나 문서를 작성할 때 CPU는 대부분 놀고 있습니다(Idle). 이때는 10W~20W밖에 안 씁니다.
TDP는 "가장 빡빡한 상황(Worst Case)"을 가정한 설계치이므로, 당연히 일상적인 평균 사용량보다는 훨씬 높게 잡혀 있습니다.
클럭 속도(Frequency)를 낮추면 발열(Power)은 줄어드는데, 왜 배터리(Energy)는 못 아끼나
1. 기본 개념 잡기: 에너지(Energy) vs 전력(Power)
먼저 이 두 단어의 차이를 명확히 해야 뒤에 나오는 수식이 이해됩니다.
Energy (에너지, ): 일을 한 총량. (단위: Joule)
비유: 자동차가 서울에서 부산까지 가는 데 쓴 총 기름의 양. (배터리 수명과 직결)
Power (전력, ): 단위 시간당 하는 일의 양. (단위: Watt = Joule/sec)1
비유: 자동차 엔진이 순간적으로 태우는 기름의 속도. (발열과 직결)
2. Dynamic Energy (스위칭 에너지)
트랜지스터가 0에서 1로, 혹은 1에서 0으로 딱 한 번 바뀔 때 드는 에너지입니다.
수식:
변수 설명:
- (Capacitive Load): 전자를 담는 그릇의 크기입니다. (회로가 복잡할수록 큼)
- (Voltage): 전자를 밀어주는 압력입니다.
핵심: 이 공식에는 시간()이 없습니다. 즉, 스위치를 빨리 켜든 천천히 켜든, 한 번 켤 때 드는 에너지 비용은 똑같다는 뜻입니다.
3. Dynamic Power (동적 전력)
이제 스위치를 1초에 몇 번(Frequency) 껐다 켰다 하느냐를 따집니다. 이게 바로 우리가 흔히 말하는 CPU의 소비 전력(Watt)입니다.
수식:
핵심: 여기에 (Frequency)가 붙었습니다.
- 클럭 속도()를 2배로 올리면? → 전력()도 2배가 됩니다. (더 뜨거워짐)
- 클럭 속도()를 반으로 줄이면? → 전력()도 반으로 줍니다. (덜 뜨거워짐)
4. "Reducing clock rate reduces power, not energy" (하이라이트)
교수님이 강조하신 이 문장이 왜 성립하는지 시나리오로 증명해 보겠습니다.
[상황] 어떤 프로그램(Task)을 실행하는 데 총 100번의 클럭 사이클이 필요하다고 가정해 봅시다.
A. 원래 속도로 실행할 때 (Fast)
- 주파수() = 10 Hz (초당 10번)
- 전력() = 10 Watt라고 가정.
- 걸린 시간() = 100번 / 10 Hz = 10초
- 총 에너지() = = 10W 10s = 100 Joule
B. 클럭 속도를 반으로 줄였을 때 (Slow)
- 주파수() = 5 Hz (반으로 줄임)
- 전력() = 수식()에 따라 5 Watt로 줄어듦. (와! 발열이 반으로 줄었다!)
- 걸린 시간() = 100번 / 5 Hz = 20초 (작업 시간이 2배로 늘어남)
- 총 에너지() = = 5W 20s = 100 Joule
결론:클럭()을 낮추면 순간적인 전력(, 발열)은 줄어들지만, 작업 시간이 길어지기 때문에 결국 배터리에서 빼 쓴 총 에너지(, 배터리 소모량)는 똑같습니다.
- 그래서 어떻게 해야 하나요? (DVFS)
배터리(Energy)를 아끼려면 만 줄여서는 안 되고, 수식에서 제곱()으로 영향을 주는 전압()을 줄여야 합니다.
DVFS (Dynamic Voltage and Frequency Scaling):
- 클럭()을 낮출 때, "어차피 천천히 일할 거니까 전압()도 살짝 낮추자"라고 하는 기술입니다.
- 만약 를 반으로 줄이면서 도 낮출 수 있다면, 그때 비로소 Energy도 줄어들게 됩니다.
💡 한 줄 요약"클럭을 낮추는 건 엔진을 천천히 돌려 열을 식히는(Power 감소) 데는 도움이 되지만, 목적지까지 가는 데 드는 총 기름양(Energy)은 줄이지 못한다(시간이 더 걸리니까). 기름을 아끼려면 연비(Voltage) 자체를 개선해야 한다."
연습문제
Some microprocessor today are designed to
have adjustable voltage, so that a 15% reduction
in voltage may result in a 15% reduction in
frequency. What would be the impact on dynamic
power and dynamic energy?
이 문제는 컴퓨터 구조 중간고사나 퀴즈에 정말 자주 나오는 DVFS (Dynamic Voltage and Frequency Scaling) 응용 계산 문제입니다.
방금 전 배운 "클럭만 낮추면 에너지는 그대로"라는 개념과 달리, 이번엔 "전압(Voltage)도 같이 낮췄을 때" 어떤 마법이 일어나는지 수식으로 증명하는 과정입니다.
1. 문제 분석 및 공식 세팅
조건: 전압() 15% 감소, 주파수() 15% 감소.
구해야 할 것:
Dynamic Power (): 얼마나 시원해지는가?
Dynamic Energy (): 배터리를 얼마나 아끼는가?
2. Dynamic Power (동적 전력)의 변화
전력 공식:
여기에 변화된 값을 대입해 봅시다.
계산기를 두드려보면:결론 1:전력(Power)은 기존의 약 61.4% 수준으로 떨어집니다.즉, 약 38.6%나 감소합니다. (발열이 엄청나게 줄어듭니다!)
3. Dynamic Energy (동적 에너지)의 변화
에너지 공식:
(전력 × 시간)
여기서 중요한 점은 시간()이 늘어난다는 것입니다. 주파수()가 15% 느려졌으므로, 작업 시간은 반대로 배 만큼 길어집니다.
이제 에너지 변화를 계산해 봅시다.
수학적으로 보면, 시간 늘어난 것()과 전력에서 주파수 줄어든 것()이 서로 약분되어 사라집니다. 결국 에너지는 전압의 제곱()에만 비례하게 됩니다.
계산기를 두드려보면:
결론 2:에너지(Energy)는 기존의 약 72.3% 수준이 됩니다.즉, 배터리 소모량이 약 27.7% 감소합니다.
Dynamic Power: 전압의 제곱과 주파수에 비례하므로 (), 약 39% 감소한다. (발열 대폭 감소)
Dynamic Energy: 실행 시간이 늘어나 주파수 효과는 상쇄되고 전압의 제곱에만 비례하므로 (), 약 28% 감소한다. (배터리 절약 성공)
핵심 인사이트:
아까 "클럭()만 낮추면 에너지는 못 아낀다"고 했죠? 하지만 전압()을 같이 낮추니까(DVFS) 드디어 에너지가 줄어드는 것을 확인할 수 있습니다. 이것이 현대 모바일 프로세서의 핵심 생존 전략입니다.
power problem
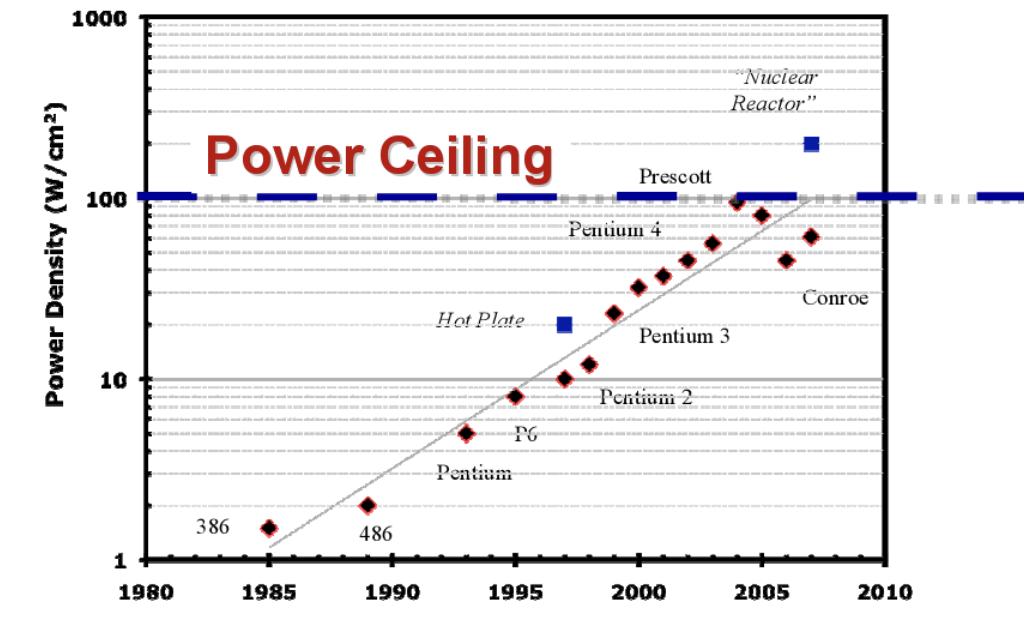
배터리 아끼는 핵심 기술
Do nothing well(아무것도 안 할 거면, 확실하게 꺼라): 찰나의 순간에 클럭 끊기 (Clock Gating)
DVFS: 일감에 맞춰 전압/속도 조절하기
Low power state: 시스템 전체 재우기 (Sleep Mode)
Turning off cores: 안 쓰는 코어 전원 차단 (Power Gating)
Race to Halt: (오버클럭 맥락) 빨리 끝내고 빨리 자는 게 이득일 때가 있다.
